
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
RAG
原始 RAG 流程
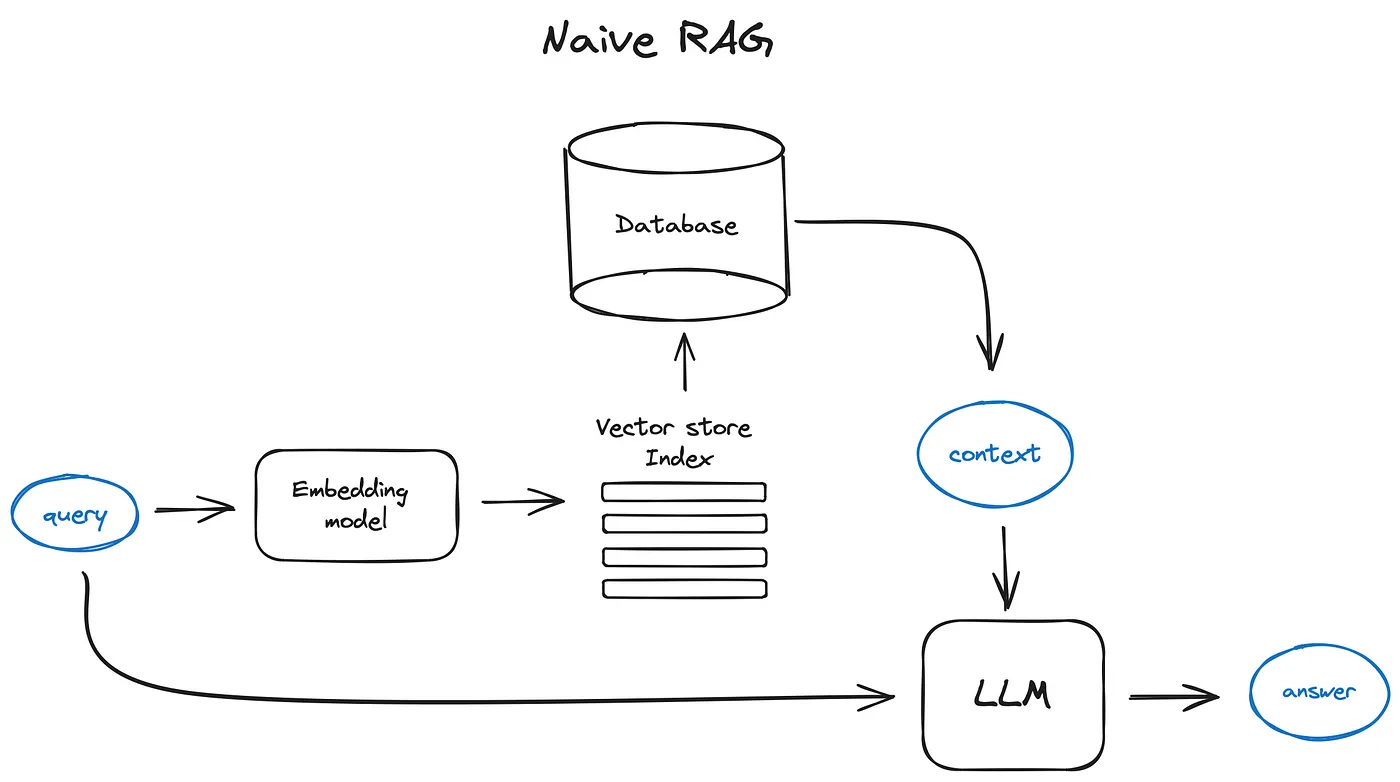
RAG prompt
def question_answering(context, query):
prompt = f"""
Give the answer to the user query delimited by triple backticks ```{query}```\
using the information given in context delimited by triple backticks ```{context}```.\
If there is no relevant information in the provided context, try to answer yourself,
but tell user that you did not have any relevant context to base your answer on.
Be concise and output the answer of size less than 80 tokens.
"""
response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
answer = response.choices[0].message["content"]
return answer
Adcanced RAG
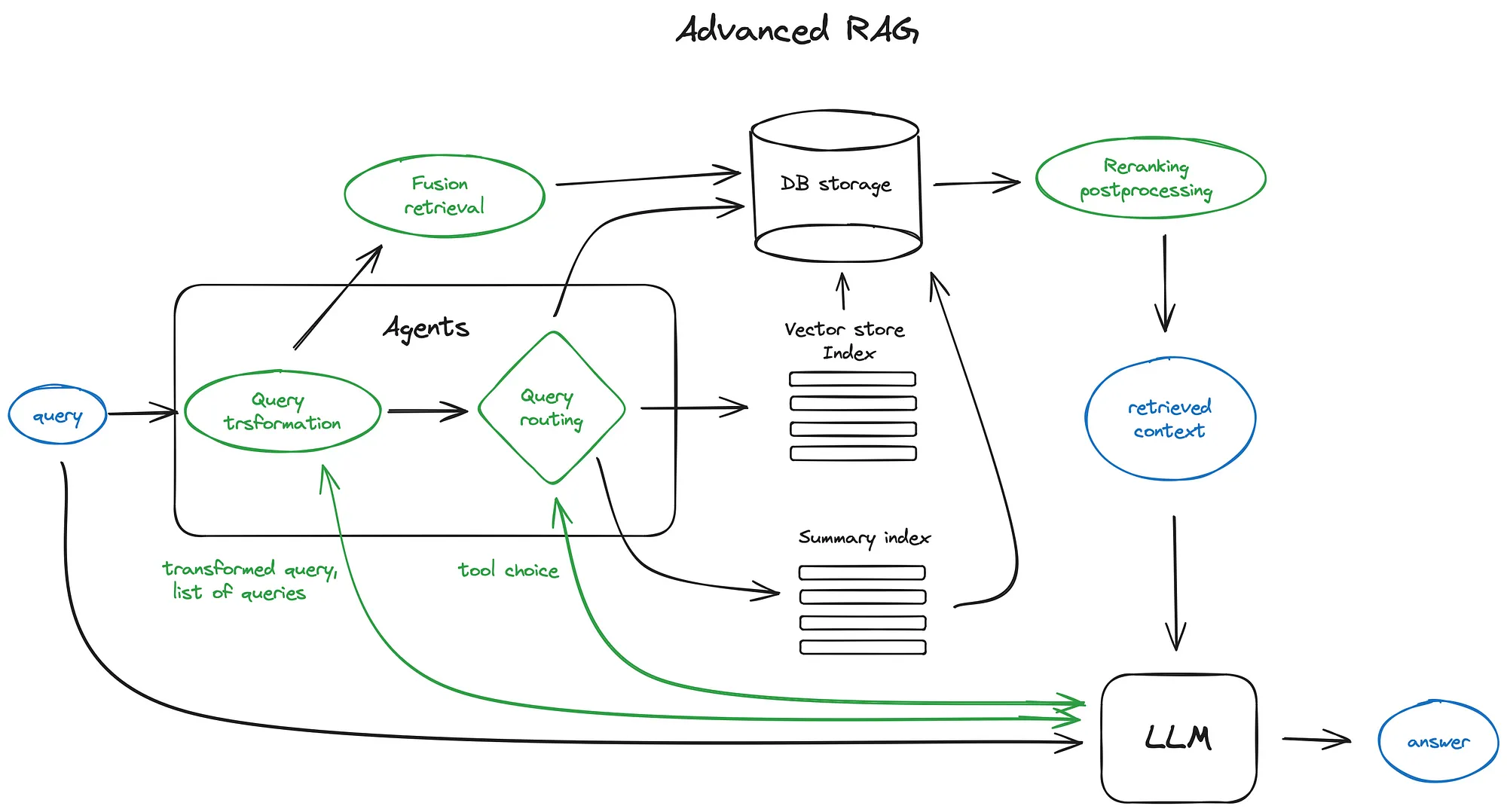
- chunking&vectorisation
1.1 chunking
Transformer 已经修复了输入过长序列无法表征有效向量的问题,所以先无损切块文档。 这里有很多方式可以完成改工作 这里需要考虑的参数是切块大小,这取决于嵌入模型和载入token的能力,标准的纯encoder类比如基于bert的只能塞入 512 token,openai ada–002可以处理8191token.这里建议利用LLM对文本嵌入方便搜索,在这里看详细的。以llamaindex为例,他这个玩意在NodeParser class 去定义划分器。
1.2 vectorisation
下一步选择模型去嵌入块,这里推荐搜索优化过的模型比如 beg-large或者 E5 嵌入家族,这里看最新的
- search index
2.1 vector store index
 关键步骤,建议用 flat index
适当的搜索索引,以在10000+元素尺度上进行有效检索的优化索引是faiss,nmslib或烦人的矢量索引,使用了一些近似最近的邻居实现,例如固定,树或HNSW算法。
关键步骤,建议用 flat index
适当的搜索索引,以在10000+元素尺度上进行有效检索的优化索引是faiss,nmslib或烦人的矢量索引,使用了一些近似最近的邻居实现,例如固定,树或HNSW算法。
还有托管解决方案,例如OpenSearch或Elasticsearch和Vector数据库,负责在引擎盖下的步骤1中描述的数据摄入pipeline,例如Pinecone,Weaviate或Chroma。
这玩意取决于你的索引选择,数据和搜索需要,你同样也可以通过向量储存元数据,然后用其过滤搜索
llamaindex支持许多向量储存索引,简单点的比如列表索引,树索引和关键词表索引,这个在后面的融合检索部分会提及
2.2 Hierarchical indices
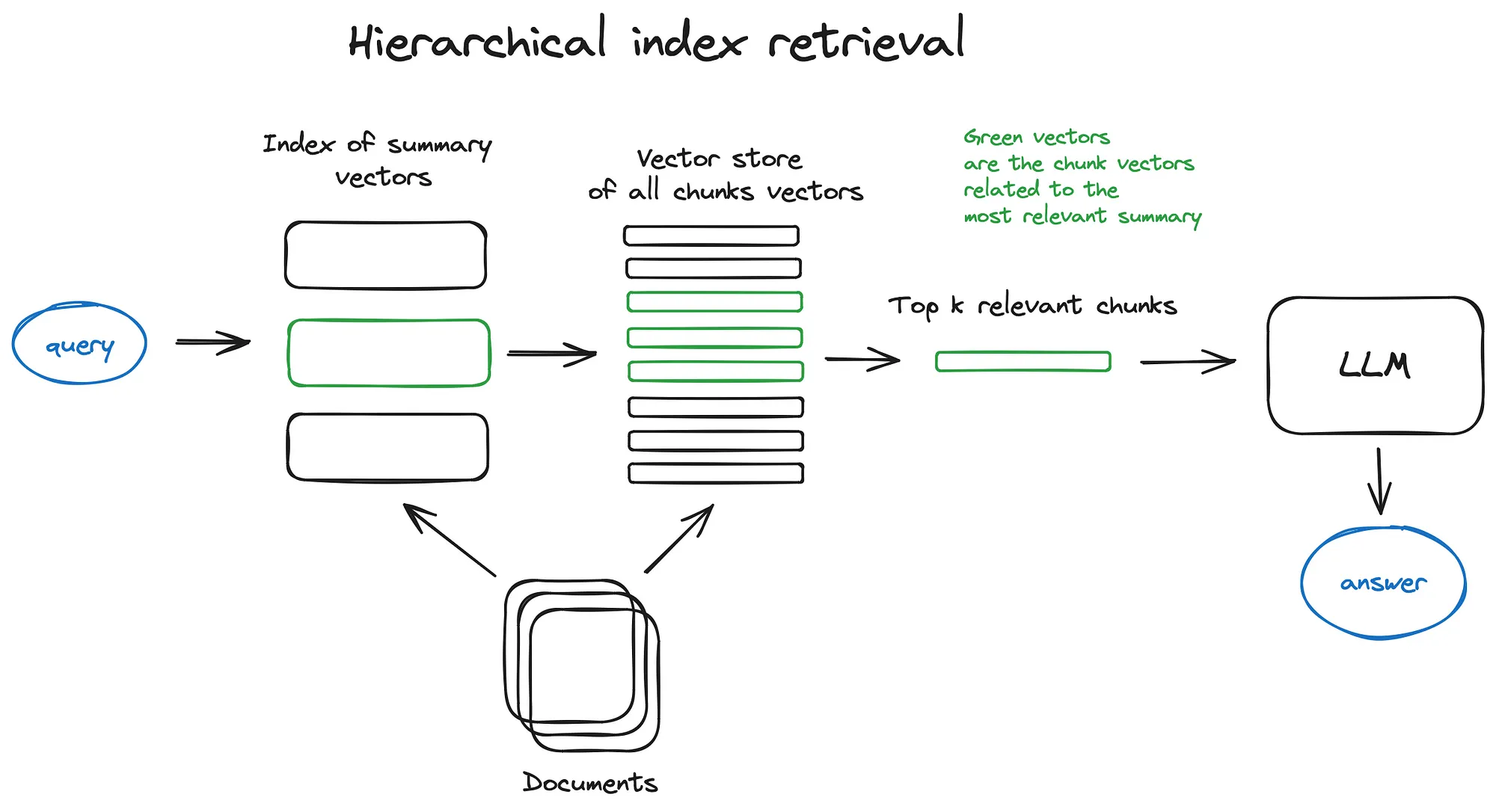
高效处理多文件方式就是创建两个索引 一个总结组成 一个文档块组成
并进行两步搜索 首先通过摘要滤除相关文档,然后在此相关组内搜索。
2.3 Hypothetical Questions and HyDE
还有个方法,用LLM对每个块生成问题,并将这些问题嵌入向量 这玩意保证质量,查询和假设问题之间的较高语义相似性
这里有个反向的方法,你用LLM生成假设答案用这个向量和问题向量一起提高搜索质量——这玩意叫HyDE
2.4 Context enrichment
这个是为检索微小块来提升质量,即通过LLM增加一些环境内容增强可解释性。 两个选择
- 扩句子
- 将文件递归地分成许多较大的父块,其中包含较小的子块。
2.4.1 句子窗口检索
在此方案中,单独嵌入文档中的每个句子,从而为上下文的余弦距离搜索提供了非常准确的准确性。

这个就是把绿色(相关答案)和黑色的上下文一块送入LLM
2.4.2 Auto-merging Retriever (aka Parent Document Retriever)
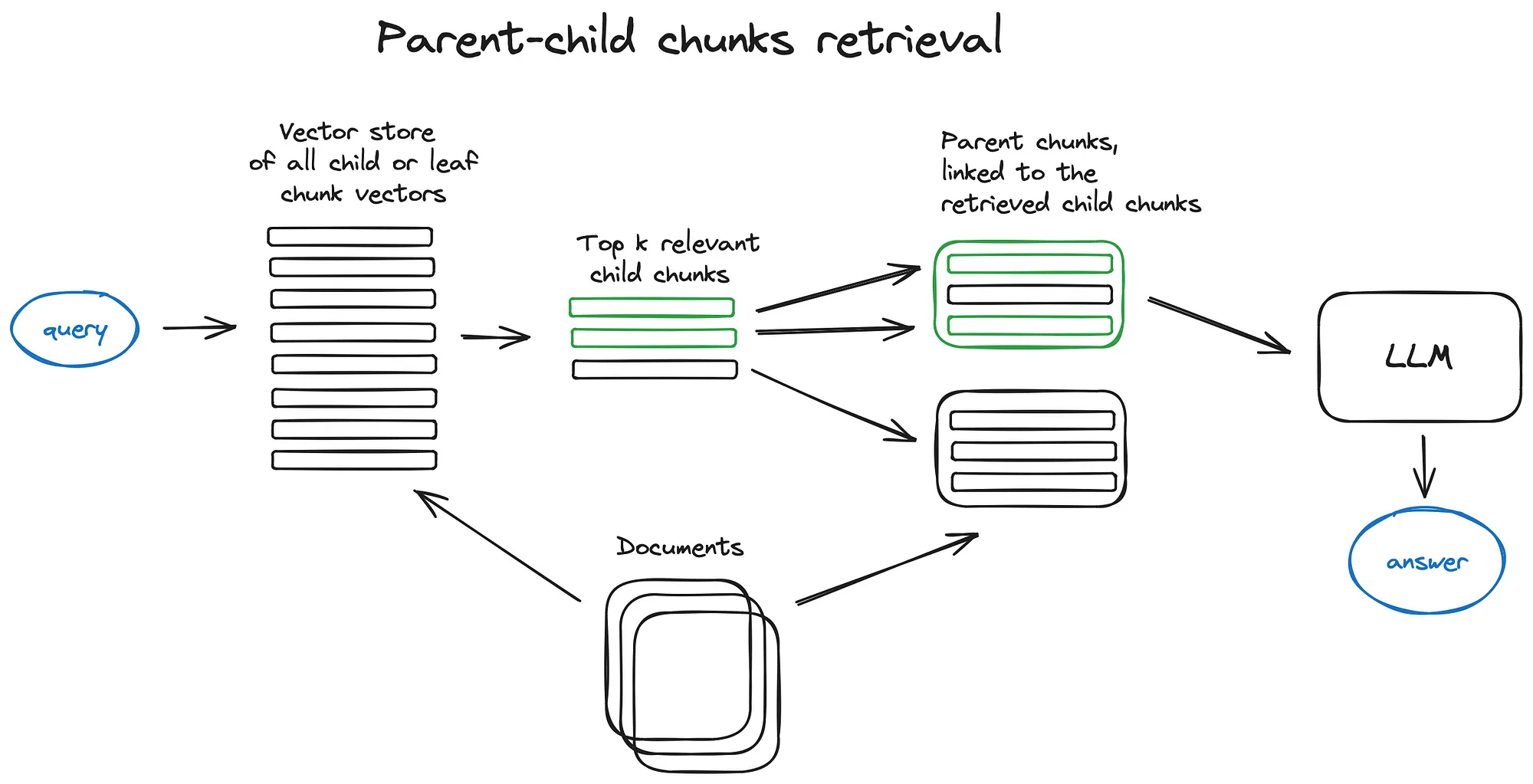
文件被拆分为块的层次结构,然后将最小的叶子块发送到索引。在检索时,我们取回K叶块,如果有n个块指的是同一父母块,我们将其替换为父母块,然后将其发送给LLM进行答案。
2.5 Fusion retrieval or hybrid search
Reciprocal Rank Fusion algorithm
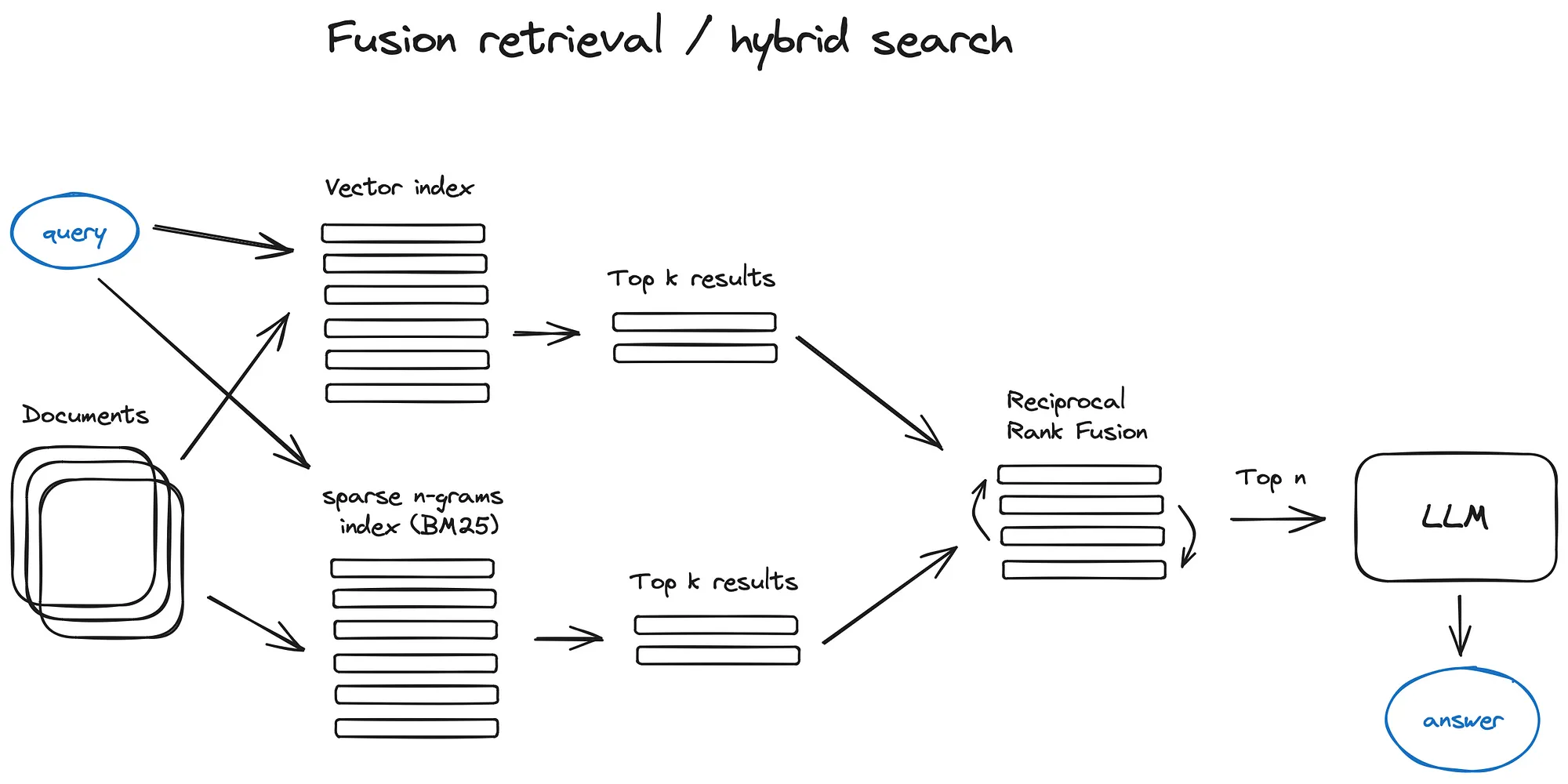
- Reranking & filtering
现在是时候通过过滤,重新排列或某些转换来完善它们了。
在LlamaIndex中,有各种可用的后处理器,可以根据相似度得分、关键词、元数据进行结果筛选,或者使用其他模型(如LLM、句子转换器交叉编码器、Cohere重新排名端点)进行重新排名,或者根据元数据(如日期的近期性)进行重新排名——基本上,你能想象到的都有。
这是送入LLM的最后一步了
下面是高阶技巧
- Query transformations
用作解释引擎来提升用户输入达到高质量检索的目的
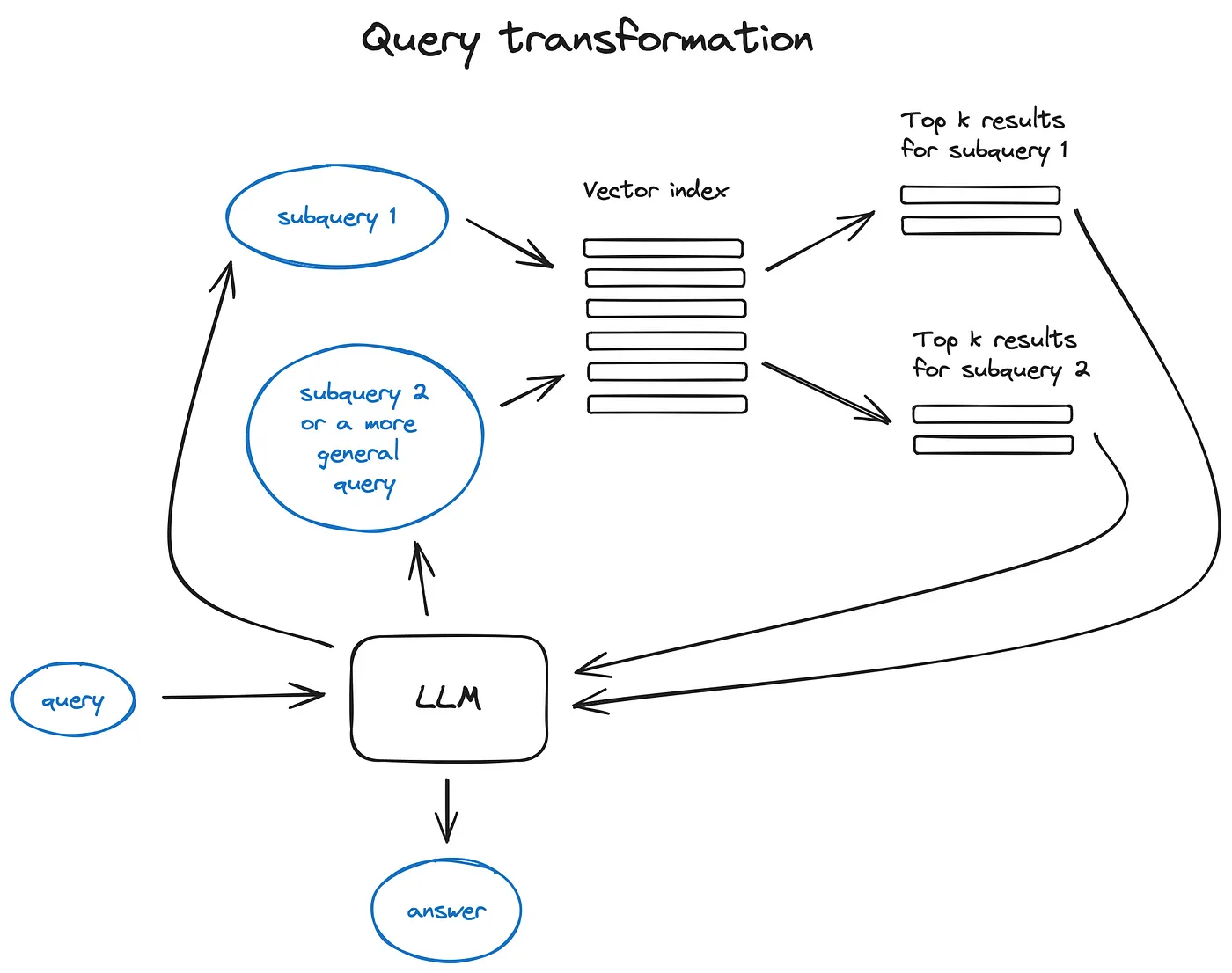
如果问的太复杂LLM也可以压缩 或者多级询问检索
- 生成更为抽象的问题
- 重写问题符合规范格式
文献引用
如何精准返回引用文献呢
- 插入引用任务到LLM让他返回使用文献的id
- 生成回答于原始文本对比索引
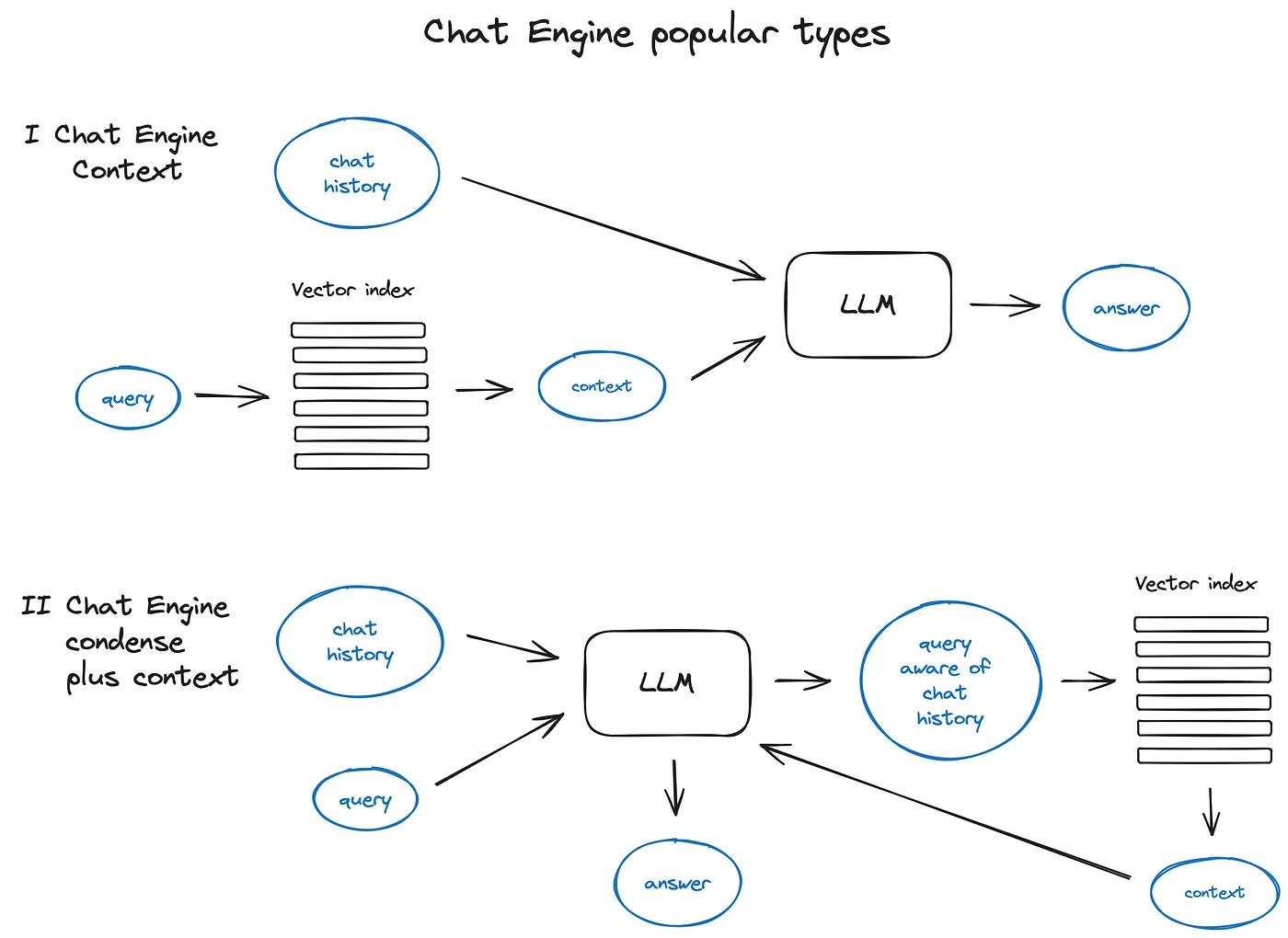
- Chat Engine
query compression technique 把多轮对话压缩送入
ContextChatEngine
- Query Routing
使用LLM调用执行路由选项的选择,以预定义的格式返回其结果,用于将查询路由到给定索引,或者,如果我们采用agnatic行为如下所示,如下所示。
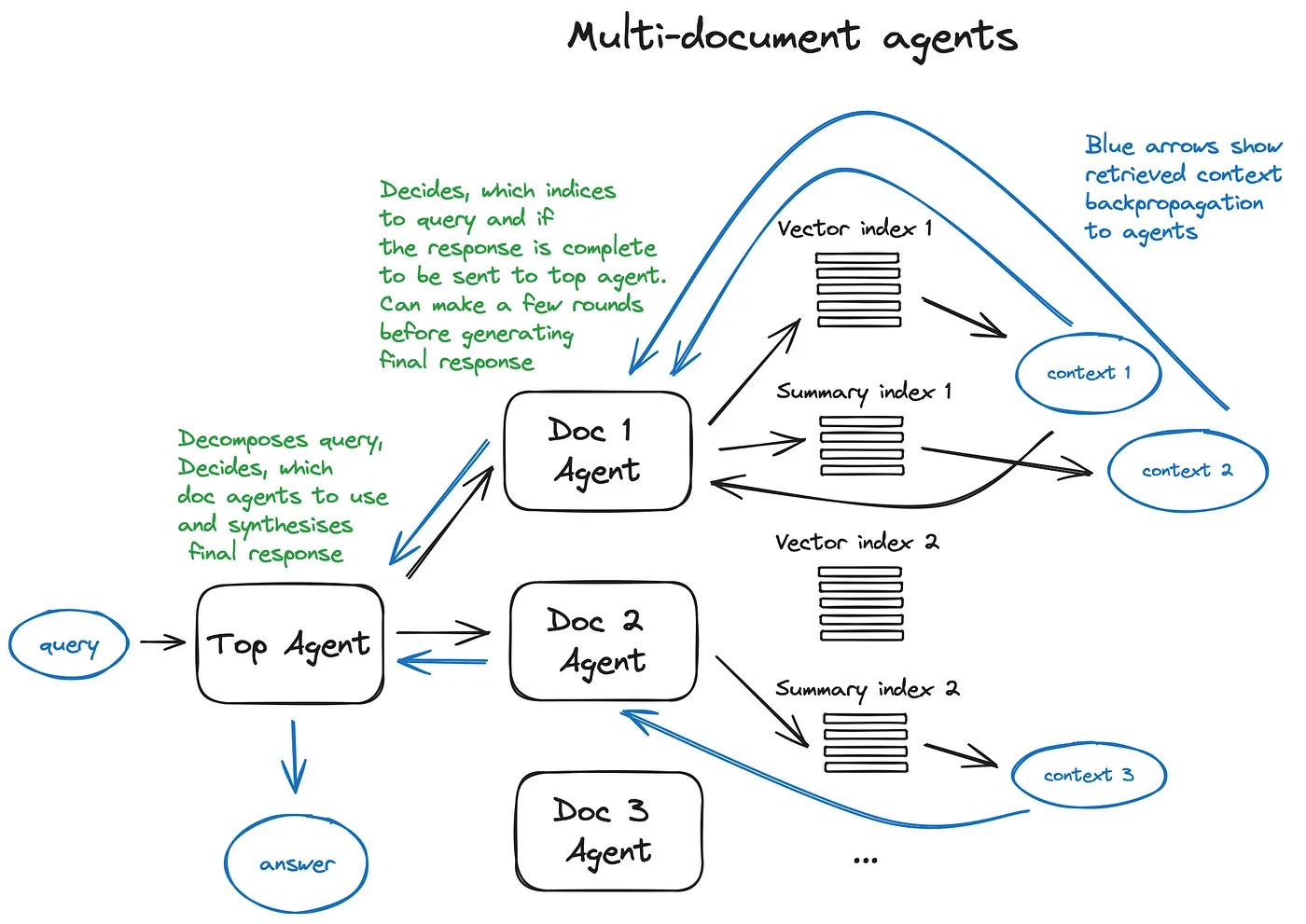
- Agents in RAG
-
OpenAI Assistants
-
function calling API
- Response synthesiser
-
通过将检索到的上下文发送给LLM块来迭代地完善答案
-
总结所检索的上下文以适合提示
-
根据不同上下文块生成多个答案,然后加成或总结它们
Encoder and LLM fine-tuning
- Encoder fine-tuning
- Ranker fine-tuning
- LLM fine-tuning
Evaluation
Ragas
前置学习建议
- 吴恩达的短课(RAG)
- OpenAI cookbook
- langchain-LangSmith
- LlamaIndex tutorial
其他考虑因素
- web search based RAG (RAGs by LlamaIndex, webLangChain, etc)
- taking a deeper dive into agentic architectures (and the recent OpenAI stake in this game)
- some ideas on LLMs Long-term memory
除了答案的相关性和准确性外,RAG系统的主要生产挑战是速度