
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
Audio course
合在一起
-
语音到语音翻译:将语音从一种语言翻译成不同语言的语音
-
创建语音助手:建立自己的语音助手,该助手以与Alexa或Siri相似的方式工作
-
抄录会议:抄录会议并将笔录标记与谁在
语音到语音翻译
STST or S2ST
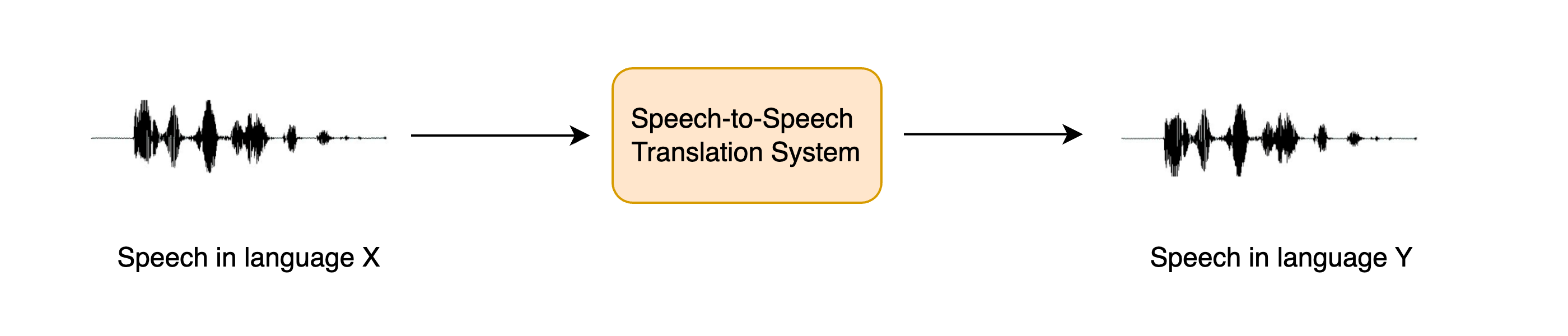
speech translation (ST) system

用三步达到目的
之前一般是 ASR + MT+ TTS
Speech translation
whisper 模型
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
用意大利语测试 VoxPopuli 数据集
from datasets import load_dataset
dataset = load_dataset("facebook/voxpopuli", "it", split="validation", streaming=True)
sample = next(iter(dataset))
看一下
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
定义函数
def translate(audio):
outputs = pipe(audio, max_new_tokens=256, generate_kwargs={"task": "translate"})
return outputs["text"]
再看一下
translate(sample["audio"].copy())
对比
sample["raw_text"]
Text to speech
加载 SpeechT5
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
model.to(device)
vocoder.to(device)
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
查看一下
speech = synthesise("Hey there! This is a test!")
Audio(speech, rate=16000)
6
创建 STST demo
import numpy as np
target_dtype = np.int16
max_range = np.iinfo(target_dtype).max
def speech_to_speech_translation(audio):
translated_text = translate(audio)
synthesised_speech = synthesise(translated_text)
synthesised_speech = (synthesised_speech.numpy() * max_range).astype(np.int16)
return 16000, synthesised_speech
sampling_rate, synthesised_speech = speech_to_speech_translation(sample["audio"])
Audio(synthesised_speech, rate=sampling_rate)
import gradio as gr
demo = gr.Blocks()
mic_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
file_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
with demo:
gr.TabbedInterface([mic_translate, file_translate], ["Microphone", "Audio File"])
demo.launch(debug=True)
创建语音助手
端到端的 Marvin 来了

- Wake word detection(唤醒词)
- Speech transcription(语音转写)
- Language model query(语言模型查询)
- Synthesise speech(语音合成)