
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
Audio course
自动语音识别
预训练模型
说一下 CTC 模型的问题
先加载 LibriSpeech ASR 的一个小节来展现 Wav2Vec2 语音转脚本能力
from datasets import load_dataset
dataset = load_dataset(
"hf-internal-testing/librispeech_asr_dummy", "clean", split="validation"
)
dataset
输出
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})
我们挑其中 73 个中的一个音频并检查脚本:
from IPython.display import Audio
sample = dataset[2]
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
输出
HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
6,现在把微调好的检查点通过 pipeline 加载
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-100h")
下面从数据集拿一个例子并把原始数据传给pipeline。注意传进去数据就变了,为了多次利用同一个数据,穿copy进去。
pipe(sample["audio"].copy())
输出
{"text": "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"}
看起来 wav2vec2 还行,对比看一下区别
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH **CHRISTMAUS** AND **ROSE** BEEF LOOMING BEFORE US **SIMALYIS** DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
看起来有一些拼写错误,比如
- CHRISTMAUS vs. CHRISTMAS
- ROSE vs. ROAST
- SIMALYIS vs. SIMILES
CTC 模型就这毛病,容易语音拼错。我们在预测中还缺失两个重要特性:单词大小写和标点符号,这限制了模型转录在实际应用中的有用性。
转向 Seq2seq 模型
首先讲一下缺点
- 慢
- 需要大量标注数据
“VRAM”表示运行模型所需的 GPU 内存,最小批量大小为 1。”Rel Speed”是检查点相对于最大模型的速度。根据这些信息,你可以选择最适合你硬件的检查点。
| 大小 | 参数 | VRAM/GB | Rel Speed | 只有英语 | 多语种 |
|---|---|---|---|---|---|
| tiny | 39M | 1.4 | 32 | √ | √ |
| base | 74M | 1.5 | 16 | √ | √ |
| small | 224M | 2.3 | 6 | √ | √ |
| medium | 769M | 4.2 | 2 | √ | √ |
| large | 1550M | 7.5 | 1 | × | √ |
我们加载一下 Whisper base 的检查点,与之前的 Wav2Vec2 差不多大。优先多语言模式
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
6 ,让我们再转义一下之前的声音,改一下 max_new_tokens 参数
pipe(sample["audio"], max_new_tokens=256)
输出
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.'}
老样子再对比一下
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: He tells us that at this festive season of the year, with **Christmas** and **roast** beef looming before us, **similarly** is drawn from eating and its results occur most readily to the mind.
好太多了,有大小写,不会造词,6.
换个多语言玩玩
Multilingual LibriSpeech (MLS) dataset
dataset = load_dataset(
"facebook/multilingual_librispeech", "spanish", split="validation", streaming=True
)
sample = next(iter(dataset))
老规矩检查脚本听一个片段
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
输出
entonces te delelitarás en jehová y yo te haré subir sobre las alturas de la tierra y te daré á comer la heredad de jacob tu padre porque la boca de jehová lo ha hablado
pipe(sample["audio"].copy(), max_new_tokens=256, generate_kwargs={"task": "transcribe"})
输出
{'text': ' Entonces te deleitarás en Jehová y yo te haré subir sobre las alturas de la tierra y te daré a comer la heredad de Jacob tu padre porque la boca de Jehová lo ha hablado.'}
设置一下任务,以免变成生成而非翻译
pipe(sample["audio"], max_new_tokens=256, generate_kwargs={"task": "translate"})
输出
{'text': ' So you will choose in Jehovah and I will raise you on the heights of the earth and I will give you the honor of Jacob to your father because the voice of Jehovah has spoken to you.'}
长文本转义和时间戳
之前都是处理低于 30s 的,但 whisper 可以处理更长
现在我们从数据集里面造一个 5min的
import numpy as np
target_length_in_m = 5
# convert from minutes to seconds (* 60) to num samples (* sampling rate)
sampling_rate = pipe.feature_extractor.sampling_rate
target_length_in_samples = target_length_in_m * 60 * sampling_rate
# iterate over our streaming dataset, concatenating samples until we hit our target
long_audio = []
for sample in dataset:
long_audio.extend(sample["audio"]["array"])
if len(long_audio) > target_length_in_samples:
break
long_audio = np.asarray(long_audio)
# how did we do?
seconds = len(long_audio) / 16000
minutes, seconds = divmod(seconds, 60)
print(f"Length of audio sample is {minutes} minutes {seconds:.2f} seconds")
输出
Length of audio sample is 5.0 minutes 17.22 seconds
直接给模型前向传播有俩问题
- 模型会自动裁掉30s以上的
- 容易爆显存 OOM
所以需要把音频分成多个小段,然后分别喂给模型。每一段都有重叠部分。这使我们能够在边界上准确地将片段拼接在一起,因为我们可以找到片段之间的重叠部分,并相应地合并转录文本。
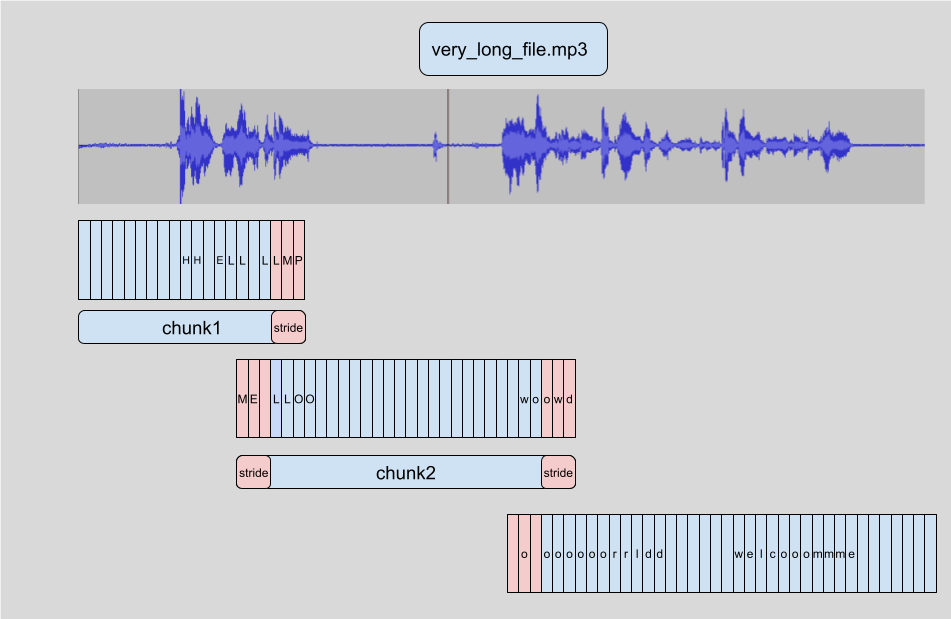
加个参数
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
)
输出
{'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la
heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos
como bejas, cada cual se apartó por su camino, mas Jehová cargó en él el pecado de todos nosotros...
太长了就不全打出来看了,在 16G V100的机器上,要3.45s的推理时间。 317s采样。换到 CPU要30s运行
Whisper 还能够预测音频数据的片段级时间戳。
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
return_timestamps=True,
)["chunks"]
输出
[{'timestamp': (0.0, 26.4),
'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos como bejas, cada cual se apartó por su camino,'},
{'timestamp': (26.4, 32.48),
'text': ' mas Jehová cargó en él el pecado de todos nosotros. No es que partas tu pan con el'},
{'timestamp': (32.48, 38.4),
'text': ' hambriento y a los hombres herrantes metas en casa, que cuando vieres al desnudo lo cubras y no'},
...
### 选择数据集
先理解一下数据集的特征
- 小时数量,不一定越长越好。种类越多越好
- 领域,包括哪来的,都是要匹配的。例如:如果我们在 audiobooks 中训练我们的模型,那么我们不能期望它在嘈杂的环境中表现良好。
- 声音风格
大致分两类
- 讲述型:正式朗读
- 自然发生:随便说话 第一个错误更少,然而,对于自发演讲,更口语化的演讲风格,包括重复、犹豫和错误
- 脚本风格 就是有没有大小写和标点符号
下面是仓库有的
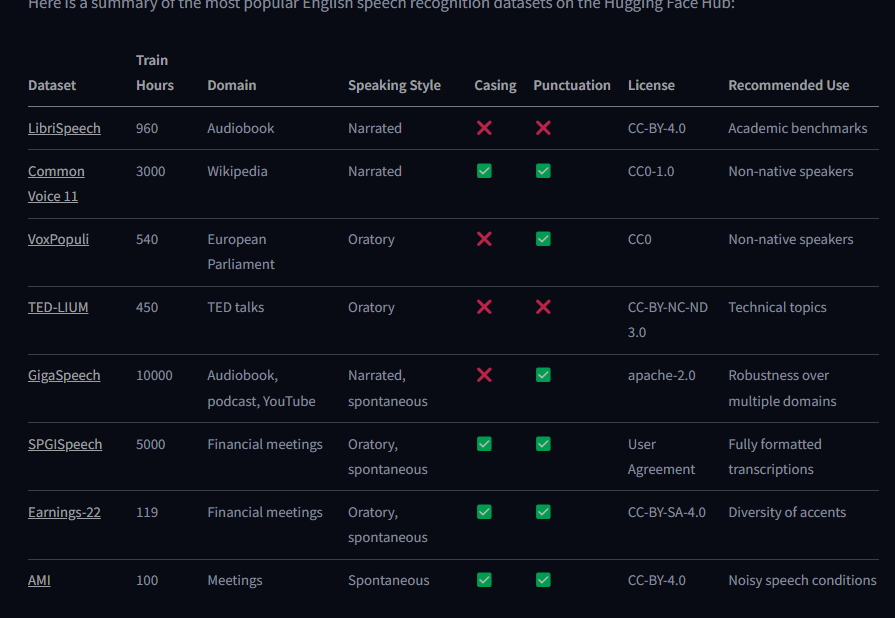
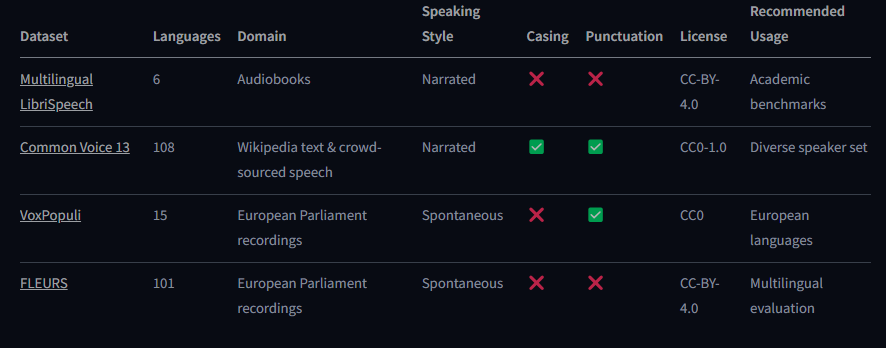
Common Voice 13
Common Voice 13 是一个众包数据集,其中发言者以各种语言录制维基百科的文本。
ASR 评估指标
跟 NLP 中的 Levenshtein distance 类似
先说一下错误吧,大致三类
- S 替换:我们在预测中转录错误的单词(“坐着”而不是“ sat”)
- I 插入(i):我们在预测中添加一个额外的单词
- D 删除(d):我们在预测中删除一个单词
可以从单词角度也可以从字符角度算
举个例子
真实文本:
reference = "the cat sat on the mat"
预测
prediction = "the cat sit on the"
WER

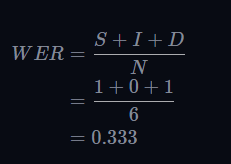
WER 越低越好
看一下咋掉包计算
pip install --upgrade evaluate jiwer
6
from evaluate import load
wer_metric = load("wer")
wer = wer_metric.compute(references=[reference], predictions=[prediction])
print(wer)
输出
0.3333333333333333
WER 没有上线的,比如预测10个中的2个,全错了,WER=500%
Word Accuracy
WAcc=1−WER
Character Error Rate
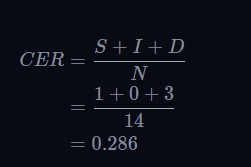
从子的角度
该选那个指标
大部分推荐 WER,除了像中文日语这类字符推荐用CER
正则化
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
prediction = " He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind."
normalized_prediction = normalizer(prediction)
normalized_prediction
输出
' he tells us that at this festive season of the year with christmas and roast beef looming before us similarly is drawn from eating and its results occur most readily to the mind '
6 计算一下正则WER
reference = "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"
normalized_referece = normalizer(reference)
wer = wer_metric.compute(
references=[normalized_referece], predictions=[normalized_prediction]
)
wer
输出
0.0625
整合一下
from transformers import pipeline
import torch
if torch.cuda.is_available():
device = "cuda:0"
torch_dtype = torch.float16
else:
device = "cpu"
torch_dtype = torch.float32
pipe = pipeline(
"automatic-speech-recognition",
model="openai/whisper-small",
torch_dtype=torch_dtype,
device=device,
)
from huggingface_hub import notebook_login
notebook_login()
from datasets import load_dataset
common_voice_test = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="test"
)
from tqdm import tqdm
from transformers.pipelines.pt_utils import KeyDataset
all_predictions = []
# run streamed inference
for prediction in tqdm(
pipe(
KeyDataset(common_voice_test, "audio"),
max_new_tokens=128,
generate_kwargs={"task": "transcribe"},
batch_size=32,
),
total=len(common_voice_test),
):
all_predictions.append(prediction["text"])
from evaluate import load
wer_metric = load("wer")
wer_ortho = 100 * wer_metric.compute(
references=common_voice_test["sentence"], predictions=all_predictions
)
wer_ortho
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
# compute normalised WER
all_predictions_norm = [normalizer(pred) for pred in all_predictions]
all_references_norm = [normalizer(label) for label in common_voice_test["sentence"]]
# filtering step to only evaluate the samples that correspond to non-zero references
all_predictions_norm = [
all_predictions_norm[i]
for i in range(len(all_predictions_norm))
if len(all_references_norm[i]) > 0
]
all_references_norm = [
all_references_norm[i]
for i in range(len(all_references_norm))
if len(all_references_norm[i]) > 0
]
wer = 100 * wer_metric.compute(
references=all_references_norm, predictions=all_predictions_norm
)
wer
微调 ASR 模型
微调 whisper 来做语音识别
数据集 Common voice 13 小版本轻量
16G+T4GPU
加载数据集
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="train+validation"
)
common_voice["test"] = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="test"
)
print(common_voice)
输出
DatasetDict({
train: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment', 'variant'],
num_rows: 4904
})
test: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment', 'variant'],
num_rows: 2212
})
})
选择自己需要的信息
common_voice = common_voice.select_columns(["audio", "sentence"])
数据预处理(特征提取,token 化, 加载)
ASR pipeline可以分为三个阶段:
-
功能提取器将原始音频输入预处理到log-mel频谱图
-
执行 seq2seq 映射的模型
-
后处理预测 token 的标记仪
我们可以通过导入语言列表来看到Whisper支持的所有可能的语言:
from transformers.models.whisper.tokenization_whisper import TO_LANGUAGE_CODE
TO_LANGUAGE_CODE
我们需要采取的措施来微调一种新语言的语言,就是找到了预先训练的语言。Dhivehi的Wikipedia文章指出,Dhivehi与斯里兰卡的僧伽罗语密切相关。如果我们再次检查语言代码,我们可以看到僧伽罗人在窃窃私语中存在,因此我们可以安全地将语言论点设置为“僧伽罗人”。
from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained(
"openai/whisper-small", language="sinhalese", task="transcribe"
)
预处理数据
挑一个先看看
common_voice["train"].features
输出
{'audio': Audio(sampling_rate=48000, mono=True, decode=True, id=None),
'sentence': Value(dtype='string', id=None)}
from datasets import Audio
sampling_rate = processor.feature_extractor.sampling_rate
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=sampling_rate))
def prepare_dataset(example):
audio = example["audio"]
example = processor(
audio=audio["array"],
sampling_rate=audio["sampling_rate"],
text=example["sentence"],
)
# compute input length of audio sample in seconds
example["input_length"] = len(audio["array"]) / audio["sampling_rate"]
return example
common_voice = common_voice.map(
prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=1
)
max_input_length = 30.0
def is_audio_in_length_range(length):
return length < max_input_length
common_voice["train"] = common_voice["train"].filter(
is_audio_in_length_range,
input_columns=["input_length"],
)
common_voice["train"]
输出
Dataset({
features: ['input_features', 'labels', 'input_length'],
num_rows: 4904
})
训练和评估
- 定义 data collator
- 评估指标
- 加载预训练检查点
- 定义训练参数
Define a Data Collator
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [
{"input_features": feature["input_features"][0]} for feature in features
]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(
labels_batch.attention_mask.ne(1), -100
)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
初始化
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
评估指标
import evaluate
metric = evaluate.load("wer")
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = processor.tokenizer.pad_token_id
# we do not want to group tokens when computing the metrics
pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)
label_str = processor.batch_decode(label_ids, skip_special_tokens=True)
# compute orthographic wer
wer_ortho = 100 * metric.compute(predictions=pred_str, references=label_str)
# compute normalised WER
pred_str_norm = [normalizer(pred) for pred in pred_str]
label_str_norm = [normalizer(label) for label in label_str]
# filtering step to only evaluate the samples that correspond to non-zero references:
pred_str_norm = [
pred_str_norm[i] for i in range(len(pred_str_norm)) if len(label_str_norm[i]) > 0
]
label_str_norm = [
label_str_norm[i]
for i in range(len(label_str_norm))
if len(label_str_norm[i]) > 0
]
wer = 100 * metric.compute(predictions=pred_str_norm, references=label_str_norm)
return {"wer_ortho": wer_ortho, "wer": wer}
加载预训练检查点
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
from functools import partial
# disable cache during training since it's incompatible with gradient checkpointing
model.config.use_cache = False
# set language and task for generation and re-enable cache
model.generate = partial(
model.generate, language="sinhalese", task="transcribe", use_cache=True
)
定义参数
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-dv", # name on the HF Hub
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5,
lr_scheduler_type="constant_with_warmup",
warmup_steps=50,
max_steps=500, # increase to 4000 if you have your own GPU or a Colab paid plan
gradient_checkpointing=True,
fp16=True,
fp16_full_eval=True,
evaluation_strategy="steps",
per_device_eval_batch_size=16,
predict_with_generate=True,
generation_max_length=225,
save_steps=500,
eval_steps=500,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor,
)
训练
trainer.train()
上传
kwargs = {
"dataset_tags": "mozilla-foundation/common_voice_13_0",
"dataset": "Common Voice 13", # a 'pretty' name for the training dataset
"language": "dv",
"model_name": "Whisper Small Dv - Sanchit Gandhi", # a 'pretty' name for your model
"finetuned_from": "openai/whisper-small",
"tasks": "automatic-speech-recognition",
}
trainer.push_to_hub(**kwargs)
Gradio 建 demo
from transformers import pipeline
model_id = "sanchit-gandhi/whisper-small-dv" # update with your model id
pipe = pipeline("automatic-speech-recognition", model=model_id)
def transcribe_speech(filepath):
output = pipe(
filepath,
max_new_tokens=256,
generate_kwargs={
"task": "transcribe",
"language": "sinhalese",
}, # update with the language you've fine-tuned on
chunk_length_s=30,
batch_size=8,
)
return output["text"]
import gradio as gr
demo = gr.Blocks()
mic_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.outputs.Textbox(),
)
file_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.outputs.Textbox(),
)
with demo:
gr.TabbedInterface(
[mic_transcribe, file_transcribe],
["Transcribe Microphone", "Transcribe Audio File"],
)
demo.launch(debug=True)