
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
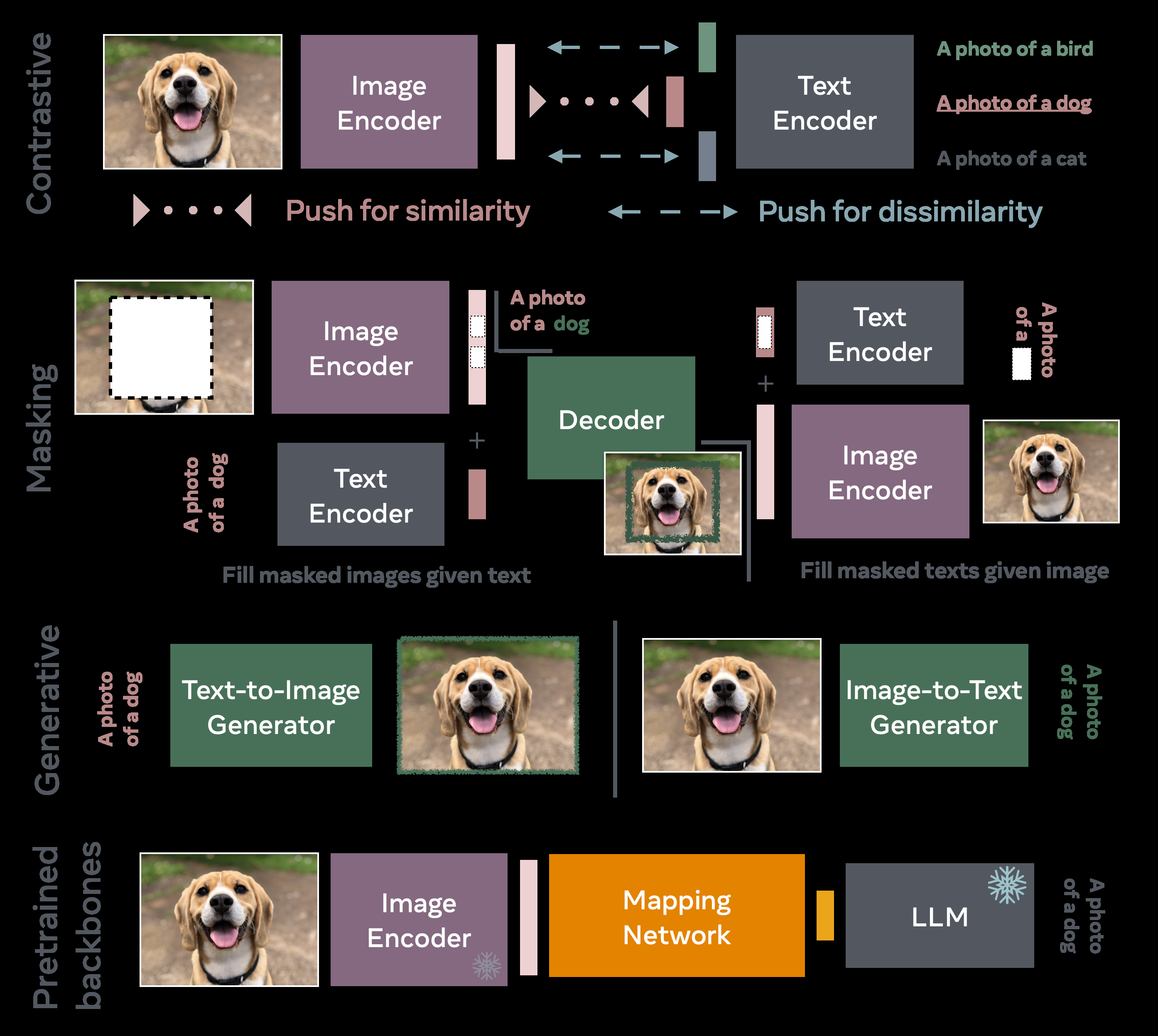
VLM 综述
理论
主要涉及,EBM ,MCMC ,NCE ,SSL
CLIP
经典的用对比学习方法的 infoNCE loss评估的就是 CLIP
- 创新点 视觉和语言共享表征空间
SigLIP
跟CLIP相似,但用的原始的NCE loss 在二项交叉熵上,相比于 CLIP,更适合在小样本批次上 0样本学习
Latent language image pretraining (Llip)
提出用交叉注意力机制来限制图片编码器的捕获,由于多样性增大,提升了下游迁移的分类和检索能力
VLMs with masking objectives
掩码是常规骚操作
FLAVA
首个例子就是,Foundational Language And Vision Alignment (FLAVA)
由三个核心部件组成,每一个依据一个 transformer 框架并针对特定处理模式进行定制
图像编码器用的 VIT 来加载线性表征和基于 transformer 的表征, 包含分类 token,CLS_I
文本就用 transformer 编码,包含分类 token CLS_T
两个编码器的训练都用掩码方式
在此基础上,多模态编码器融合了来自图像和文本编码器的隐藏状态,利用 transformer 框架内学习到的线性投影和交叉注意力机制来整合视觉和文本信息,并通过一个额外的多模态分类标记([CLSM])来突出显示。
该模型采用了综合的训练方案,结合了多模态和单模态的掩码建模损失以及对比目标。
预训练7千万公开图片文本对 ,35个任务 SOTA
MaskVLM
上个的限制是用预训练图片编码器 dVAE,为了减少第三方依赖 ,MaskVLM直接在像素空间和文本空间掩码
使其在文本和图像之间都能正常工作的关键之一是利用从一种模式传递到另一种模式的信息流;文本重构任务接收来自图像编码器的信息,反之亦然。
VLM 里面的信息论
从信息论的角度来看,我们将对比损失和自动编码损失理解为失真的实现,而速率则主要由使用的数据转换决定。
生成式 VLM
前面的方法都只在浅层表征上搞
SD不香吗
CoCa(一个文本生成器)
Contrastive Captioner (CoCa)
CLIP 和对比描述生成器(Contrastive Captioner,CoCa)也采用了一种生成损失,该损失对应于由多模态文本解码器生成的描述。该解码器将图像编码器的输出和由单模态文本解码器生成的表示作为输入。这种新的损失使其能够执行新的多模态理解任务(如视觉问答,VQA),而无需使用多模态融合模块进行进一步适配。CoCa 从零开始进行预训练,仅将带注释的图像标签视为文本。预训练依赖于两个数据集:包含约18亿张带替代文本的图像的 ALIGN 数据集,以及 JFT-3B 内部数据集,该数据集包含超过 29,500 个类别作为标签,但将这些标签视为替代文本。
Chameleon and CM3leon(多模态生成模型)
CM3Leon, 引入特殊 token
这货两阶段训练
第一阶段,检索增强预训练,用一个基于CLIP的编码器和dense检索器获取相关的不同的多模态文档并制作序列。然后使用下一个标记训练模型 对输入序列的预测。检索增强有效地提高了 预训练期间可用的 token ,从而提高数据效率。
第二阶段,用SFT,多任务指令微调,这阶段允许模型处理生成不同模态的内容,显著提升在不同任务的文生图和文字引导图片编辑能力。 SOTA
扩展工作,Chameleon,可以生成带有混合序列的解释
模型稳定对于 qk归一化,修改后的图层规范放置修改很重要
同时他们还讲了咋样把 SFT 从文本模型转到混合模型内容上,在扩展的基础上进行强对齐
用生成式文生图模型适配下游视觉语言模型任务
Likelihood estimation with autoregressive models.
大部分 tokenizer 基于 Vector Quantised-Variational AutoEncoder (VQ-VAE)
Likelihood estimation with diffusion models.
Advantages of generative classifiers.
VLM 预训练骨干网络
Frozen
Frozen 是一个利用预训练大型语言模型(LLM)的首例模型。该工作提出通过一个轻量级映射网络将视觉编码器连接到冻结的语言模型中,该网络将视觉特征投射到文本标记嵌入。
MiniGPT
在 MiniGPT-4 中,使用一个简单的线性投影层来对齐图像表示(使用与 BLIP-2 相同的视觉编码器,基于 Q-Former 和 ViT 骨干)与 Vicuna 语言模型的输入空间。鉴于视觉编码器和 Vicuna 语言模型已经经过预训练并作为现成模型使用,MiniGPT-4 仅需要训练线性投影层,这在两轮中完成。第一轮包括 20,000 个训练步骤(批量大小为 256),对应大约 500 万个来自 Conceptual Caption 、SBU 和 LAION 的图像-文本对。由于仅需要训练线性投影层的参数,作者仅使用了四个 A100 GPU 大约十小时。第二轮训练利用高度精心策划的数据进行指令调优,仅需要 400 个训练步骤(批量大小为 12)。
其他比较受欢迎的骨干模型
- Qwen (256 7B)
- BLIP2(100-200M)
VLM 训练
CLIP实在400M的图片上寻来你的
OpenCLIP 用256-600 GPUs 数以周计才能训练出来
使用数据管理可以打破缩放定律
训练数据
DataComp 提了个benchmark,里面模型架构和训练超参数是固定的
这个聚焦于设计图文数据集来达到强零样本和检索性能在下游的38个任务上
Heuristics
Ranking based on Pretrained VLMs
Diversity and Balancing:
使用合成数据提升训练数据
Bootstrapping Language-Image Pre-training (BLIP)
用 LLAVA 可以高效训练文图生成模型
使用数据增强
-
数据增强在自监督视觉模型中的利用:
- SLIP [Mu et al., 2022] 通过在视觉编码器上引入辅助自监督损失项来回答这个问题。
- 输入图像生成两个增强版本,创建一个正对比组,并与批次中的所有其他图像进行对比。
-
对比损失和正则化的效果:
- 这种方法增加的开销较小,同时提供了一个正则化项,改进了所学习的表示。
-
充分利用文本信号:
- 仅将自监督学习(SSL)损失用于视觉编码器并未充分利用来自文本的重要信号。
-
跨模态的 SSL 损失:
- CLIP-rocket [Fini et al., 2023] 建议将 SSL 损失转换为跨模态。
- CLIP 对比损失在存在多个图像-文本对增强时效果优于其他非对比替代方案。
-
不对称增强和投影器设计:
- 输入的图像-文本对以不对称的方式进行增强,一个是弱增强集,一个是强增强集。
- 使用两个不同的投影器:弱增强对的投影器为线性层,强增强对的投影器为2层的 MLP,以应对噪声嵌入。
-
推理时的表示插值:
- 弱和强增强学习到的表示在推理时被插值以获得一个单一向量。
交错数据管理
-
自回归语言模型与交错数据:
- 像 Flamingo [Alayrac et al., 2022] 和 MM1 [McKinzie et al., 2024] 这样的自回归语言模型表明,在训练期间包含交错的文本和图像数据可以提高模型的少样本性能。
- 用于预训练的交错数据集通常从互联网抓取,并经过精心策划以提高质量和安全性。
-
数据策划策略:
- 自然交错数据:
- 例如 OBELICS [Laurençon et al., 2023] 数据集,该数据集保留了文本和图像在网页文档中共同出现的固有结构和上下文,提供了更真实的多模态网络内容表示。
- 数据策划步骤包括从 Common Crawl 收集英语数据并进行去重,预处理 HTML 文档以识别和保留有用的 DOM 节点,对每个 DOM 节点应用图像过滤以去除标志,接着是段落文本,并使用各种启发式方法进行文档级文本过滤以处理格式不良或不连贯的文本。
- 合成交错数据:
- 例如 MMC4 [Zhu et al., 2023b] 数据集,该数据集通过将从互联网收集的图像与仅包含文本的数据集进行改造,图像根据上下文相关性与文本配对,这通过计算基于 CLIP 的相似度分数实现。
- 这种方法提供了一种将现有的大量文本语料库改造为具有视觉信息的方法,从而扩展了它们在多模态学习中的用途。
- 虽然这种方法可能缺乏自然交错数据集的上下文细微差别,但它允许从成熟的仅文本资源中大规模创建多模态数据。
- 自然交错数据:
评估多模态数据质量
方法
- QuRating
- Data efficient LMs
- text-quality-based pruning
相似的有
- VILA
- LAION-aesthetics
利用人类专业知识:数据标注
目前流行的多模态数据集
- OKVQA
- A-OKVQA
- Image Paragraph Captioning
- VisDial
- Visual Spatial Reasoning
- MagicBrush
这些大部分依赖 COCO,或者 Visual Genome 的老benchmarks
最近的
- DCI dataset
软件
用现成的
- OpenCLIP
- transformers
我需要多少 GPU
像 CLIP 和 OPENCLIP 用了超过 500个GPU去训练
数据集质量高就不超过 64 个GPU
这里都是从头训练
加速训练
- Pytorch
- 高效的注意力机制
- xformers
- FFCV
- Masking
超参数的重要性
我该用啥模型
啥时候用 CLIP 的对比模型
- 对比模型与文本-视觉概念关联:
- 像 CLIP 这样的对比模型通过在表示空间中匹配文本和图像表示来关联文本与视觉概念,保持了简单的训练范式。
- 通过这种方式,CLIP 学习到在图像和文本空间中都有意义的表示,使得可以通过提示 CLIP 文本编码器的单词来检索与相应文本表示匹配的图像。
- 数据策划管道:
- 例如,MetaCLIP [Xu et al., 2024] 使用元数据字符串匹配来构建数据集,以确保每个单词或概念都有足够的图像与之关联。
- CLIP 模型也是构建更复杂模型的良好基础,特别是在试图改进基础时。
- 研究和应用:
- 对于研究人员来说,CLIP 是一个特别好的起点,适合尝试额外的训练标准或不同的模型架构,以更好地捕捉关系或理解概念。
- 然而,需要注意的是,CLIP 不是生成模型,因此无法根据特定图像生成描述,只能在现有描述列表中检索最佳描述。
- 局限性:
- CLIP 目前不能用于提供给定图像的高级描述。
- CLIP 通常需要非常大的数据集和大批量大小才能提供不错的性能,这意味着从头训练 CLIP 需要大量资源。
啥时候用掩码模型
-
掩码策略:
- 掩码是一种训练视觉语言模型(VLMs)的替代策略。通过学习重建被掩码的图像和文本,可以联合建模它们的分布。
- 与在表示空间中操作的对比模型不同,基于掩码的模型可能需要利用解码器将表示映射回输入空间,并应用重建损失。
-
训练解码器的挑战:
- 训练额外的解码器可能会增加一个瓶颈,使这些方法比纯对比方法效率低。
-
掩码策略的优势:
- 不再依赖批量,因为每个例子可以单独考虑(不需要负例)。
- 移除负例可以使用更小的迷你批次,无需微调额外的超参数(如softmax温度)。
-
混合策略:
- 许多 VLM 方法利用掩码策略与一些对比损失的混合策略。
啥时候用生成模型
-
生成模型的能力:
- 基于扩散或自回归标准的生成模型在根据文本提示生成逼真图像方面表现出色。
- 大多数大型视觉语言模型(VLM)训练也开始整合图像生成组件。
-
研究观点:
- 一些研究人员认为,能够根据单词生成图像是创建良好世界模型的重要一步。
- 另一些研究人员认为,这种重建步骤不是必需的 [Balestriero and LeCun, 2024]。
-
应用视角:
- 从应用角度来看,模型能够在输入数据空间解码抽象表示时,更容易理解和评估模型的学习成果。
- 像 CLIP 这样的模型需要使用数百万图像数据点进行广泛的 k-NN 评估,而生成模型可以直接输出最可能的图像。
-
隐式联合分布:
- 生成模型可以学习文本和图像之间的隐式联合分布,这可能比利用预训练的单模态编码器更适合学习良好的表示。
-
计算开销:
- 生成模型比对比学习模型训练所需的计算资源更多。
啥时候用预训练骨干
-
预训练编码器的使用:
- 在资源有限的情况下,使用已经预训练的文本或视觉编码器是一个不错的选择。在这种情况下,只需学习文本表示和视觉表示之间的映射。
-
潜在问题:
- 这种方法的主要问题是,视觉语言模型(VLM)可能会受到大型语言模型(LLM)潜在幻觉的影响。
- 也可能受到预训练模型中任何偏见的影响。
- 因此,可能需要额外的工作来纠正视觉模型或 LLM 的缺陷。
-
独立编码器与联合学习的观点:
- 一些人认为利用独立的图像和文本编码器将信息投射到较低维度的流形上,然后学习映射是重要的。
- 另一些人则认为联合学习图像和文本的分布更为重要。
-
总结:
- 在计算资源有限的情况下,使用预训练模型是一个有趣的选择,尤其是研究人员对学习表示空间中的映射感兴趣时。
提升答案
使用边界盒子标注
- IoU
负捕获
提升对齐
RLHF
LLaVA-NeXT
多模态在ICL
提升图片文本富语义度理解
MLLMs 对 OCR 极好
使用细粒度的文本丰富数据进行指令调整:LLaVAR
处理高分辨率图像中的细粒度文本:Monkey
解耦场景文本识别模块和 MM-LLM : Lumos
PEFT
- LoRA base
- QLoRA
- VeRA
- DoRA
- Prompt base
- CoOp
- VPT
- Adapter base
- CLIP-Adapter
- VL-Adapter
- LLaMA-Adapter V2
- Mapping base
- LiMBeR
- MAPL
评估方法
VQA
Benchmarking 视觉语言能力
图像描述
由 Chen 等人 [2015] 引入的 COCO 描述数据集和挑战赛用于评估给定视觉语言模型(VLM)生成的描述质量。通过利用外部评估服务器,
图文一致性
视觉问答
- 筛选预测
- 视觉对话
以文本为中心的视觉问答
零样本图像分类
尤其是在 OOD 任务
视觉语言构图推理
ARO
密集描述和裁剪描述匹配
DCI
基于合成数据的视觉语言评估
PUG
benchmarking VLM 中的基准偏差和差异
通过分类 benchmark bias
- 真实数据
- 合成数据
通过 embedding Benchmark bias
语言 bias 影响你的benchmark
评估训练中的特殊概念怎么影响你的下游任务表现
benchmark 幻觉
benchmark 记忆
红队测试(安全攻防)
扩展 VLM 到视频
早期基于 BERT 的视频模型
-
Multimodal Event Representation Learning Over Time (MERLOT)
-
VideoBERT
用早期混合 VLM 获取文本生成能力
使用预训练LLM
评估中的机会
利用视频数据的挑战
提到的术语概览
- ARO Attribution, Relation, and Order. 36
- BERT Bidirectional Encoder Representations from Transformers. 6
- BLIP Bootstrapping Language-Image Pre-training. 19
- CLIP Contrastive Language–Image Pre-training. 9
- CNN Convolutional Neural Network. 13
- CoCa Contrastive Captioner. 11
- DCI Densely Captioned Images. 37
- EBM Energy-Based Models. 6
- FFCV Fast Forward Computer Vision. 22
- FLAVA Foundational Language And Vision Alignment. 9
- IoU Intersection over Union. 25
- LLaVA Large Language-and-Vision Assistant. 19, 26
- LLMs Large Language Models. 4
- LM Language Model. 33
- LoRa Low Rank Adapters. 29
- MCMC Markov Chain Monte Carlo. 8
- MERLOT Multimodal Event Representation Learning Over Time. 43
- MIM Masked Image Modeling. 9
- MLLMs Multimodal Large Language Models. 28
- MLM Masked Language Modeling. 9
- NCE Noise Contrastive Estimation. 8
- OBELICS Open Bimodal Examples from Large fIltered Commoncrawl Snapshots. 20
- OCR Optical Character Recognition. 28, 33, 35
- OOD Out-Of Distribution. 36
- PEFT Parameter-Efficient Fine-Tuning. 29
- PUG Photorealistic Unreal Graphics. 38
- RLHF Reinforcement Learning from Human - Feedback. 26, 27
- ROI Region of Interest. 29
- SSL Self-Supervised Learning. 8
- STR Scene text recognition. 29
- ViT Vision Transformer. 10
- VLMs Vision Language Models. 4
- VQ-VAE Vector Quantised-Variational
- AutoEncoder. 13
- VQA Visual Question Answering. 31, 33