
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
Audio course
文本转语音
- 适合的数据集
- 预训练模型
- 微调 SpeechT5
- 评估 TTS
TTS 数据集
-
LJSpeech
由13,100英文语言音频剪辑与相应的转录配对
-
Multilingual LibriSpeech
上面的多语言版本
-
VCTK (Voice Cloning Toolkit)
VCTK是专为文本到语音研究和开发而设计的数据集。它包含110位具有各种口音的英语说话者的录音。
-
Libri-TTS/ LibriTTS-R
Libri-tts/ libritts-r是由Heiga Zen在Google Speech和Google Brain Team成员的协助下制备的24kHz抽样率的多演讲者英语语料库,其英语读取率约为585小时。
好的数据集应该包含以下特征
-
高质量和多样化的记录涵盖了各种语音模式,口音,语言和情感。录音应清楚,没有背景噪声,并具有自然的语音特征。
-
抄录:每个录音都应伴随其相应的文本转录。
-
多种语言内容:数据集应包含多种语言内容,包括不同类型的句子,短语和单词。它应该涵盖各种主题,流派和领域,以确保模型处理不同语言环境的能力。
预训练模型
SpeechT5
微软出的,核心是6个特殊的 pre-nets 和 post-nets 的transformer
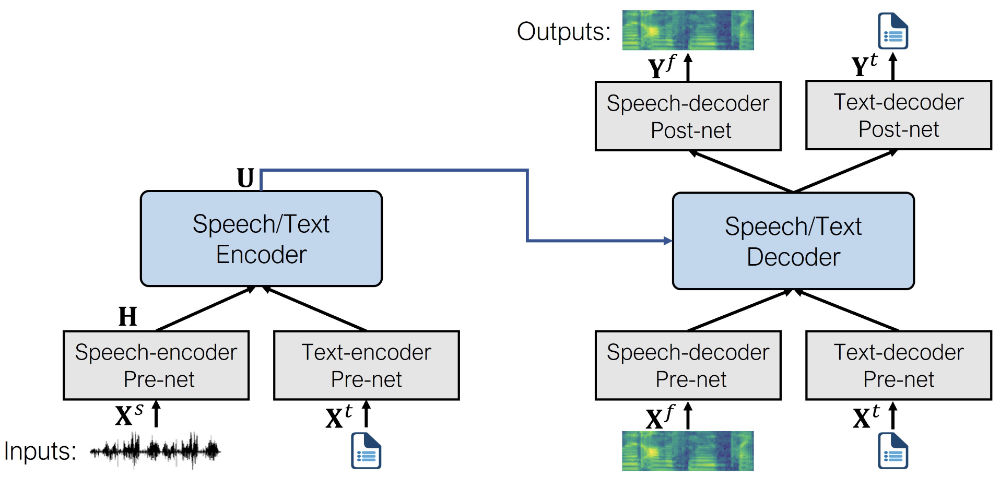
SpeechT5 是第一个用大规模无标记语音和文本数据的预训练模型
经过预训练后,整个 encoder-decoder 骨干网络会被根据下游任务进行微调,这块基本只动 pre-nets 和 post-nets
看一下这俩货具体咋用
-
文本编码器 pre-net:映射文本令牌的文本嵌入层与编码器期望的隐藏表示形式。这类似于NLP模型(例如BERT)中发生的情况。
-
语音解码器 pre-net:这将log Mel频谱图作为输入,并使用一系列线性层将频谱图压缩为隐藏表示形式。
-
语音解码器 post-net:这预测了一个残差,可以添加到输出谱图中,并用于完善结果。
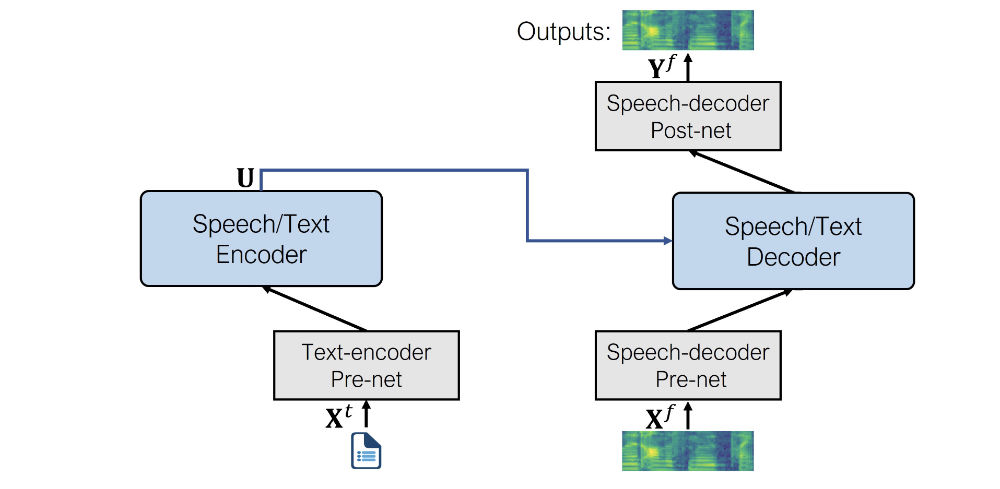
开始
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
token 化
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
这个 SpeechT5 TTS 是用一个 speaker embeddings 捕获某一个说话者的特征
常见生成嵌入技巧包括
- I-Vectors (identity vectors): 基于高斯混合模型 GMM,将说话的作为低维度定长向量从特定说话 GMM 中统计得到,作为无监督方式一种
- X-Vectors:用 DNNs 捕获说话者帧级别的时序信息
简单来说 X-Vectors 更牛逼
加载试试
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
说话的嵌入是一个 tensor ,维度是 1 x 512。现在生成频谱
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
输出是个 shape(140,80) 的张量,表示频谱图.第一个维度是序列长度,随着语音解码器的预内网始终将 drop out 应用于输入序列,它可能会有所不同。这为生成的语音增加了一些随机变化。
下面安装个 vocoder,基于 HIFI-GAN 模型。
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
穿个参数生成语音
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
听下结果
from IPython.display import Audio
Audio(speech, rate=16000)
Bark
由 Suno AI 的 transformer 架构文本转语音模型
相比于上面的,这个逼直接生成语音,不用推理时候单独搞一个 vocoder
这种效率是通过使用Encodec的利用来实现的,Encodec既是编解码器又是压缩工具。
具体来说 bark 有 4 种模式
- Barksemanticmodel(也称为“文本”模型):一种因果自回归 transformer 模型,它作为输入 token 化文本,并预测捕获文本含义的语义文本 token。
- BarkCoarsemodel(也称为“粗声”模型):一种因果自回旋 transformer,它以Barksemanticmodel模型的输入为输入。它旨在预测Eccodec所需的前两个音频代码手册。
- BarkfineModel(“良好的声学”模型),这次是一个非混合自动编码器 transformer,它迭代地根据以前的代码簿嵌入的总和来预测最后的代码簿。
- Bark从EncodeCmodel预测了所有代码簿频道后,使用它来解码输出音频数组。
bark 是个高度可控模型
加载模型
from transformers import BarkModel, BarkProcessor
model = BarkModel.from_pretrained("suno/bark-small")
processor = BarkProcessor.from_pretrained("suno/bark-small")
用法很多,可以生成条件声音
# add a speaker embedding
inputs = processor("This is a test!", voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()
也可以生成准备使用的多语言讲话
# try it in French, let's also add a French speaker embedding
inputs = processor("C'est un test!", voice_preset="v2/fr_speaker_1")
speech_output = model.generate(**inputs).cpu().numpy()
还能生成非语言交流,肢体交流声音
inputs = processor(
"[clears throat] This is a test ... and I just took a long pause.",
voice_preset="v2/fr_speaker_1",
)
speech_output = model.generate(**inputs).cpu().numpy()
还有音乐
inputs = processor(
"♪ In the mighty jungle, I'm trying to generate barks.",
)
speech_output = model.generate(**inputs).cpu().numpy()
同时能批处理前面所有
input_list = [
"[clears throat] Hello uh ..., my dog is cute [laughter]",
"Let's try generating speech, with Bark, a text-to-speech model",
"♪ In the jungle, the mighty jungle, the lion barks tonight ♪",
]
# also add a speaker embedding
inputs = processor(input_list, voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()
我们一个一个听
from IPython.display import Audio
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0], rate=sampling_rate)
Audio(speech_output[1], rate=sampling_rate)
Audio(speech_output[2], rate=sampling_rate)
Massive Multilingual Speech (MMS)
这玩意可以合成超过 1100 种语言
基于 VITS ,跟 bark 一样直接生成语音
from transformers import VitsModel, VitsTokenizer
model = VitsModel.from_pretrained("Matthijs/mms-tts-deu")
tokenizer = VitsTokenizer.from_pretrained("Matthijs/mms-tts-deu")
看个例子
text_example = (
"Ich bin Schnappi das kleine Krokodil, komm aus Ägypten das liegt direkt am Nil."
)
生成
import torch
inputs = tokenizer(text_example, return_tensors="pt")
input_ids = inputs["input_ids"]
with torch.no_grad():
outputs = model(input_ids)
speech = outputs["waveform"]
听一下
from IPython.display import Audio
Audio(speech, rate=16000)
6
微调 SpeechT5
提前检查
nvidia-smi
pip install transformers datasets soundfile speechbrain accelerate
from huggingface_hub import notebook_login
notebook_login()
数据集
Dutch (nl) language subset of the VoxPopuli dataset
from datasets import load_dataset, Audio
dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
len(dataset)
输出
20968
改下采样率
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
处理数据
from transformers import SpeechT5Processor
checkpoint = "microsoft/speecht5_tts"
processor = SpeechT5Processor.from_pretrained(checkpoint)
清洗
tokenizer = processor.tokenizer
看一下
dataset[0]
输出
{'audio_id': '20100210-0900-PLENARY-3-nl_20100210-09:06:43_4',
'language': 9,
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/02ec6a19d5b97c03e1379250378454dbf3fa2972943504a91c7da5045aa26a89/train_part_0/20100210-0900-PLENARY-3-nl_20100210-09:06:43_4.wav',
'array': array([ 4.27246094e-04, 1.31225586e-03, 1.03759766e-03, ...,
-9.15527344e-05, 7.62939453e-04, -2.44140625e-04]),
'sampling_rate': 16000},
'raw_text': 'Dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'normalized_text': 'dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'gender': 'female',
'speaker_id': '1122',
'is_gold_transcript': True,
'accent': 'None'}
def extract_all_chars(batch):
all_text = " ".join(batch["normalized_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = dataset.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=dataset.column_names,
)
dataset_vocab = set(vocabs["vocab"][0])
tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
看一下两个集合的差异
dataset_vocab - tokenizer_vocab
输出
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
把这些 tokenizer 没有的符号做个映射
replacements = [
("à", "a"),
("ç", "c"),
("è", "e"),
("ë", "e"),
("í", "i"),
("ï", "i"),
("ö", "o"),
("ü", "u"),
]
def cleanup_text(inputs):
for src, dst in replacements:
inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
return inputs
dataset = dataset.map(cleanup_text)
确定讲话者
from collections import defaultdict
speaker_counts = defaultdict(int)
for speaker_id in dataset["speaker_id"]:
speaker_counts[speaker_id] += 1
画个图看一下
import matplotlib.pyplot as plt
plt.figure()
plt.hist(speaker_counts.values(), bins=20)
plt.ylabel("Speakers")
plt.xlabel("Examples")
plt.show()
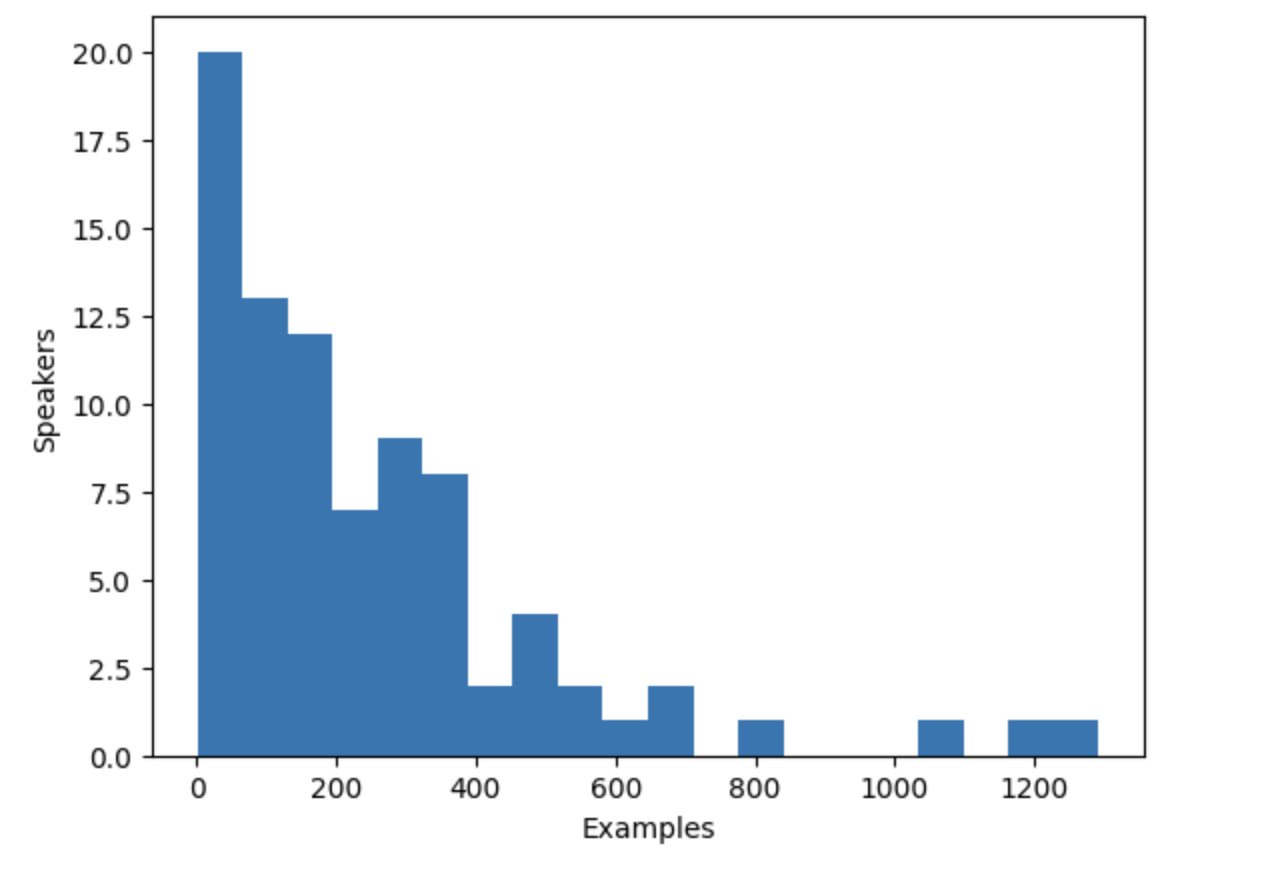
把讲话的人限制在100-400样例之间
def select_speaker(speaker_id):
return 100 <= speaker_counts[speaker_id] <= 400
dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
还剩多少说话的人
len(set(dataset["speaker_id"]))
输出
42
看下还剩多少例子
len(dataset)
输出
9973
嵌入,speaker embeddings
创建一个函数create_speaker_embedding(),该函数采用输入音频波形并输出512个元素向量,其中包含相应的speaker embeddings
import os
import torch
from speechbrain.pretrained import EncoderClassifier
spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
device = "cuda" if torch.cuda.is_available() else "cpu"
speaker_model = EncoderClassifier.from_hparams(
source=spk_model_name,
run_opts={"device": device},
savedir=os.path.join("/tmp", spk_model_name),
)
def create_speaker_embedding(waveform):
with torch.no_grad():
speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
return speaker_embeddings
记得训练自己的 X-vector model
加载
def prepare_dataset(example):
audio = example["audio"]
example = processor(
text=example["normalized_text"],
audio_target=audio["array"],
sampling_rate=audio["sampling_rate"],
return_attention_mask=False,
)
# strip off the batch dimension
example["labels"] = example["labels"][0]
# use SpeechBrain to obtain x-vector
example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
return example
确认
processed_example = prepare_dataset(dataset[0])
list(processed_example.keys())
输出
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']
processed_example["speaker_embeddings"].shape
输出
(512,)
标签应为带有80个MEL垃圾箱的log-Mel光谱图。
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(processed_example["labels"].T)
plt.show()
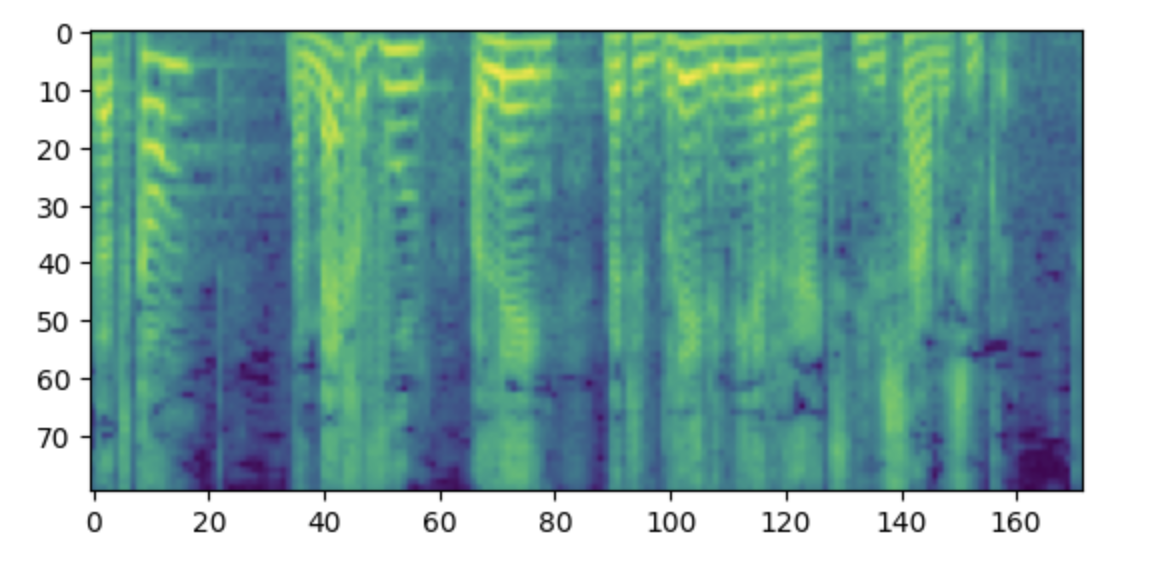
dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
def is_not_too_long(input_ids):
input_length = len(input_ids)
return input_length < 200
dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
len(dataset)
输出
8259
切片
dataset = dataset.train_test_split(test_size=0.1)
Data collator
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class TTSDataCollatorWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
label_features = [{"input_values": feature["labels"]} for feature in features]
speaker_features = [feature["speaker_embeddings"] for feature in features]
# collate the inputs and targets into a batch
batch = processor.pad(
input_ids=input_ids, labels=label_features, return_tensors="pt"
)
# replace padding with -100 to ignore loss correctly
batch["labels"] = batch["labels"].masked_fill(
batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100
)
# not used during fine-tuning
del batch["decoder_attention_mask"]
# round down target lengths to multiple of reduction factor
if model.config.reduction_factor > 1:
target_lengths = torch.tensor(
[len(feature["input_values"]) for feature in label_features]
)
target_lengths = target_lengths.new(
[
length - length % model.config.reduction_factor
for length in target_lengths
]
)
max_length = max(target_lengths)
batch["labels"] = batch["labels"][:, :max_length]
# also add in the speaker embeddings
batch["speaker_embeddings"] = torch.tensor(speaker_features)
return batch
data_collator = TTSDataCollatorWithPadding(processor=processor)
训练
from transformers import SpeechT5ForTextToSpeech
model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)
from functools import partial
# disable cache during training since it's incompatible with gradient checkpointing
model.config.use_cache = False
# set language and task for generation and re-enable cache
model.generate = partial(model.generate, use_cache=True)
定义超参数
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=2,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
greater_is_better=False,
label_names=["labels"],
push_to_hub=True,
)
训练
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
data_collator=data_collator,
tokenizer=processor,
)
trainer.train()
上传
trainer.push_to_hub()
推理
model = SpeechT5ForTextToSpeech.from_pretrained(
"YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl"
)
example = dataset["test"][304]
speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
inputs = processor(text=text, return_tensors="pt")
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
from IPython.display import Audio
Audio(speech.numpy(), rate=16000)
评估模型
MSE 或者 MAE 在频谱阶段都可以,但TTS 是个一对多匹配问题,所以会更复杂一些
不想别的可以依赖混淆矩阵或精度精确性之类的,TTS很依赖人来分析
常用 MOS( mean opinion scores),一种主观评分 1-5
subjective nature of speech perception