
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
Audio course
transformer 架构音频
Transformer 工作原理

- 编码器
- 解码器
只用编码器的(适合理解输入,比如分类任务,像 BERT 模型)
只用解码器的(适合生成任务)比如 GPT2
模型核心在于注意力层
用 Transformer 做音频
![]()
作为音频任务
输入和输出用音频替代文本
- ASR: 输入声音,输出文本
- 语音合成 TTS:输入文本,输出声音
- 声音分类:输入声音,输出类别概率
- 声音转换或声音提升:输入声音,输出声音
原始格式,从音频 wavefrom ,转换成频谱
模型输入
输入可以是音频或文本,目标是转换成可以用于 transformer 处理的嵌入向量
文本输入
文转语音模型,文本作为输入。跟其他 NLP 模型一样,输入首先 token 化,各个序列 token。送人嵌入层转换 token 到 512 维的向量。再传入 transformer 编码器。
音频输入
也是先专成嵌入向量。
Wav2Vec2 和 HuBERT 都是直接输入音频到模型,音频格式是一维序列浮点数,每一个数代表给定时间的采样振幅。原始音频首先正则化到零均值和单元方差,帮助从不同列标准化音频采样
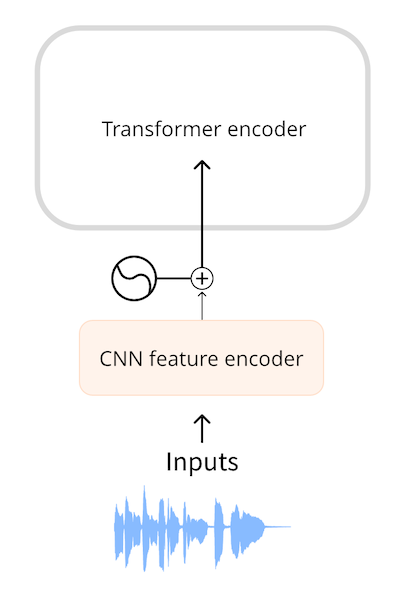
正则化后采样序列用一个小卷积神经网络转化成嵌入,或者叫特征编码器。每个卷积层处理输入序列并子采样音频(保证长度),指导卷积层最终输出一个 512 向量,每一个嵌入 25ms 的音频。这样 transformer 才能正常处理数据。
频谱输入
wavefrom并不是最高效的输入格式,通过使用频谱图,我们获得了相同数量的信息,但以更加压缩的形式获得。
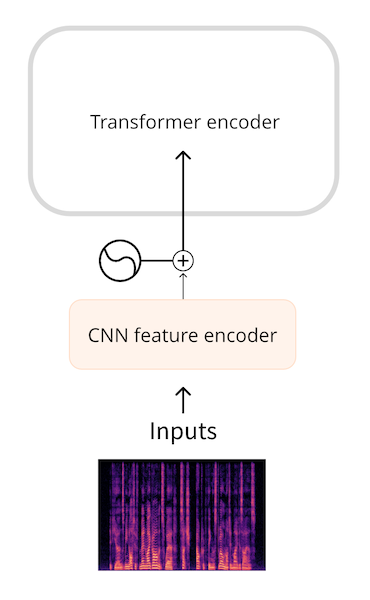
像 whisper 首先把 waveform 转换为 log-mel 频谱。这玩意总是把音频分割成30s片段,每个片段(80,3000),80 是mel bins 的数量,3000是每个片段的长度。
模型输出
文本输出
通过添加语言模型的头,通常一个线性层后面跟一个 softmax 作为输出预测下一个词
频谱输出
像 TTS,添加可以处理语音序列的层。生成一个频谱并使用额外的神经网络,比如 vocoder,把频谱转成音频。
再 SpeachT5 TTS 模型中,Transformer 输出的是一个 768 维的向量,一个线性层处理 log-mel 频谱 ,A(也叫发送网),由额外的线性层和卷积网络精炼频谱减化噪声。vocoder做出最终的音频
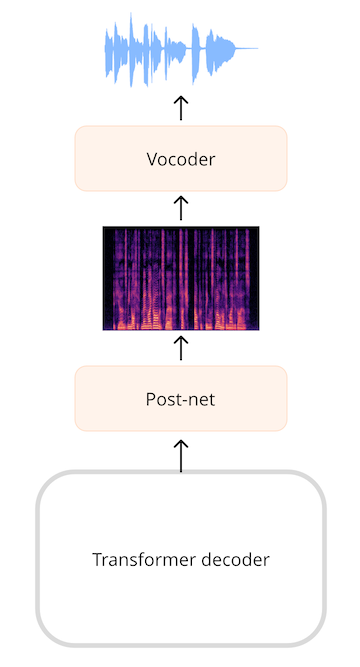
如果使用已有音频采用短时傅里叶变换或者 STFT,则可以执行反向操作,即ISTFT,以再次获得原始波形。之所以起作用,是因为STFT创建的频谱图既包含振幅又包含相位信息,并且都需要重建波形。但是,将其输出作为频谱图生成的音频模型通常仅预测幅度信息,而不是阶段。要将如此频谱图变成波形,我们必须以某种方式估计相信息。这就是声码器所做的。
音频输出
也可以直接输出音频,不过 Hugging face Transformers 目前没现成的模型
CTC 架构
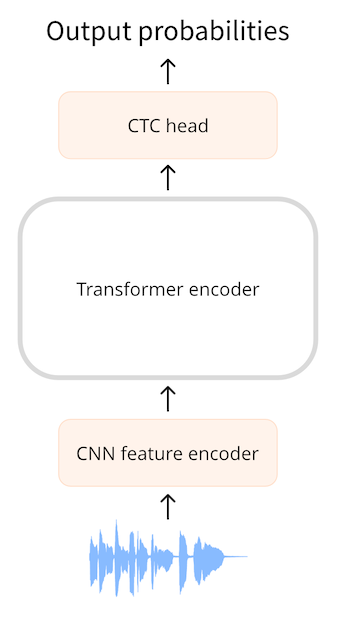
连接时序分类是只用编码器模型用来自动语音识别,此类模型有 Wav2Vec2,HuBERT 和 M-CTC-T。
通过 CTC 模型,我们应用一个额外的线性mapping 匹配隐层去获得分类标签预测。分类标签是字母表,这样我们能通过小分类头预测任意目标语言的文本,词汇只要26个字母+特殊字符就能凑成
the alignment is so-called monotonic
所以咋对齐
- 作为私有字符
- 作为语音
- 字符 tokens
假设输入是一个 1s 的音频,,在 Wav2Vec2 中,模型用 CNN 特征编码器下采样音频输入,每20 微秒一个隐层向量。1s的音频前向传播了50层。 接受了50个输出,每一个输出向量768. shape (768,50).每一个预测耗时 25ms,比语音短,所以预测私人语音或字符要比预测整个单词合理。 CTC 在小单词最佳,所以我们预测字符。

为了预测,我们使用一个线性层(CTC头)来匹配 768维编码器输出。模型预测出一个(50,32)的tensor算子,包含 logits. 其中32是词汇中的token数,我们每预测序列中的一个,会以50个字符结束。
CTC 可以过滤重复项
#### CTC 算法
算法关键是用特殊 token ,这里叫 blank token。
举例
B_R_II_O_N_||_S_AWW_|||||_S_OMEE_TH_ING_||_C_L_O_S_E||TO|_P_A_N_I_C_||_ON||HHI_S||_OP_P_O_N_EN_T_'SS||_F_AA_C_E||_W_H_EN||THE||M_A_NN_||||_F_I_N_AL_LL_Y||||_RREE_C_O_GG_NN_II_Z_ED|||HHISS|||_ER_RRR_ORR||||
| token 是单词分离器字符。在示例中,我们使用|而不是 space 使单词断裂所在的位置更容易,但它具有相同的目的
如果我们只是简单地删除重复的字符,这将成为EROR。这显然不是正确的拼写。但是,使用CTC blank token ,我们可以删除每个组中的重复项,因此:
_ER_R_OR
然后再删掉 blank token,就得到了正确的拼写。
应用这些logic在整个文本
#### Seq2Seq 架构
自动语言识别

seq2seq 很常见用频谱输入,但也可以直接音频输入
交叉注意力
这玩意很像自注意力机制,但是附加在编码器输出,所以编码器就不再被需要了
解码器预测序列的下一个 token 是自回归的方式,也就是不碰到终止 token 会一直预测下去
解码器与编码器最大的不同
- 解码器有交叉注意力机制允许看输入序列的编码器表达
- 解码器的注意力机制是因果相关的,不被允许看未来的
这种设计下,解码器扮演语言模型的角色,处理从编码器加载的隐层表示并生成对应的文本脚本。 这比 CTC 更6. 可以输出比 CTC 短得多的脚本。
Seq2Seq ASR 的损失函数是交叉熵 loss,模型的最后一层通常结合 beam search。语音识别的矩阵通常是 WER(word error rate),这可以衡量需要多少替代,插入和删除才能将预测的文本转换为目标文本,越少越好。
文本转语音
在 ASR 模型,解码器从特殊 开始 token 开始
在 TTS 模型,解码器可以从某一段频谱长度开始

但咋停止呢,SpeechT5 选择预测第二序列,如果概率阈值超过0.5,则停止预测。之后再用 post-net 精修频谱
在 TTS 模型, loss 是 L1 或 MSE.在推理时间将频谱转化为声音,用独立的 vocoder。
因为多次匹配问题,L1 或 MSE 不咋有用。这就是为什么通常使用称为MOS或平均意见分数的度量的人类听众评估TTS模型的原因。
声音分类架构
用频谱预测分类
频谱是2维tensor,shape是(频率,序列长度),可以把频谱图当成图片丢进 ResNet 里,或者用ViT。
任何 tranformer 都可以作为分类器 这些分类器的区别就在于模型的分类曾大小和损失函数的选择