
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
CUDA编程

- 查询GPU详细信息
nvidia-smi -q
- 查询特定GPU的详细信息
nvidia-smi -q -i 0
- 查询GPU特定信息
nvidia-smi -q -i 0 -d MEMORY
- 帮助指令
nvidia-smi -h
- 编译执行代码
nvcc hello.cu -o hello
CUDA 核函数
- 核函数再GPU上进行并行执行
- 注意
- 限定词__global__修饰
- 返回必须是void
- 形式
__global__ void kernel_function(argument arg) { printf("Hello"); }
注意事项
- 核函数只能访问GPU内存
- 核函数不能使用变长参数
- 核函数不能使用静态变量
- 核函数不能使用函数指针
- 核函数具有异步性
CUDA 线程模型
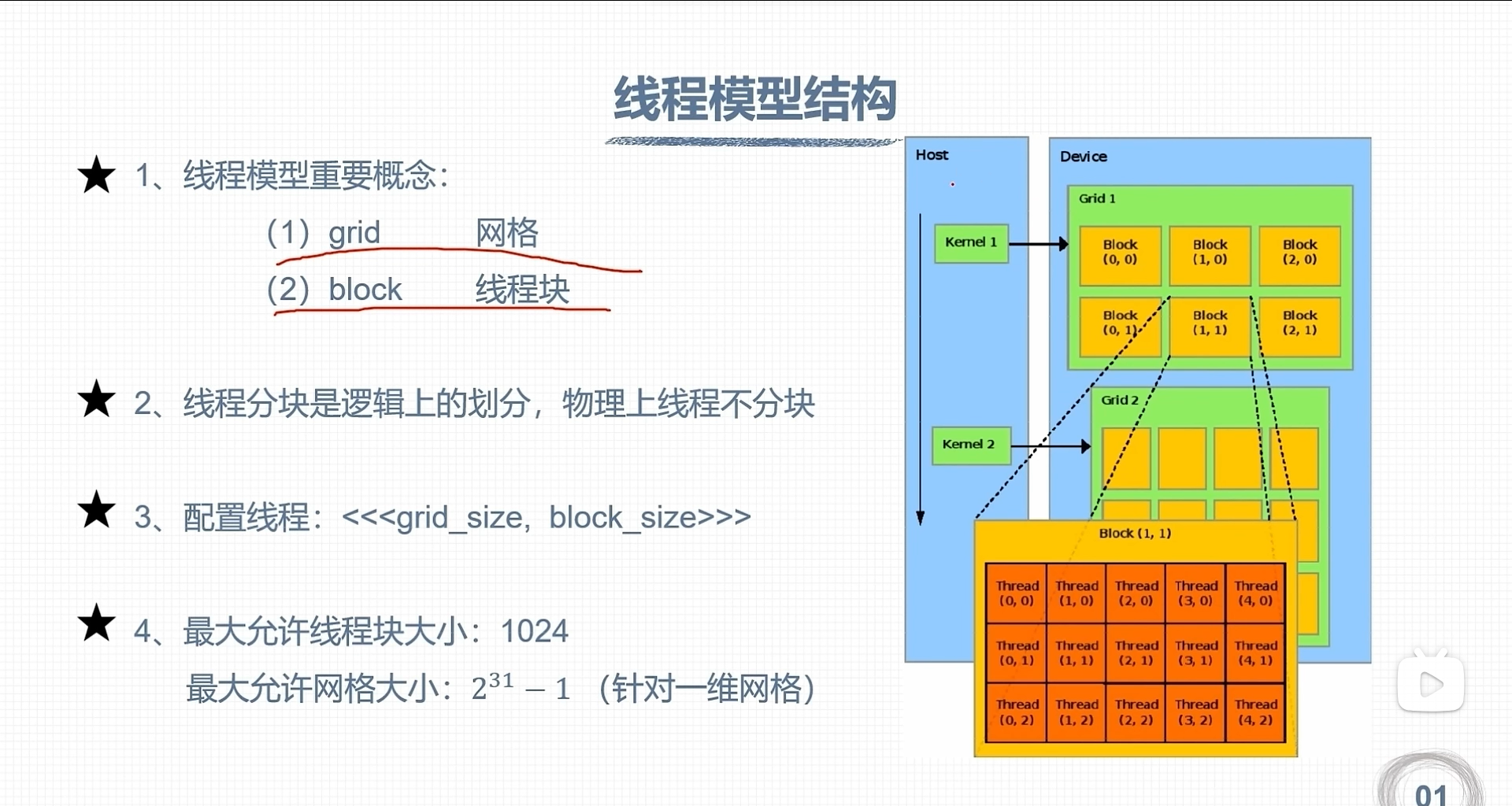
«<grid_size,block_size»> gridDim.x:该变量的数值等于执行配置变量grid_size的值 blockDim.x:该变量的数值等于执行配置变量block_size的值
线程索引保存成内建变量
- blockId.x:该变量指定一个线程在一个网格中的线程块索引值,范围0-gridDim.x-1
- threadId.x:该变量指定一个线程在一个线程块中的索引值,范围0-blockDim.x-1
CUDA 可以推广到三维网格和线程块
线程计算方式
-
单线程计算方式
-
22的 int blockId=blockIdx.x+blockId.ygridDim.x; int threadId=threadIdx.x+threadId.yblockDim.x; int id = blockId(blockDim.x*blockDim.y)+threadId;
-
33的 int blockId=blockIdx.x+blockId.ygridDim.x+blockId.zgridDim.xgridDim.y; int threadId=(threadIdx.z(blockDim.xblockDim.y))+(threadId.y * blockDim.x)+threadId.x; int id = blockId(blockDim.xblockDim.y*blockDim.z)+threadId;
nvcc编译流程与GPU计算能力
nvcc分为
- 主机代码(c/C++)
- 设备代码(扩展语言)
nvcc»PTX(伪汇编代码)»cubin(二进制代码)
GPU 计算能力
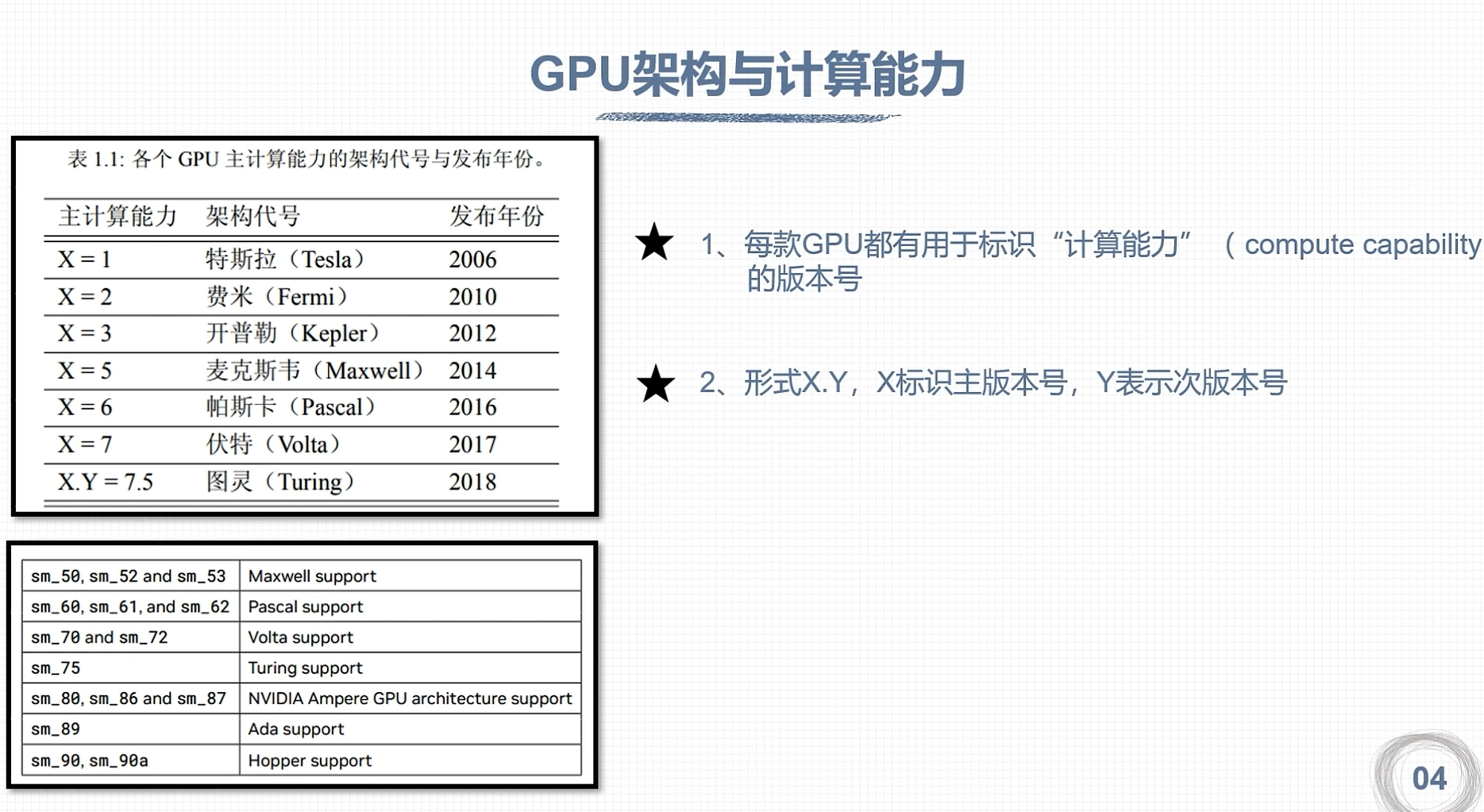
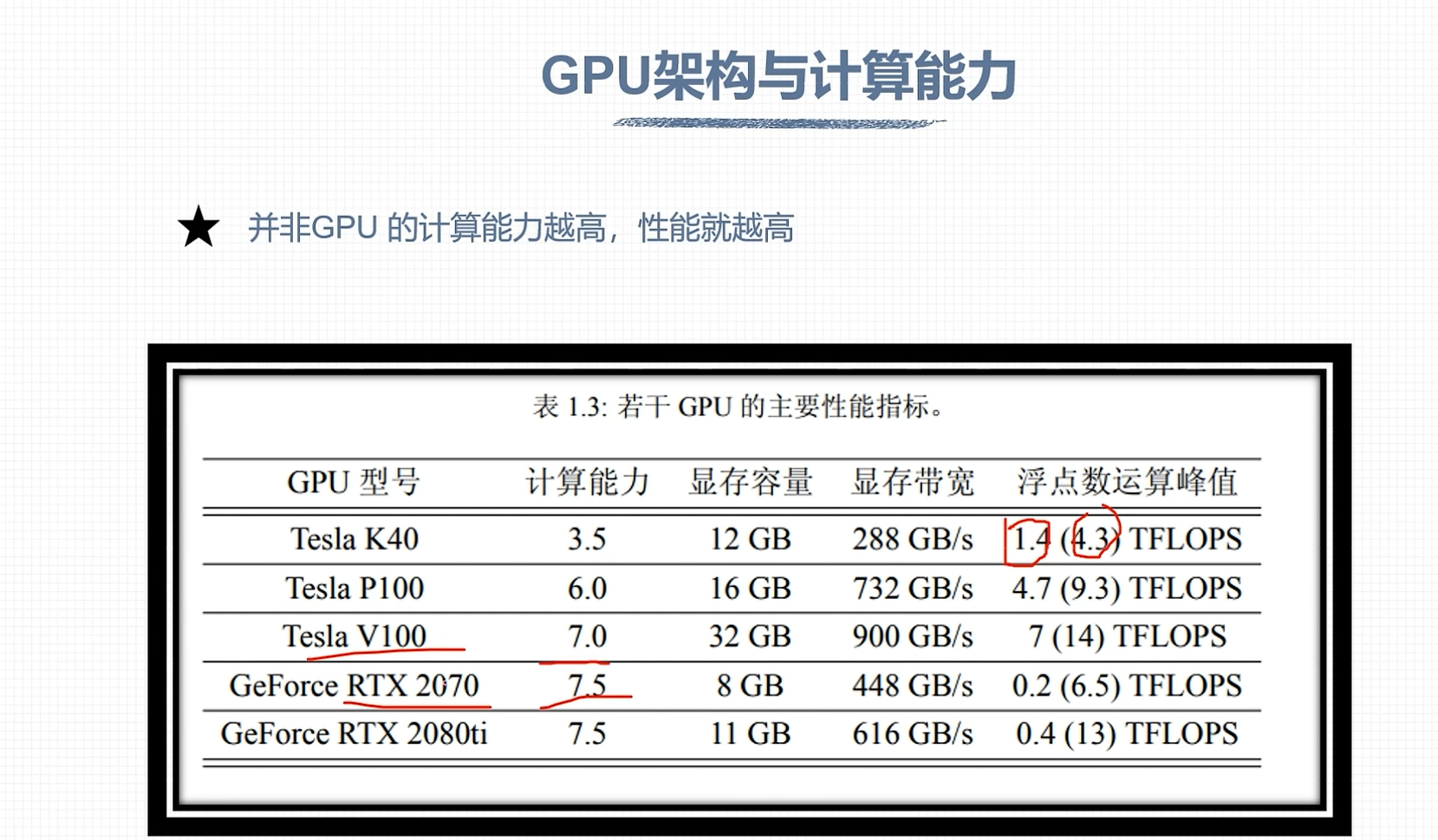
CUDA程序兼容
虚拟架构计算能力

指定真实架构计算能力

架构对比

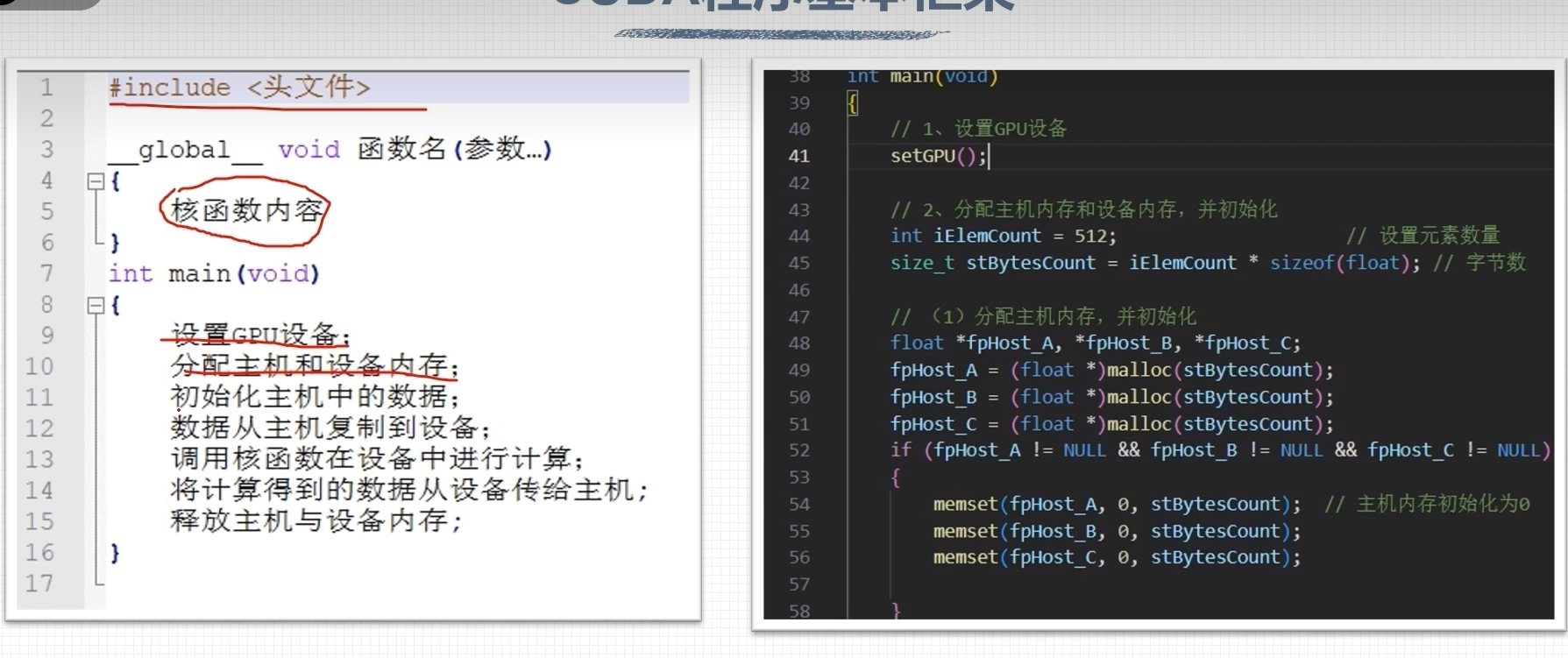
CUDA矩阵加法运算程序
// 生成矩阵加法运算程序
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#define TILE_WIDTH 32
__global__ void matrixAdd(int *A, int *B, int *C, int width, int height) {
__shared__ int tileA[TILE_WIDTH][TILE_WIDTH];
__shared__ int tileB[TILE_WIDTH][TILE_WIDTH];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
for (int m = 0; m < width / TILE_WIDTH; m++) {
tileA[threadIdx.y][threadIdx.x] = A[row * width + m * TILE_WIDTH + threadIdx.x];
tileB[threadIdx.y][threadIdx.x] = B[row * width + m * TILE_WIDTH + threadIdx.x];
__syncthreads();
for (int k = 0; k < TILE_WIDTH; k++) {
sum += tileA[threadIdx.y][k] * tileB[k][threadIdx.x];
}
__syncthreads();
}
C[row * width + col] = sum;
}
int main(int argc, char **argv)
- 获取GPU的数量
int iDeviceCount = 0;
cudaGetDeviceCount(&iDeviceCount);
- 设置GPU执行时使用的设备
int iDev=0;
cudaSetDevice(iDev);
内存管理
CUDA通过内存分配、数据传递、内存初始化、内存释放进行内存管理
| stand C | CUDA mem |
|---|---|
| malloc | cudaMalloc |
| memcpy | cudaMemcpy |
| memset | cudaMemset |
| free | cudaFree |
- 设备分配内存 ```c++ float *fpDevice_A; cudaMalloc((void**)&fpDevice_A, nBytes);
- 数据拷贝
```c++
cudaMemcpy(Device_A, Host_A, nBytes, cudaMemcpyHostToHost);
- 内存初始化
cudaMemset(Device_A, 0, nBytes); - 释放内存
cudaFree(Device_A);

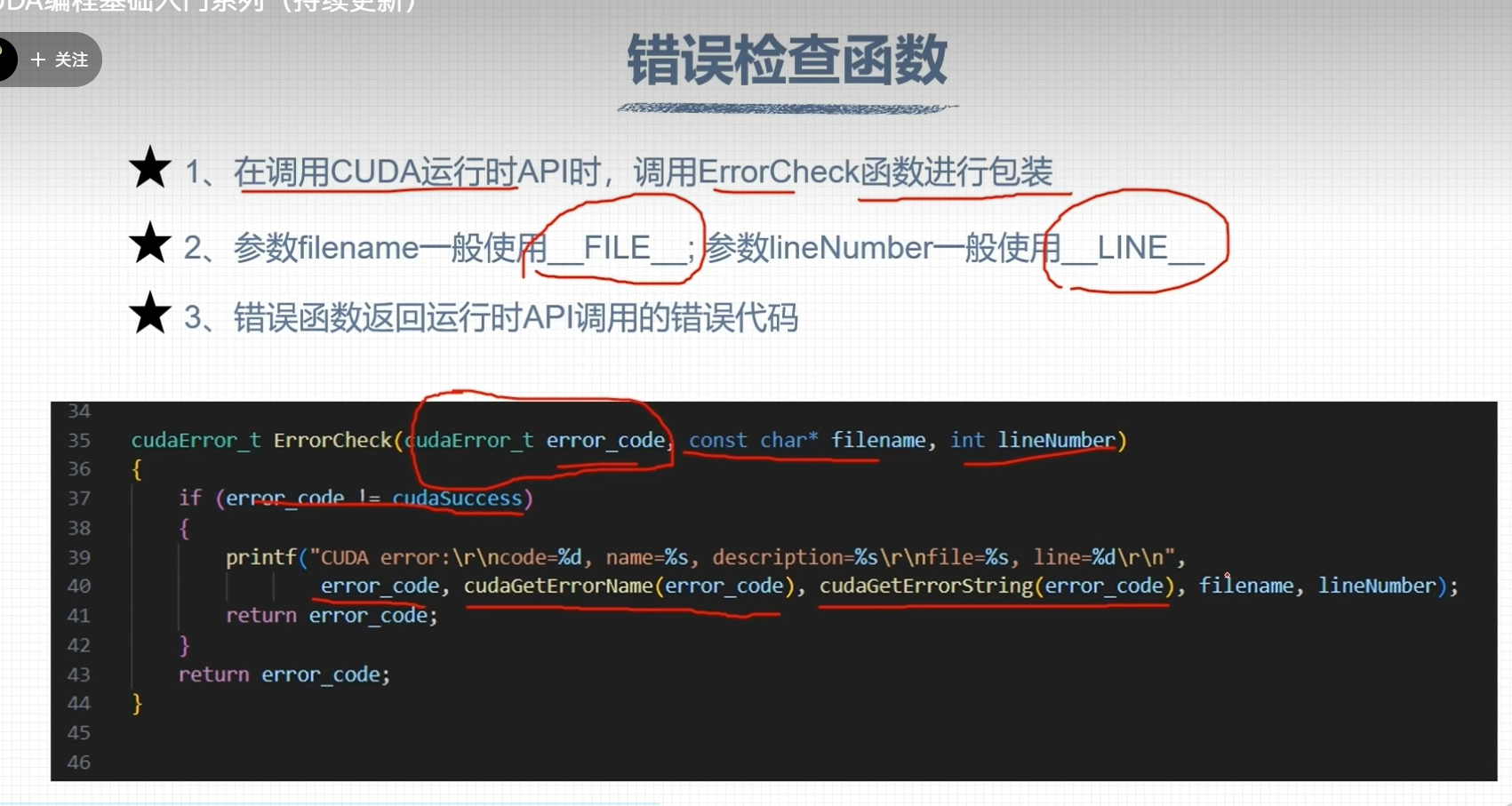
CUDA错误检查
CUDA计时
GPU 查询

寄存器
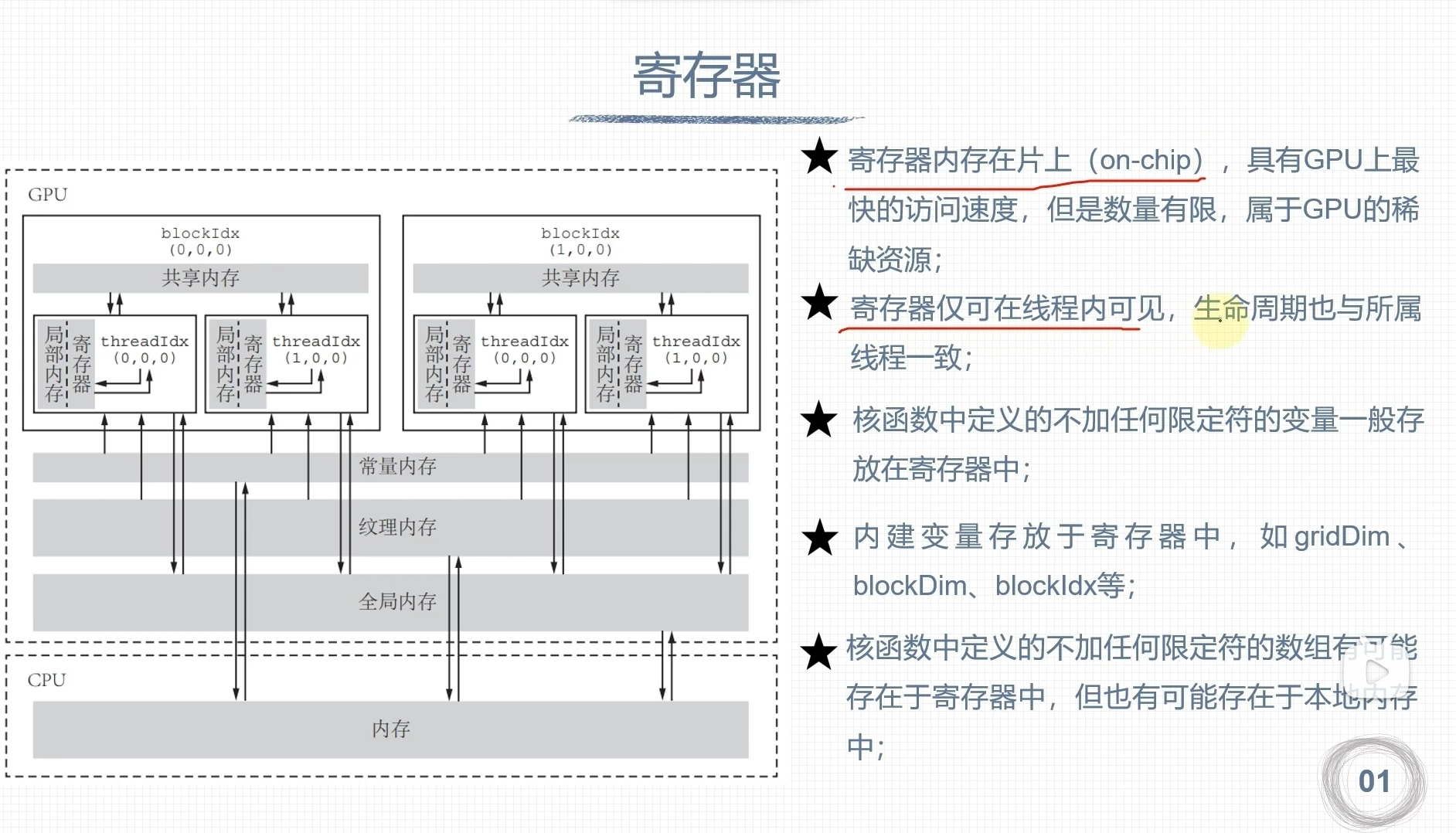
- 寄存器都是32位的,也就是说保存一个double类型的数据需要两个寄存器
- 计算能力5.0-9.0,每个SM都是64K的寄存器数量,Fermi架构只有32K
- 每个线程块使用的最大数量不同架构是不同的,计算能力6.1的是64K
- 每个线程最大寄存器数量是255个,Fermi架构是63个
本地内存
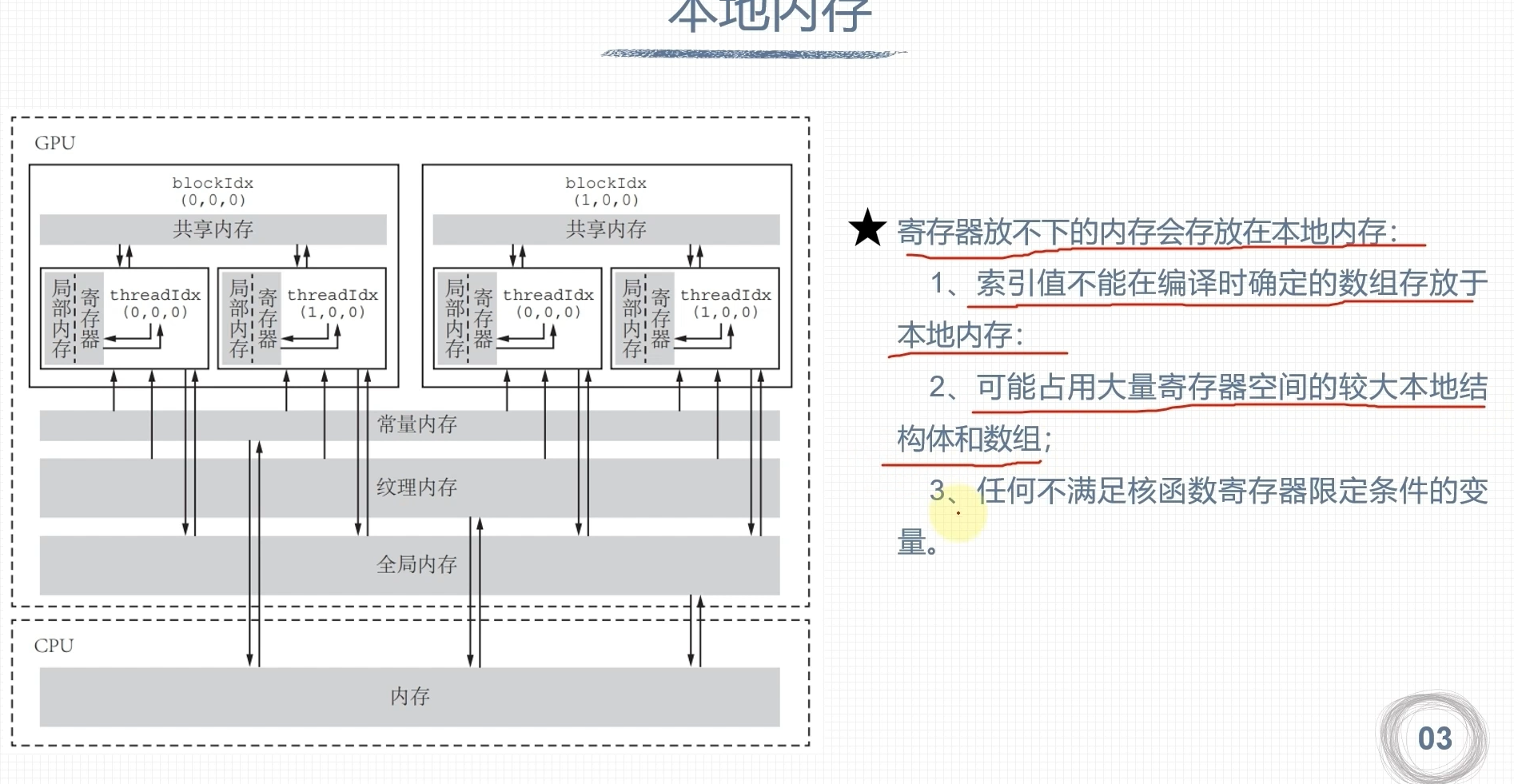
- 每个线程最多可使用512K的本地内存
- 本地内存从硬件角度看只是全局内存的一部分,延迟也很高,本地内存过多使用会降低程序性能
- 对于计算2.0以上的设备,本地内存的数据储存在每个SM的一级缓存和设备的二级缓存中
寄存器溢出
- 核函数所需寄存器数量超出硬件支持,数据则会保存到本地内存
- 一个SM并行运行多个线程块/线程束,总的需求寄存器容量大于64K
- 单个线程运行所需寄存器数量大于255个
- 寄存器溢出会降低程序运行性能
- 本地内存只是全局内存的一部分,延迟较高
- 寄存器溢出的部分也可进入GPU的缓存中
全局内存
特点: 容量最大,延迟最大,使用最多
全局内存的数据所有线程可见,Host端可见,切具有与程序相同的生命周期
全局内存初始化
- 动态 主机代码使用CUDA运行API cudaMalloc动态声明内存空间,由cuduFree释放全局内存
- 静态 使用__device__关键字声明
共享内存
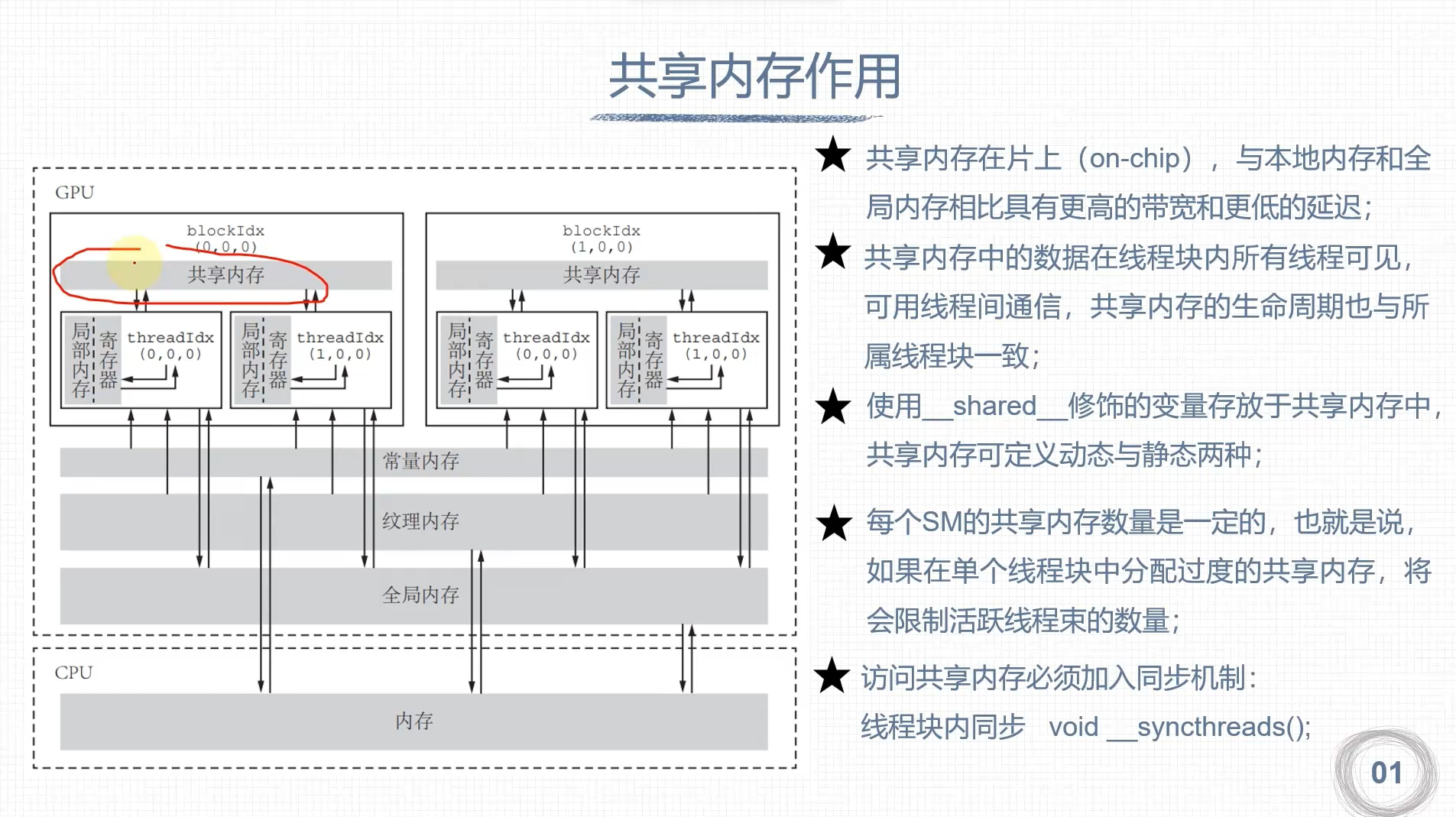
- 经常访问的数据由全局内存搬到共享内存,提高访问效率
- 改变全局内存的访问内存的内存事物方式,提高数据访问的带宽

常量内存
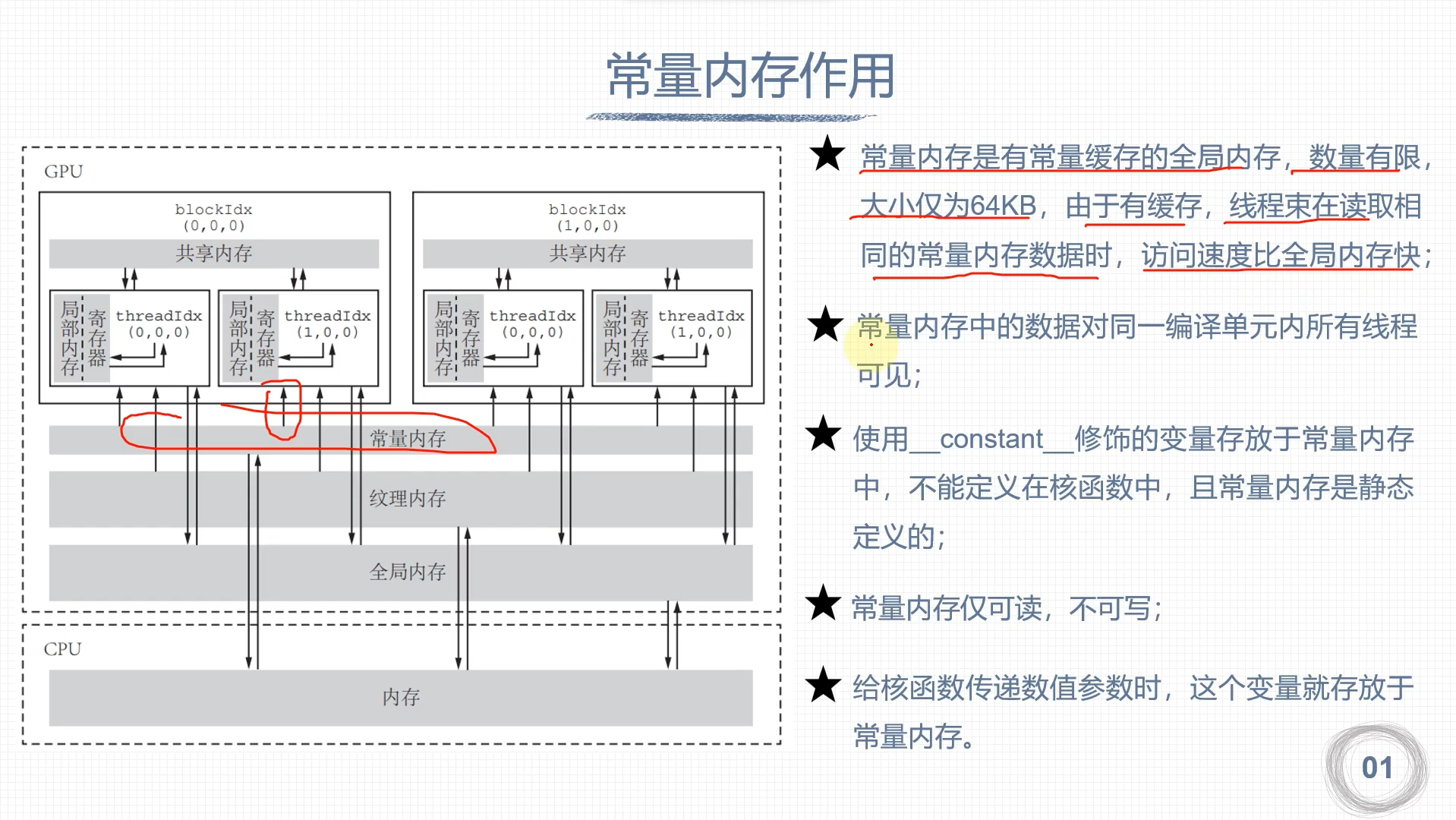
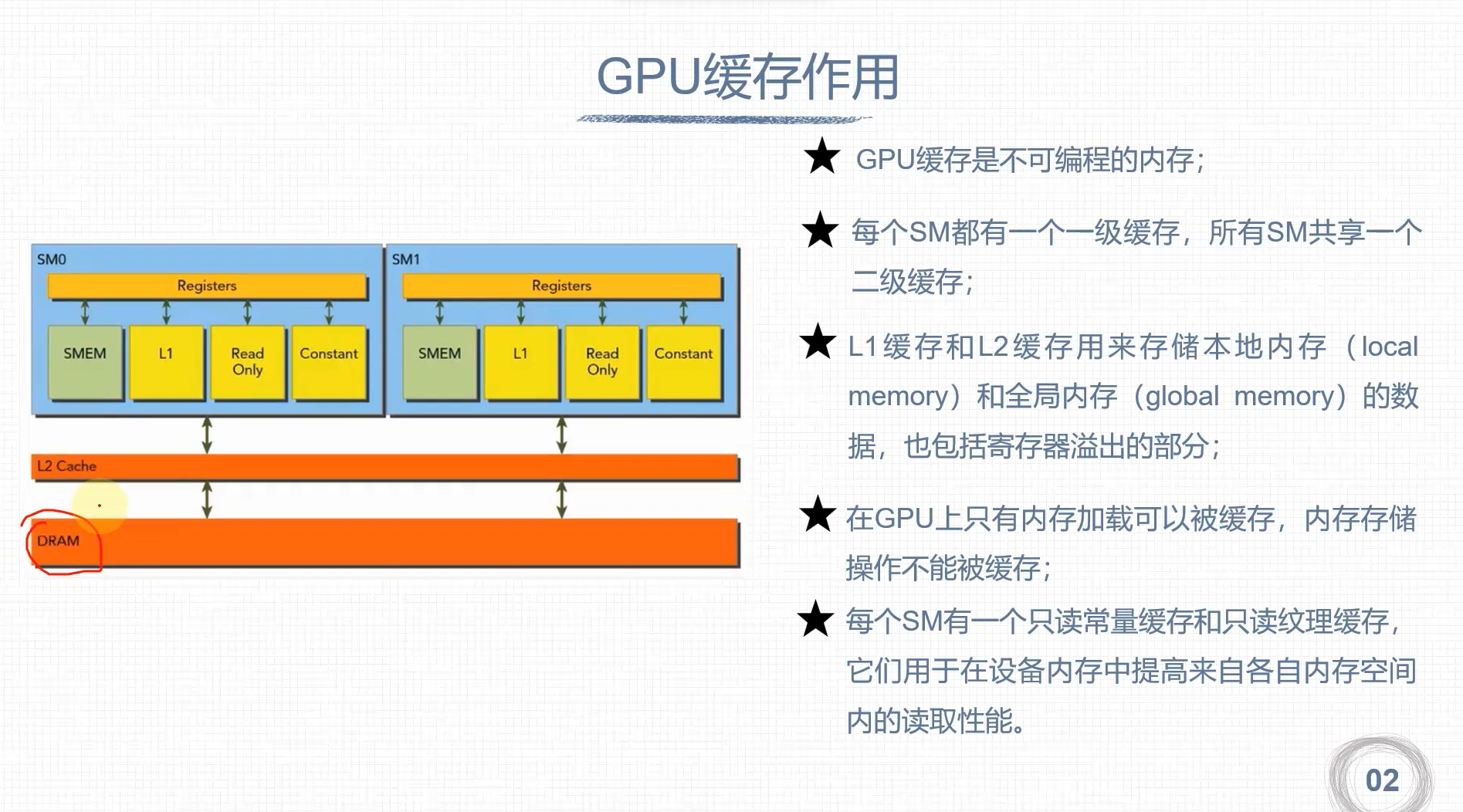
GPU缓存
- 一级缓存(L1)
- 二级缓存(L2)
- 只读常量
- 只读纹理
计算资源分配

- 每个线程消耗的寄存器越多,则可以放在一个SM中的线程数就越少
-
如果减少内核消耗寄存器的数量,SM可以同时处理更多的线程数
- 一个线程块消耗的共享内存越多,则在SM中可以同时处理的线程块就会变少
- 如果每个线程块使用共享内存数量变少,那么可以同时处理更多的线程块

延迟隐藏
GPU的指令延迟被其他线程束的计算隐藏 指令可以分为
- 算术指令
- 内存指令