
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
Sparks of Artificial General Intelligence:Early experiments with GPT-4 论文笔记
AGI 的星星之火,GPT4 早期实验
GPT4 是第一个拥有高级智能的 LLM,他比以前任何 AI 模型都更智能,可以解决新颖和复杂的问题,包括数学、编程、视觉、医疗、法律、心理学和更多学科方向的问题,并且不需要特定的 prompt。并且其效果极其接近人类水平。这篇文章着重在发现 GPT4 的限制上,并探讨在科技跃进的下的新的研究方向。
AI 领域近几年最卓越的突破便是 LLM(依靠 Transformer 架构用大量互联网数据进行自监督训练来预测下一个东西的模型)。
本文主要报告了早期非多模态的GPT4版本展现出来的智能,及作为纯语言模型的智能。
下面主要对比了 GPT4 与 ChatGPT 模型结果
| GPT4 | ChatGPT |
|---|---|
 |
 |
下面是 GPT4 对于图表与数学题的求解展示

下面谈谈 GPT4 目前存在的限制
- 瞎编(幻想,存在偏置的数学错误)
已经克服的问题
- 非语言问题
- 常识问题
并且 GPT4 在许多任务上已经超过了人类水平,并且理智到不像人类做出的决策。
GPT4 的智能涌现标志着一个新的领域的开始。
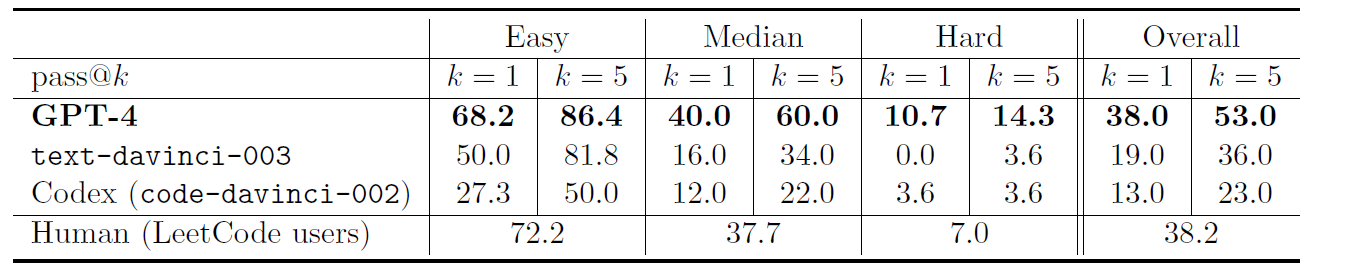
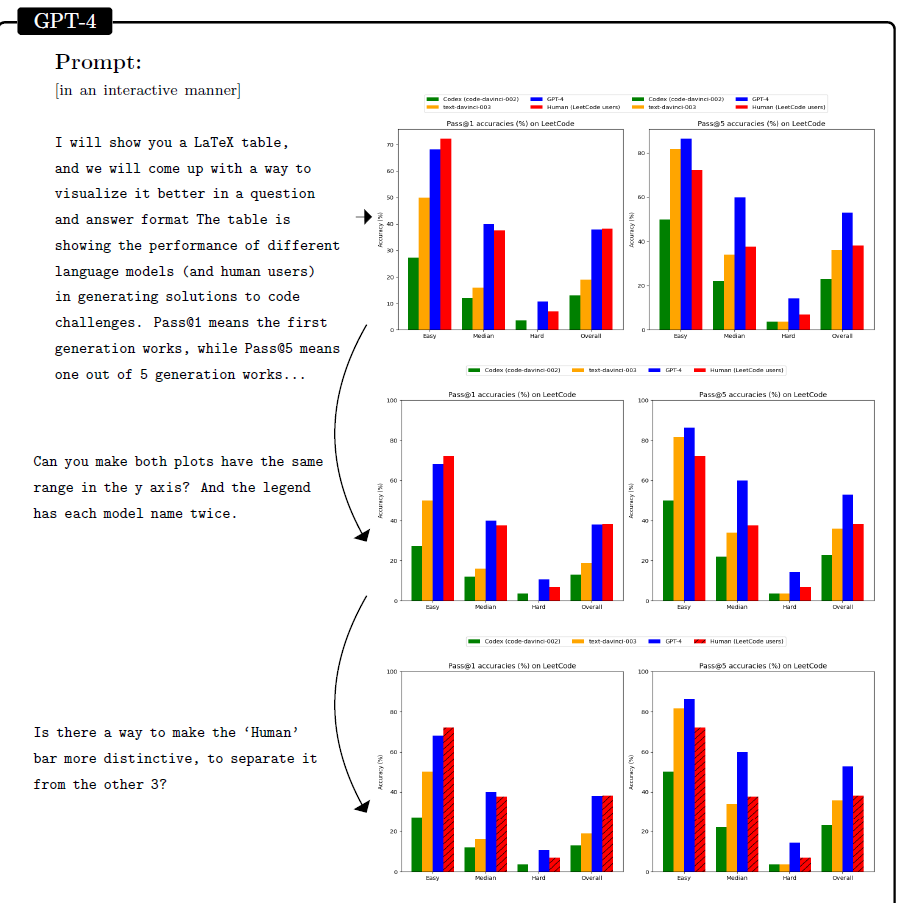
传统的 benchmark 不适合测试GPT4(文中提了两点针对评估矩阵的问题),所以我们采用比较主观的方式去测试他的创造力与对内容的理解程度(用人类的创造力和好奇去生成一个新颖且困难的问题)。
这里列一下我们的发现
- GPT4 可以理解复杂问题
- 编程和数学问题可以被理解和思考
- GPT4 可以使用工具构建真实世界的应用程序
- 常识增强,可以自己比较自己
- 整体结果缺乏规划(自回归限制)
多模态与跨学科
GPT4 可以从不同学科领域提取知识并进行组合生成符合理解的复杂新想法
为了展示综合能力,我们选择了训练数据稀少的文学和数学,或者代码和艺术组合。


可以看出ChatGPT 处理这些任务通常是不完善和缺乏创意的。
后面我们测试了 GPT4 生成的不同类型比如向量,图,3D 感知,音乐等的。
模型似乎具有执行视觉任务的真正能力,而不是只需从训练数据中的类似示例中复制代码。比如下面的例子

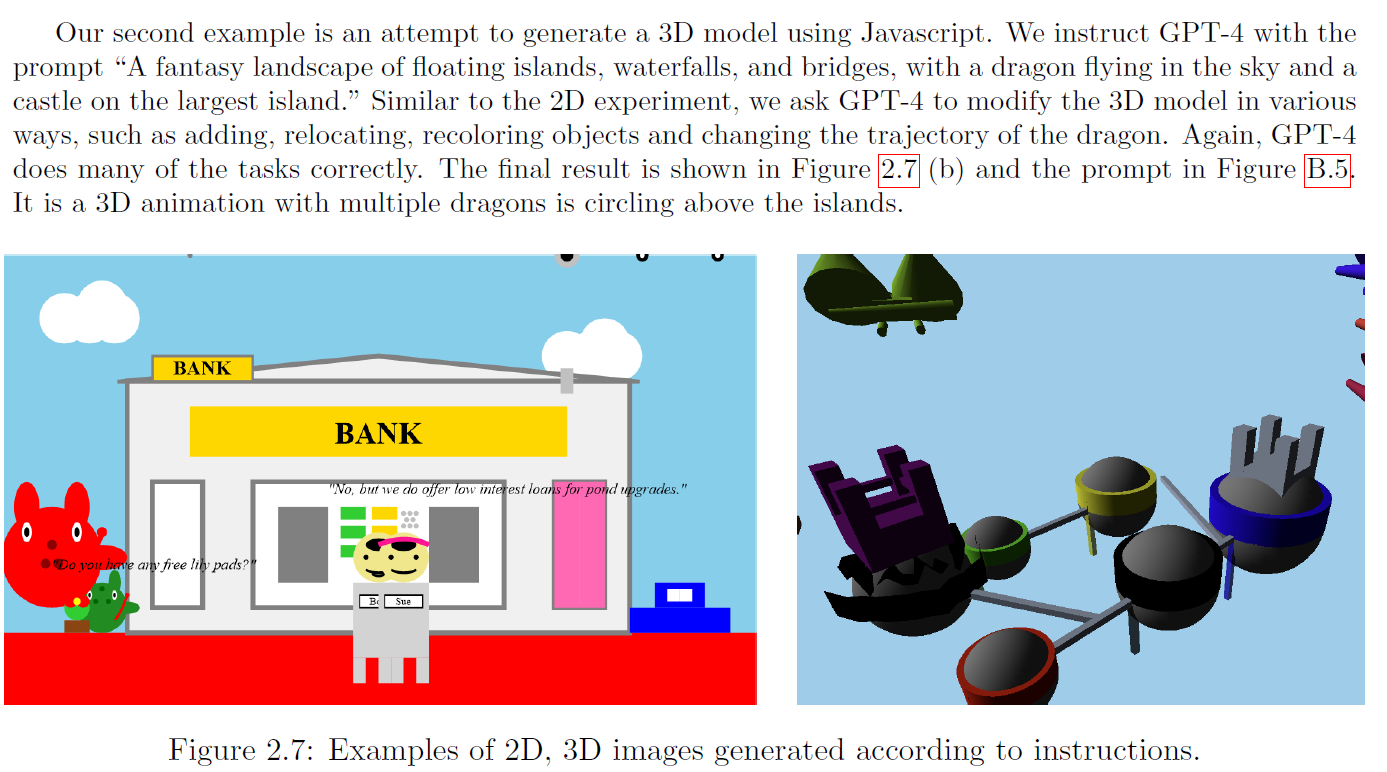
下面是通过指令展示的 3D(JS代码)生成
草图生成
虽然 GPT4 生成的草图非常拉跨,但是我们想到了结合现有的高清生成模型的辅助方向,如图,GPT4+SD.

音乐
音乐很拉跨只能简单顺序曲调或加几个音的变化,他对音乐一窍不通。
编程
GPT4 极大的提升了编程的效率,对于开发这和非开发者都是。但是会出现一些错误,
- 在长代码生成部分会出现无效或错误部分
- 有时候会理解错指令
- 或产出代码不符合功能或风格
但是这些可以通过交互改进提升 当然这些数据都是 GPT4 的早期版本

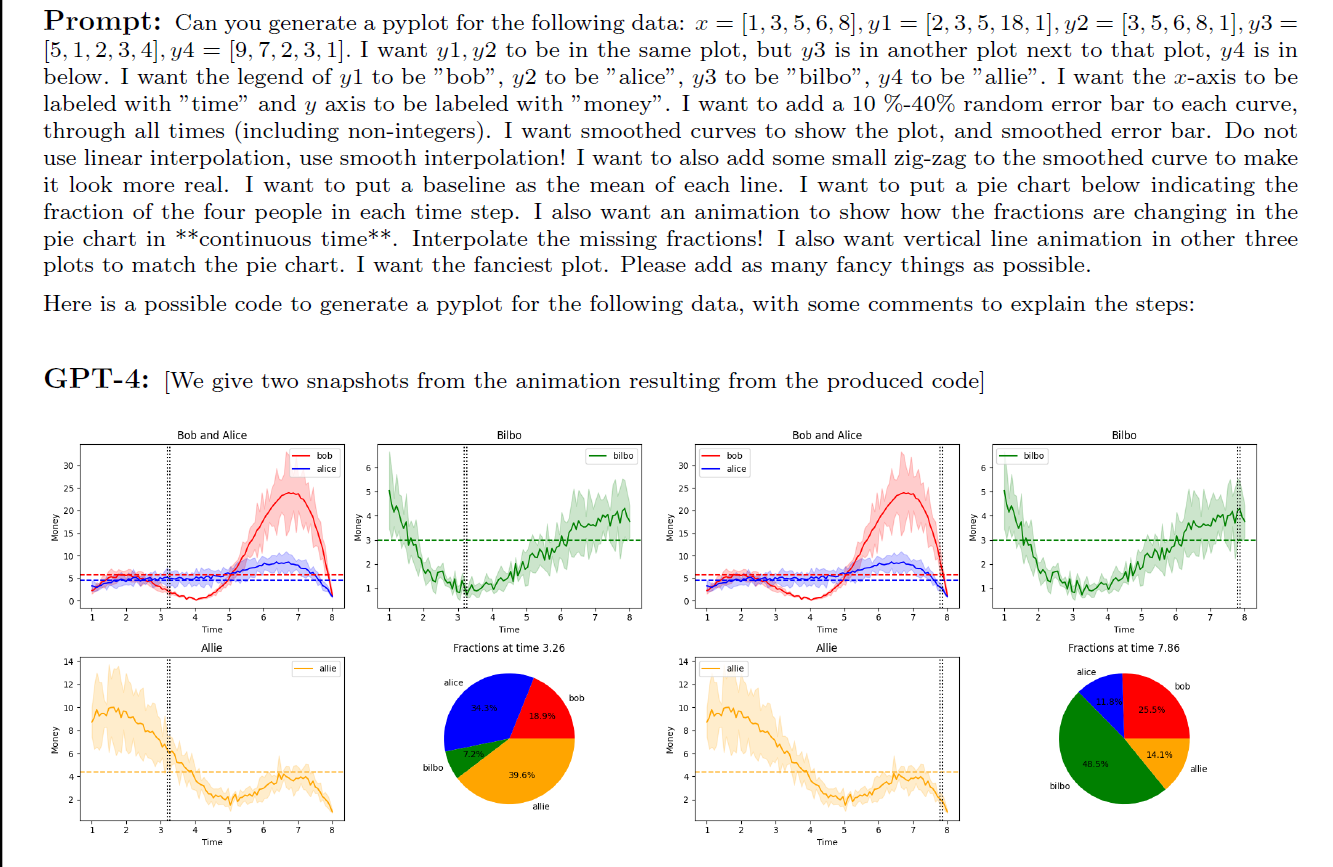
为了测试实际编程能力我们设计了端到端的实验用到不同的技术来验证。
- 数据可视化任务
- 前端游戏开发任务

- 深度学习任务

- 与 LATEX 交互任务

理解现有代码
关于推理执行无论是语言代码或是伪代码都做得很好,理解的也比较到位
数学能力
GPT-4 的准确性与其他模型相比略有提高,但手动检查 GPT-4 的准确性 MATH 上的答案揭示了 GPT-4 的错误主要是由于算术和计算错误。所以计算可以考虑引入计算插件。 这里摆个例子

与世界交互
GPT4 可以利用现有工具进行交互,但是ChatGPT会以无权限,违法,无法接入为由拒绝。 下面是 GPT4 交互示例
- 黑客和渗透攻击
- 通过命令行指令管理动物园。
- 管理日历和邮箱
- 浏览网页信息
- 使用不寻常的工具,用户交互有错误后会修复,但是 ChatGPT 不会。
交互限制
- 还需要 Prompt 接入额外插件
- 不是总能合理执行工具
具身互动
现实并不总是与API打交道,现实中的身体互动在 GPT4 中没有体现,考虑怎么把环境输入进去喂给智能体。文中给了几个例子
与人交互
实验证明他有非常高的心智水平
判断能力
实验证明还行具体看文章数据
自回归模型限制
- 在数学或解释性问题上缺乏规划
- 文本生成时缺乏规划
社会问题
- 错误答案的影响
- 错误信息的操作
- 偏置认知(比如对某群体的性别比例问题)
- 接入 AI 与 不接入直接会产生鸿沟,社会结构改变。
迈向 AGI
- 置信校准问题
- 长期记忆问题
- 持续学习问题
- 私人刻制化问题
- 概念技术跃迁问题
- 透明,可解释,一致性问题
- 认知错误与非理性问题
- 输入敏感问题