CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
模块化RAG
RAG Pipeline 变动
- 在检索增强数据源上
- 引入半结构化数据(PDF,HTML,LaTex)
- 结构化数据(KG,三元组,结构化查询语句)
- 减少对外部知识源的依赖
- 在检索技术上
- FT 与 RAG结合
- 单独检索器或生成器微调
- 增加Adapter对齐query和chunk之间的GAP
- 增加下游任务检索器适配器
- 通过RL和更强LLM监督增强检索
- 在检索增强流程上
- 迭代多轮检索增强(检索内容指导生成,生成内容进一步指导检索)
- LLM自主判断是否需要检索
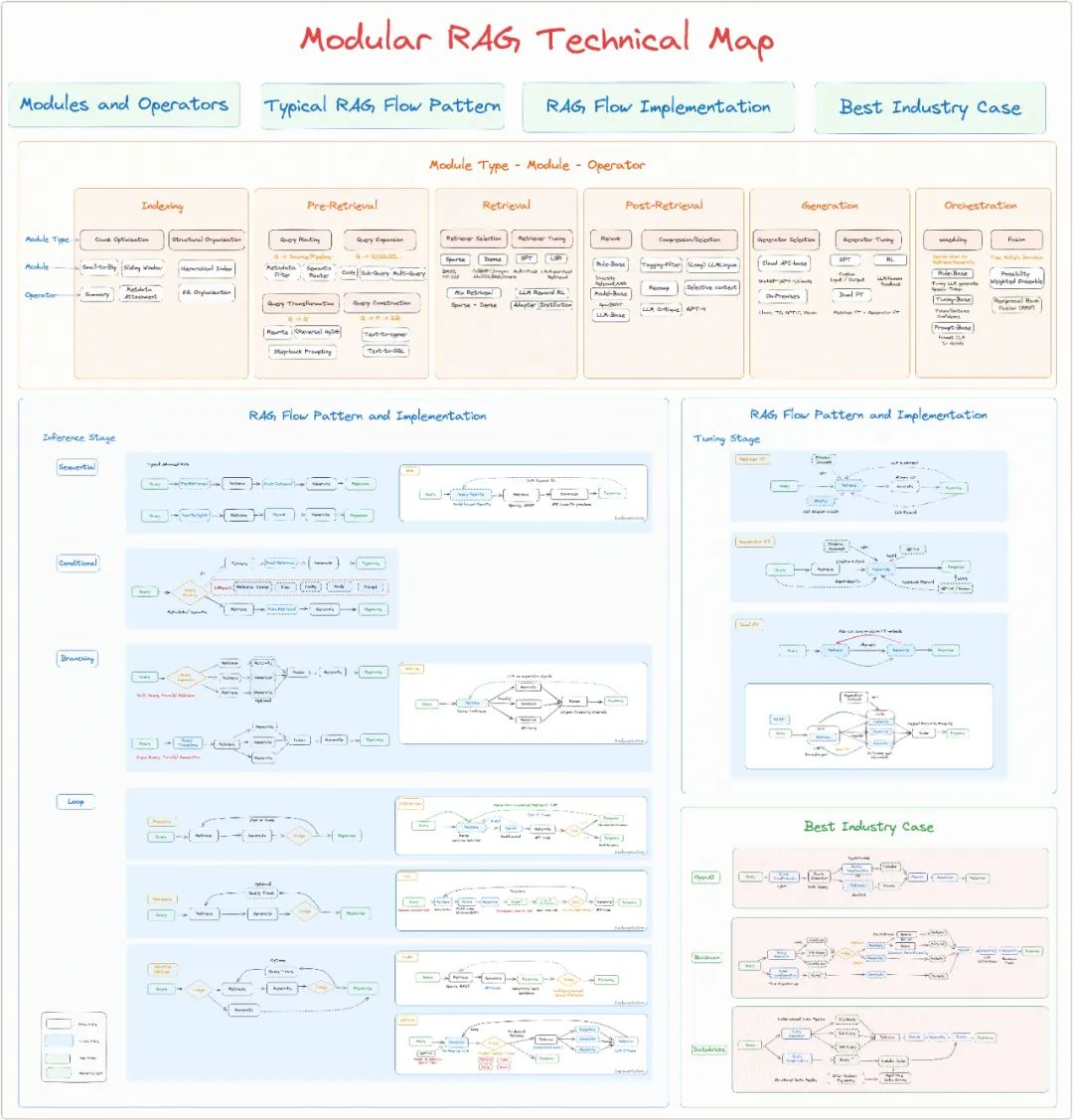
Modular RAG
- Molule Type(核心流程(功能模块)——>具体算子)
- Module
- Operator
Pipeline 变成模块与算子之间的排列组合

RAG Flow
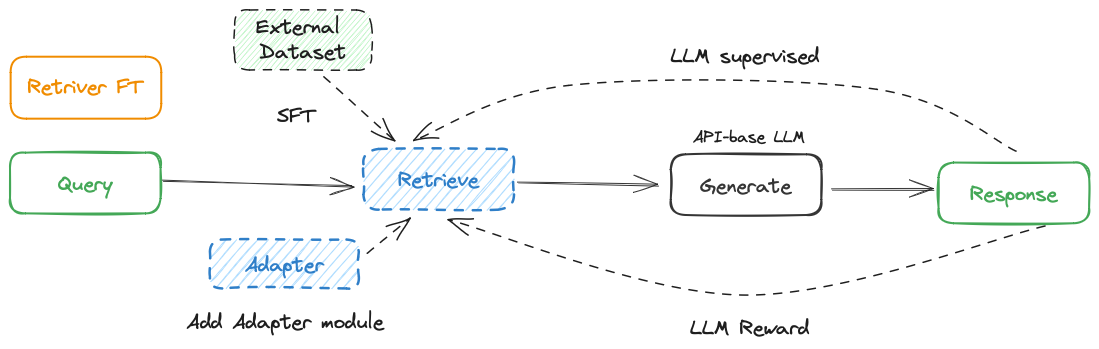
微调模式
- 检索器微调
- 直接微调。
- 添加可训练的Adapter 模块
- LSR(LM-supervised Retrieval)
- LLM Reward RL
- 生成器微调
- 直接微调。
- GPT-4蒸馏。
- 基于反馈的强化学习(RLHF)
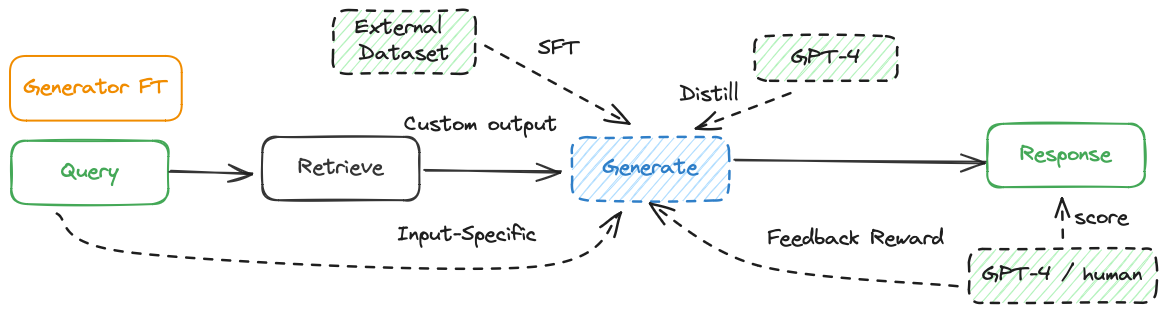
- 协同微调
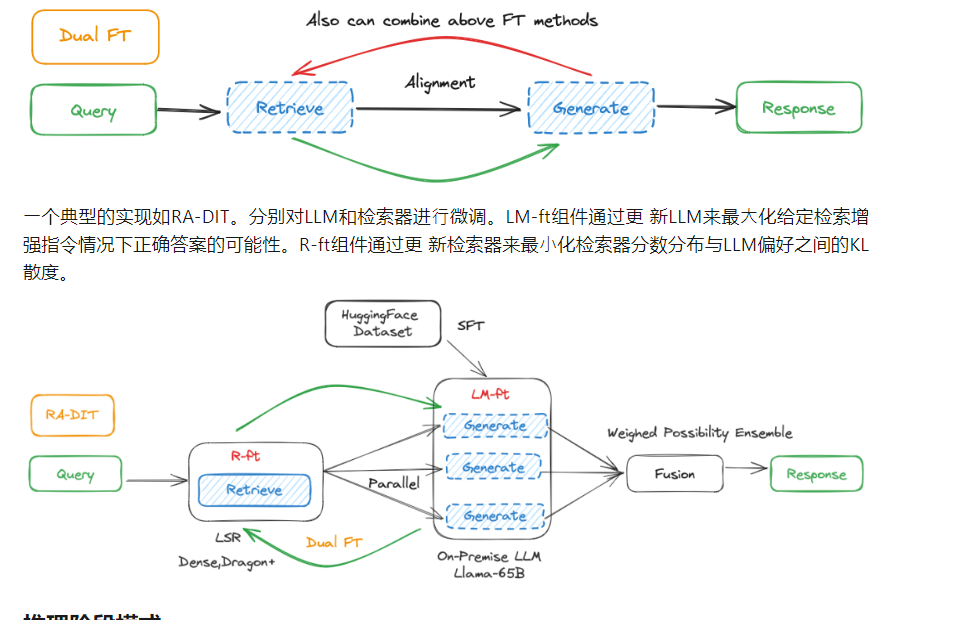
推理阶段模式
-
Sequential
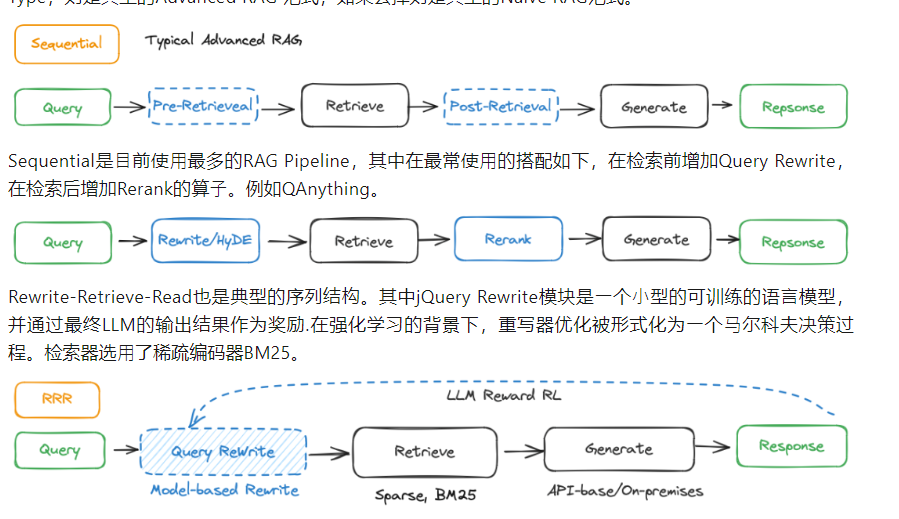
-
Conditional
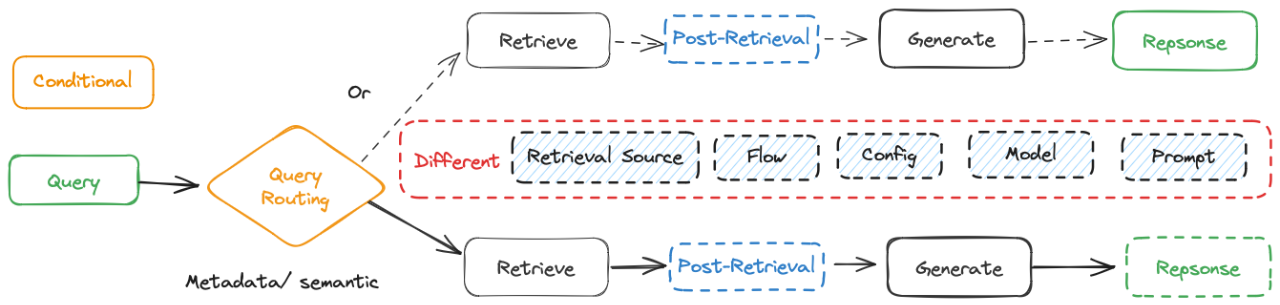
-
Branching
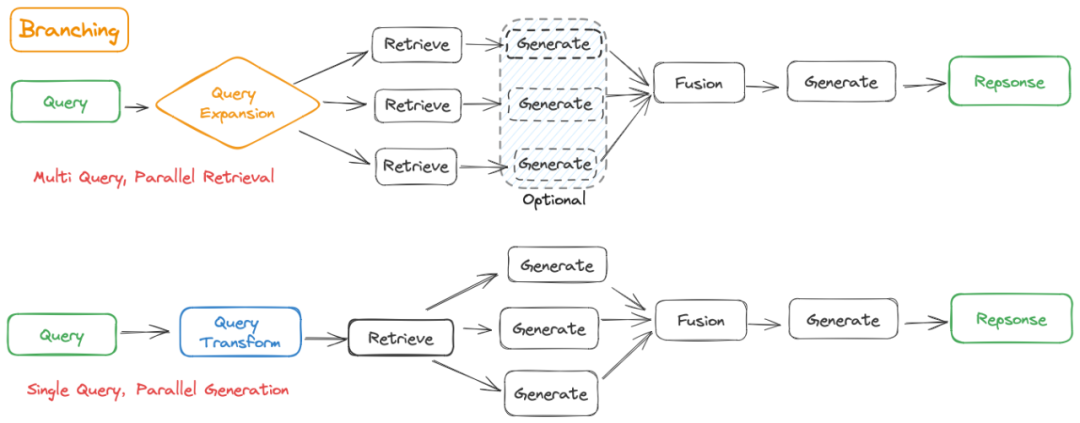
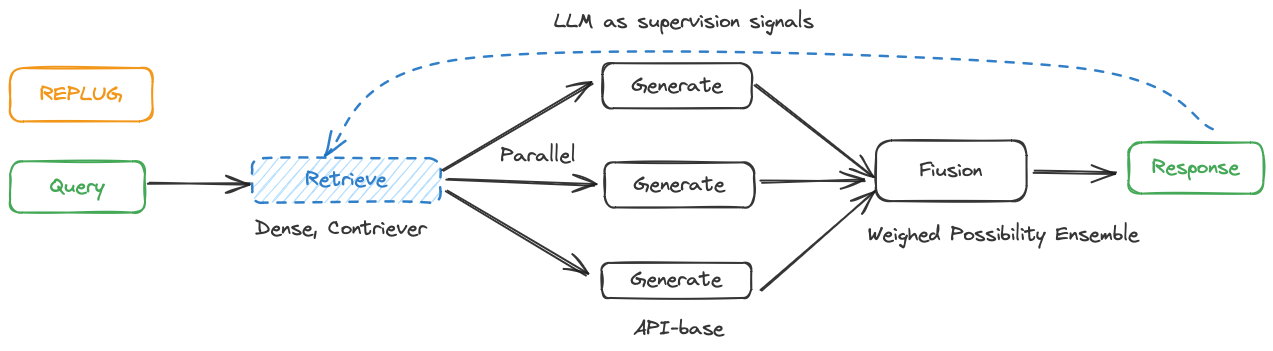
-
Loop
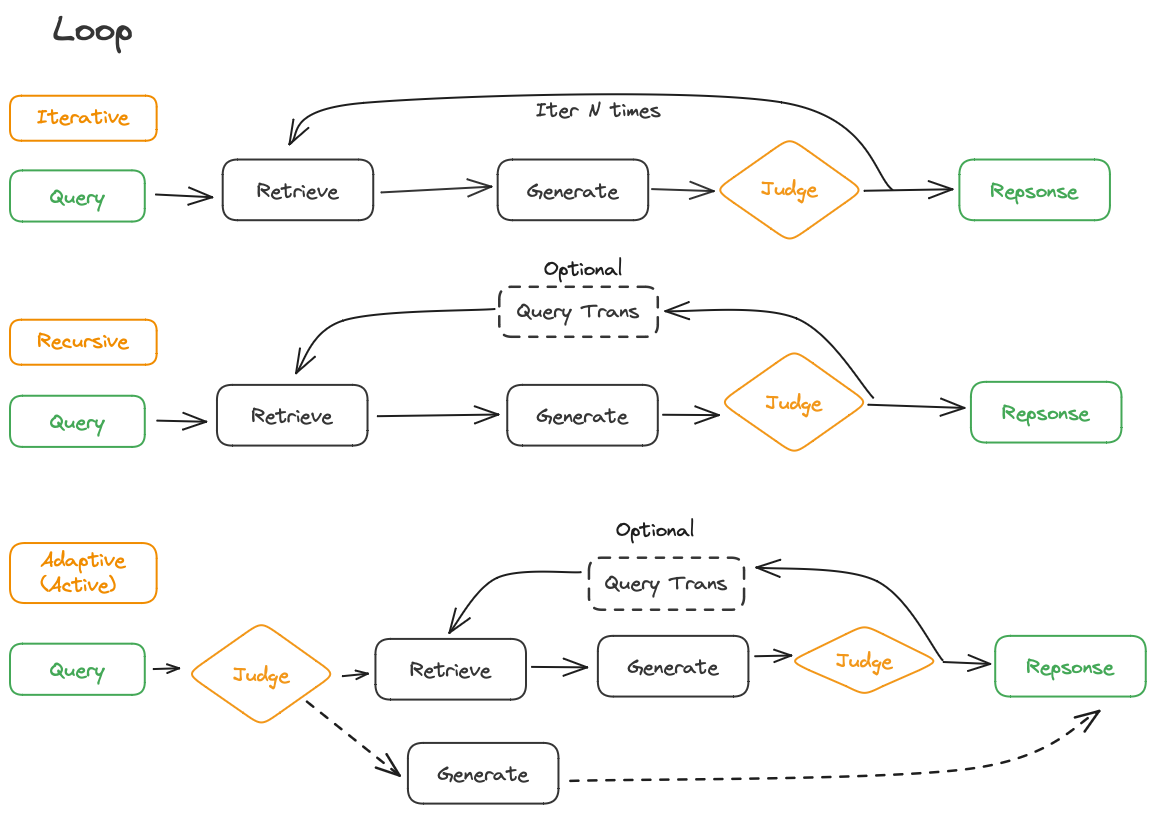
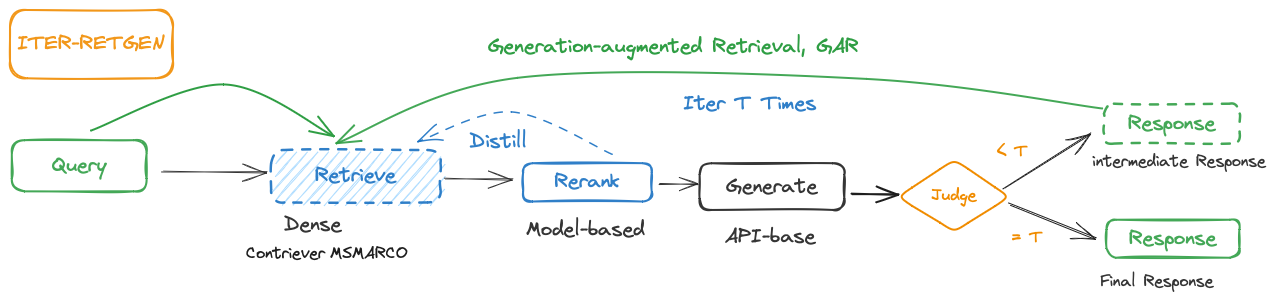
- Iterative Retrieval
- Recursive Retrieval

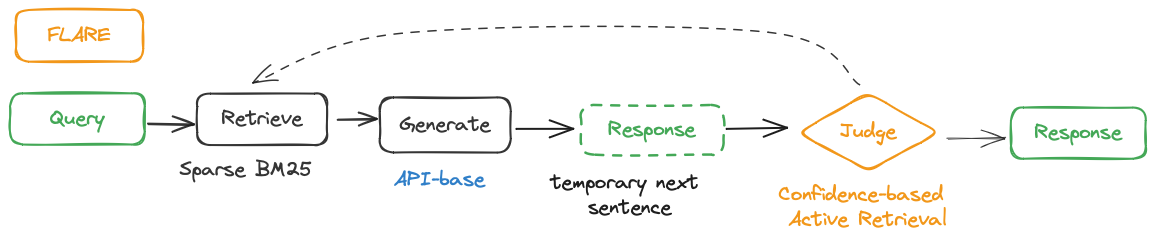
- Adaptive (Active) Retrieval
- Prompt-base
- Tuning-base.
- 给输入提示和前面的结果判断,预测特殊token
- 有帮助,调用检索模型
- ⽣成⼀个critique token来评估检索段的相关 性, 下⼀个响应⽚段,和⼀个批判令牌来评估响应⽚段中的信息是否得到了检索段的⽀持
- ⼀个新的批判令牌评估响应的整体效⽤。模型会并⾏处理这些内容,并选择最佳结果作为最终的输出。
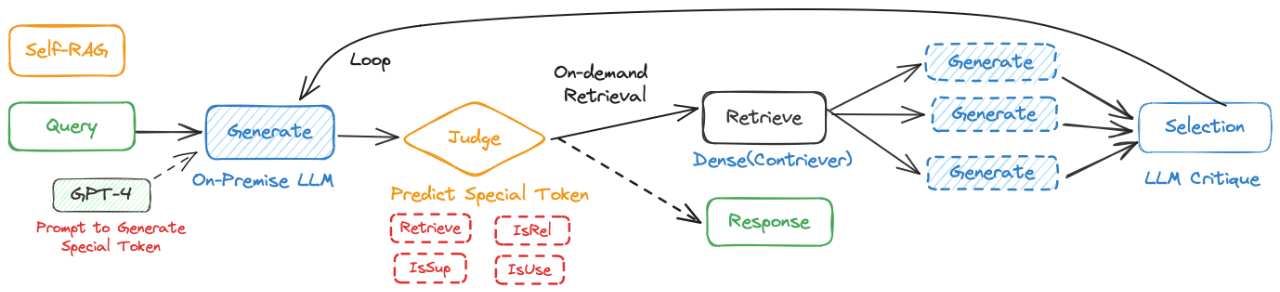
- Prompt-base
整理同济提出的案例
- OPENAI猜的

- 百川智能

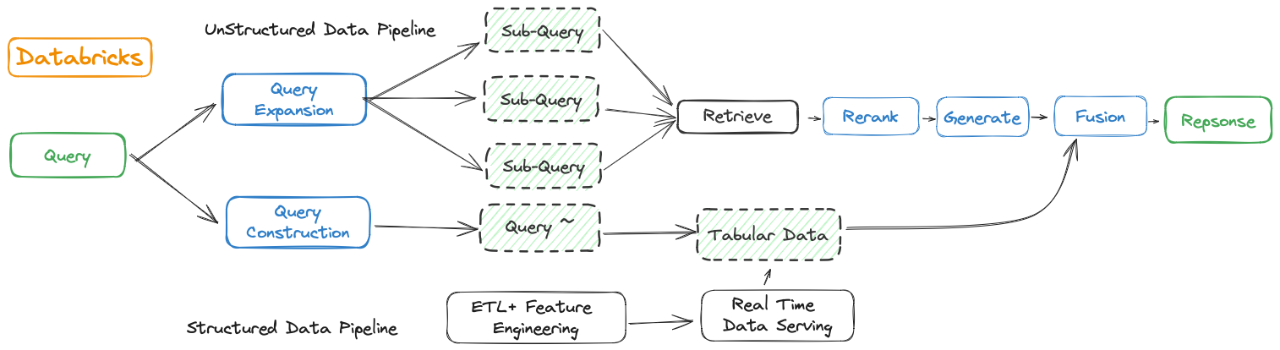
- Databricks