
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
CodeGeeX模型详解
CodeGeeX作为一个多语言代码生成模型 时间是2022年7月22日训练完成,13B的训练参数,超过850B的token
特点
- 多语言生成
- 语言翻译
- 编程助手
- 开源与多平台
HumanEval-X作为多语言评估的benchmark(本项目产出的benchmark)
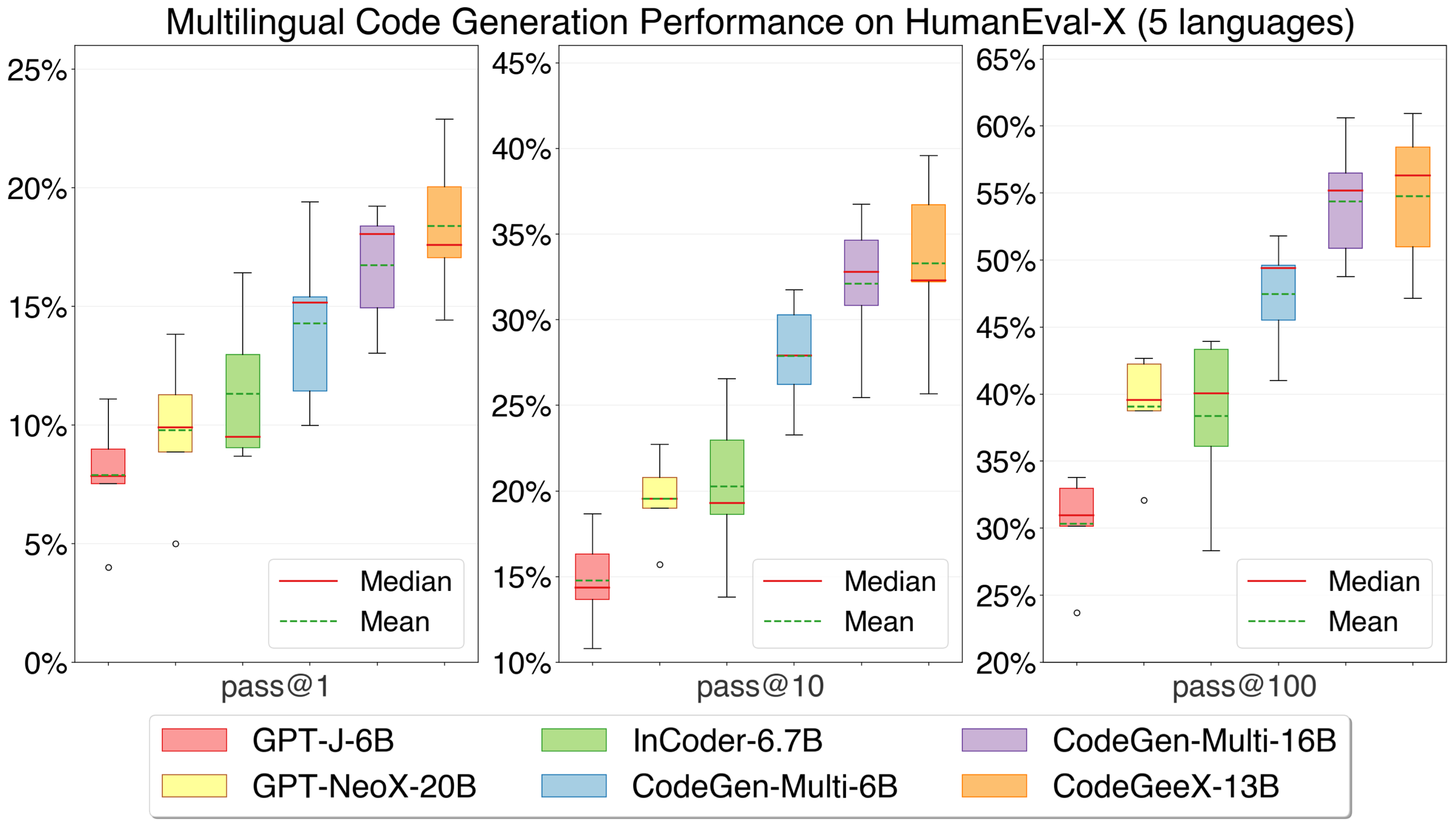
从箱线图可以看出CodeGeeX整体表现还是比较高的。
使用
依赖Megatron-LM
项目权重大概26G
GPU推理
- 修改
configs/codegeex_13b.sh中的权重路径 - 写prompt在
tests/test_prompt.txt
运行下面脚本
# On a single GPU (with more than 27GB RAM)
bash ./scripts/test_inference.sh <GPU_ID> ./tests/test_prompt.txt
# With quantization (with more than 15GB RAM)
bash ./scripts/test_inference_quantized.sh <GPU_ID> ./tests/test_prompt.txt
# On multiple GPUs (with more than 6GB RAM, need to first convert ckpt to MP_SIZE partitions)
bash ./scripts/convert_ckpt_parallel.sh <LOAD_CKPT_PATH> <SAVE_CKPT_PATH> <MP_SIZE>
bash ./scripts/test_inference_parallel.sh <MP_SIZE> ./tests/test_prompt.txt
CodeGeeX :结构,代码语料库,执行
结构
- 40层tranformer
- 隐藏5120 Self-attention blocks和20480FFN层
- 支持最大序列长度2048
代码语料库
主要包含两部分
- 第一部分
- The Pile
- CodeParrot
- 第二部分
- github爬取
训练
- github爬取
- 采用8-way的模型并行
- 192-way的数据并行
- ZeRO-2优化
- 最小bs16,全局bs3072
- 其他技巧
- element-wise operator fusion
- fast gelu activation
- matrix multiplication dimension optimization
- 训练时间从2022-4-18到2022-6-22
- 850B的tokens被训练超过5+epcho
benchmark
HumanEval-X
HumanEval-X 包含 820 个高质量的人工数据样本(每个样本都有测试用例),使用 Python、C++、Java、JavaScript 和 Go 编写,可用于各种任务