CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
茴香豆
RAG补充
优化方向
- 嵌入优化 ,embedding optimization
- combine sparse
- mutiple task
- 索引优化 indexing optimization
- chunk size
- meta data
- query optimization
- expand or transfer
- multiple query
- 上下文管理 content curation
- rerank
- select or compress
- 迭代检索 iterative retrieval
- 递归检索 recursive retrieval
- devided
- COT
- 自适应检索
- Flare, self rag
- activate learning
- LLM 微调 LLM fineturning
- retrieval FT
- generation FT
- Both FT
RAG vs FT
| RAG | FT | |
|---|---|---|
| 概念 def | 非参数记忆,利用外部知识库实时更新 | 参数记忆,通过特定任务数据集上训练更好适应 |
| 能够处理知识密集型任务,提供准确事实性回答 | 需要大量标注数据微调 | |
| 通过检索增强,生成多样化内容 | 会过拟合,泛化能力下降 | |
| 适用场景 Applicable Scenarios | 适用于需要结合最新信息和试试实时数据任务,开放与问答,时事新闻摘要 | 适用于数据可用且需要模型高度专业化的任务 |
| Advantages | 动态知识更新,处理长尾知识问题 | 模型性能针对特定任务优化 |
| limitation | 依赖于外部知识库的质量和覆盖范围,依赖大模型能力 | 需要大量的标注数据,且对新任务适应性较差 |
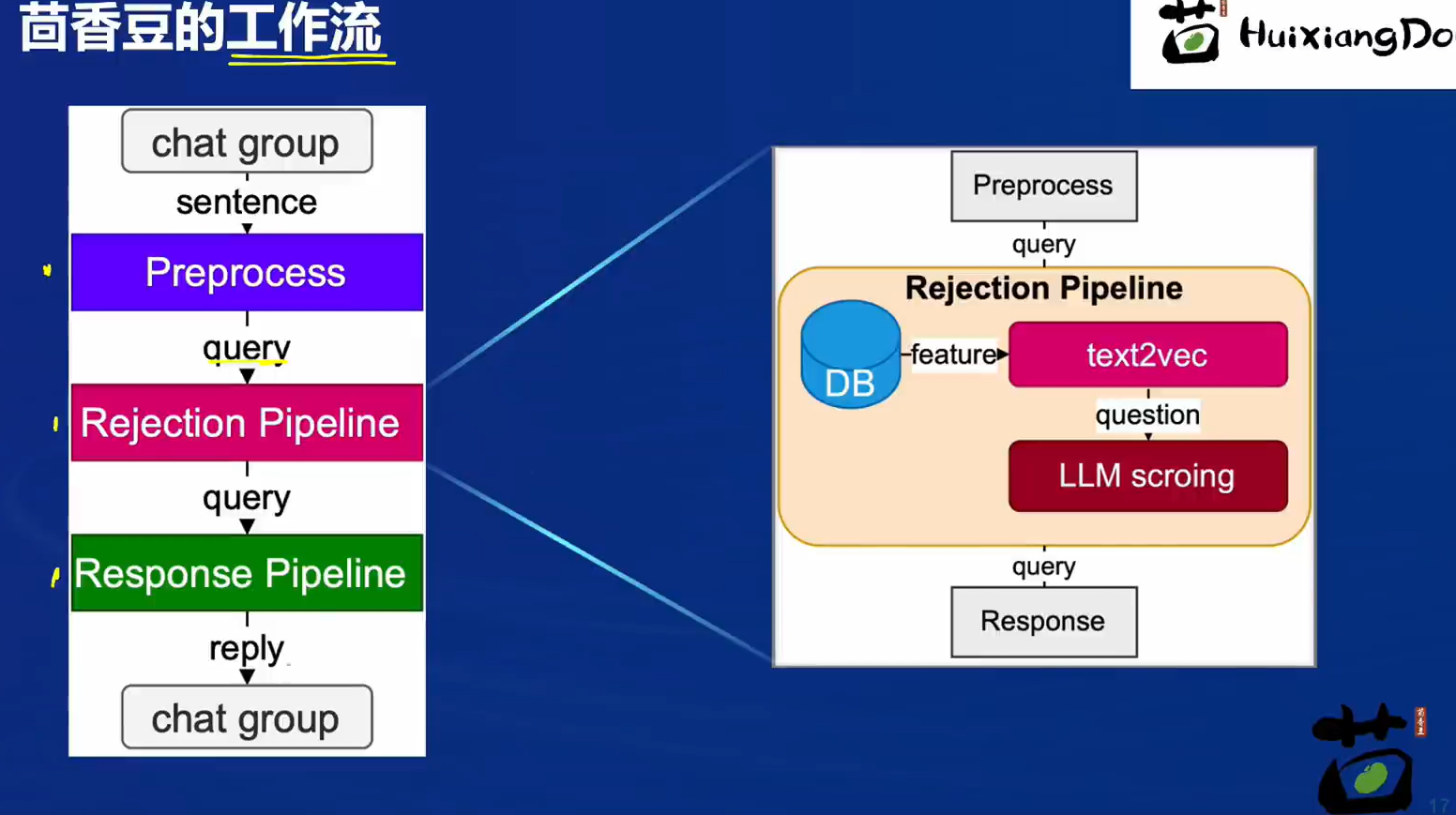
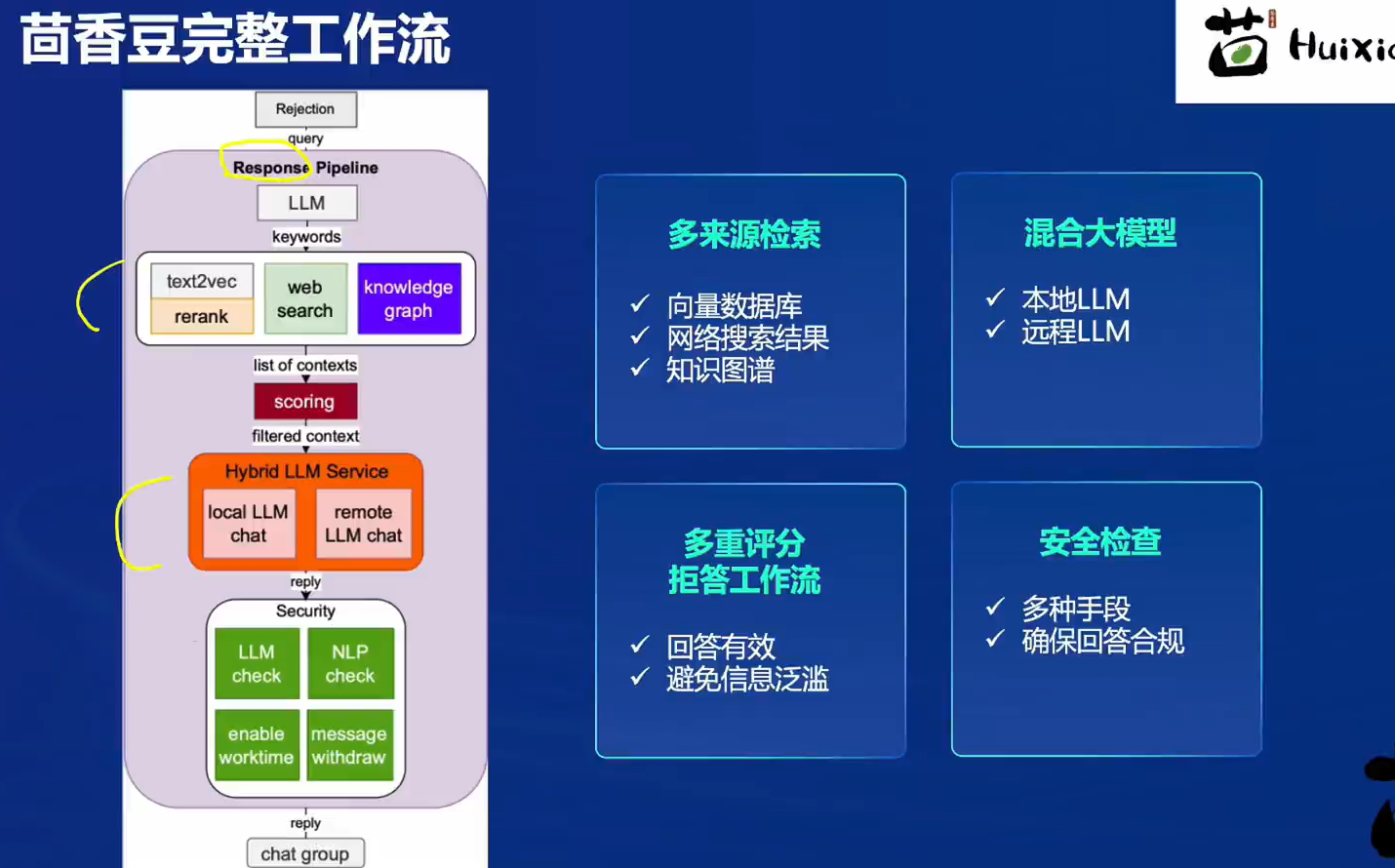
茴香豆工作流