
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
Bert实战
本文大部分参照于冬的博客 仅供自己参考
文本分类
引言:我们将展示如何使用 🤗 Transformers代码库中的模型来解决文本分类任务,任务来源于GLUE Benchmark.
- 任务介绍 本质就是分类问题,比如对一句话的情感极性分类(正向1或负向-1或中性0):
步骤
- 数据加载
- 数据预处理
- 微调预训练模型:使用transformer中的Trainer接口对预训练模型进行微调
- 超参数搜索
前期准备
安装以下两个库
pip install datasets transformers
数据加载
数据集介绍
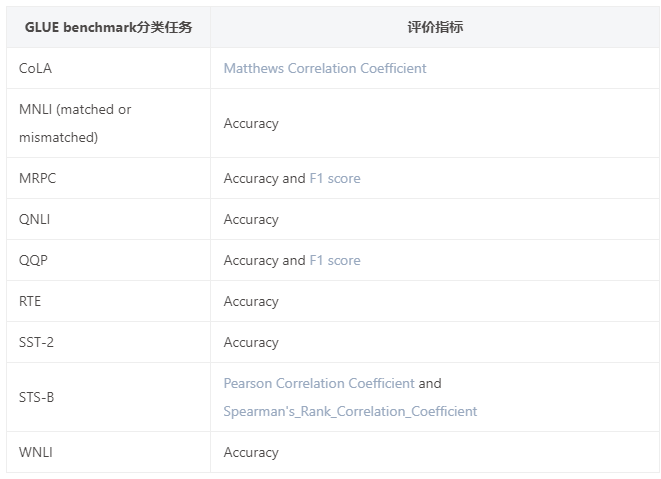
- GLUE
-
GLUE_TASKS = ["cola", "mnli", "mnli-mm", "mrpc", "qnli", "qqp", "rte", "sst2", "stsb", "wnli"]
| 分类任务 | 任务目标 |
|---|---|
| CoLA (Corpus of Linguistic Acceptability) | 鉴别一个句子是否语法正确. |
| MNLI (Multi-Genre Natural Language Inference) | 给定一个假设,判断另一个句子与该假设的关系:entails, contradicts 或者 unrelated。 |
| MRPC (Microsoft Research Paraphrase Corpus) | 判断两个句子是否互为paraphrases改写. |
| QNLI (Question-answering Natural Language Inference) | 判断第2句是否包含第1句问题的答案。 |
| QQP (Quora Question Pairs2) | 判断两个问句是否语义相同。 |
| RTE (Recognizing Textual Entailment) | 判断一个句子是否与假设成entail关系。 |
| SST-2 (Stanford Sentiment Treebank) | 判断一个句子的情感正负向. |
| STS-B (Semantic Textual Similarity Benchmark) | 判断两个句子的相似性(分数为1-5分)。 |
| WNLI (Winograd Natural Language Inference) | 判断一个有匿名代词的句子和一个有该代词被替换的句子是否包含。Determine if a sentence with an anonymous pronoun and a sentence with this pronoun replaced are entailed or not. |
数据加载
- 加载官方数据
除了
mbli-mm外,其他任务都可以直接通过任务名字进行加载。数据加载之后会自动缓存
from datasets import load_dataset
actual_task = "mnli" if task == "mnli-mm" else task
dataset = load_dataset("glue", actual_task)
metric = load_metric('glue', actual_task)
这个datasets对象本身是一种DatasetDict数据结构. 对于训练集、验证集和测试集,只需要使用对应的key(train,validation,test)即可得到相应的数据。 给定一个数据切分的key(train、validation或者test)和下标即可查看数据:dataset[“train”][0]
下面的函数将从数据集里随机选择几个例子进行展示:
import datasets
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, datasets.ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
show_random_elements(dataset["train"])
- 加载自己的数据
- csv格式
data_files为本地文件名或网络数据链接,如果没有用字典指定训练集、验证集、测试集,默认都为训练集。
from datasets import load_dataset dataset = load_dataset('csv', data_files='my_file.csv') dataset = load_dataset('csv', data_files=['my_file_1.csv', 'my_file_2.csv', 'my_file_3.csv']) dataset = load_dataset('csv', data_files={'train': ['my_train_file_1.csv', 'my_train_file_2.csv'], base_url = 'https://huggingface.co/datasets/lhoestq/demo1/resolve/main/data/' dataset = load_dataset('csv', data_files={'train': base_url + 'train.csv', 'test': base_url + 'test.csv'})-
json格式
情况1:json数据不包括嵌套的json,比如:
{"a": 1, "b": 2.0, "c": "foo", "d": false} {"a": 4, "b": -5.5, "c": null, "d": true}次数可以直接加载数据
from datasets import load_dataset dataset = load_dataset('json', data_files={'train': ['my_text_1.json', 'my_text_2.json'], 'test': 'my_test_file.json'}) dataset = load_dataset('text', data_files={'train': 'https://huggingface.co/datasets/lhoestq/test/resolve/main/some_text.json'})情况二:json数据包括嵌套的json,比如:
{"version": "0.1.0", "data": [{"a": 1, "b": 2.0, "c": "foo", "d": false}, {"a": 4, "b": -5.5, "c": null, "d": true}] }此时需要使用 field 参数指定哪个字段包含数据集:
from datasets import load_dataset dataset = load_dataset('json', data_files='my_file.json', field='data') -
txt格式
from datasets import load_dataset dataset = load_dataset('text', data_files={'train': ['my_text_1.txt', 'my_text_2.txt'], 'test': 'my_test_file.txt'}) dataset = load_dataset('text', data_files={'train': 'https://huggingface.co/datasets/lhoestq/test/resolve/main/some_text.txt'}) -
dict格式
my_dict = {'id': [0, 1, 2], 'name': ['mary', 'bob', 'eve'], 'age': [24, 53, 19]} from datasets import Dataset dataset = Dataset.from_dict(my_dict) -
pandas.DataFrame格式
from datasets import Dataset import pandas as pd df = pd.DataFrame({"a": [1, 2, 3]}) dataset = Dataset.from_pandas(df)
数据预处理
在将数据喂入模型之前,我们需要对数据进行预处理。之前我们已经知道了数据预处理的基本流程:
- 分词
- 转化成对应任务输入模型的格式
Tokenizer用于上面两步数据预处理工作:Tokenizer首先对输入进行tokenize,然后将tokens转化为预模型中需要对应的token ID,再转化为模型需要的输入格式。
初始化Tokenizer
使用AutoTokenizer.from_pretrained方法根据模型文件实例化tokenizer,这样可以确保:
- 得到一个与预训练模型一一对应的tokenizer。
-
使用指定的模型checkpoint对应的tokenizer时,同时下载了模型需要的词表库vocabulary,准确来说是tokens vocabulary。
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
注意:use_fast=True要求tokenizer必须是transformers.PreTrainedTokenizerFast类型,以便在预处理的时候需要用到fast tokenizer的一些特殊特性(比如多线程快速tokenizer)。如果对应的模型没有fast tokenizer,去掉这个选项即可。 几乎所有模型对应的tokenizer都有对应的fast tokenizer,可以在模型tokenizer对应表里查看所有预训练模型对应的tokenizer所拥有的特点。
Tokenizer分词示例
预训练的Tokenizer通常包含了分单句和分一对句子的函数。如:
#分单句(一个batch)
batch_sentences = ["Hello I'm a single sentence",
"And another sentence",
"And the very very last one"]
encoded_inputs = tokenizer(batch_sentences)
print(encoded_inputs)
#{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
# [101, 1262, 1330, 5650, 102],
# [101, 1262, 1103, 1304, 1304, 1314, 1141, 102]],
# 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 0, 0]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1, 1, 1, 1]]}
#分一对句子
encoded_input = tokenizer("How old are you?", "I'm 6 years old")
print(encoded_input)
#{'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, #1201, 1385, 102],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
我们之前也提到如果是自己预训练的tokenizers可以通过以下方式为tokenizers增加处理一对句子的方法:
from tokenizers.processors import TemplateProcessing
tokenizer.post_processor = TemplateProcessing(
single="[CLS] $A [SEP]",
pair="[CLS] $A [SEP] $B:1 [SEP]:1",
special_tokens=[
("[CLS]", tokenizer.token_to_id("[CLS]")),
("[SEP]", tokenizer.token_to_id("[SEP]")),
],
)
#设置句子最大长度
tokenizer.enable_truncation(max_length=512)
#使用tokenizer.save()保存模型
tokenizer.save("data/tokenizer-wiki.json")
转化成对应任务输入模型的格式
tokenizer有不同的返回取决于选择的预训练模型,tokenizer和预训练模型是一一对应的,更多信息可以在这里进行学习。 不同数据和对应的数据格式,为了预处理我们的数据,定义下面这个dict,以便分别用tokenizer处理输入是单句或句子对的情况。
task_to_keys = {
"cola": ("sentence", None),
"mnli": ("premise", "hypothesis"),
"mnli-mm": ("premise", "hypothesis"),
"mrpc": ("sentence1", "sentence2"),
"qnli": ("question", "sentence"),
"qqp": ("question1", "question2"),
"rte": ("sentence1", "sentence2"),
"sst2": ("sentence", None),
"stsb": ("sentence1", "sentence2"),
"wnli": ("sentence1", "sentence2"),
}
将预处理的代码放到一个函数中:
def preprocess_function(examples):
if sentence2_key is None:
return tokenizer(examples[sentence1_key], truncation=True)
return tokenizer(examples[sentence1_key], examples[sentence2_key], truncation=True)
前面我们已经展示了tokenizer处理一个小batch的案例。dataset类直接用索引就可以取对应下标的句子1和句子2,因此上面的预处理函数既可以处理单个样本,也可以对多个样本进行处理。如果输入是多个样本,那么返回的是一个list:
preprocess_function(dataset['train'][:5])
#{'input_ids': [[101, 2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012, 102], [101, 2028, 2062, 18404, 2236, 3989, 1998, 1045, 1005, 1049, 3228, 2039, 1012, 102], [101, 2028, 2062, 18404, 2236, 3989, 2030, 1045, 1005, 1049, 3228, 2039, 1012, 102], [101, 1996, 2062, 2057, 2817, 16025, 1010, 1996, 13675, 16103, 2121, 2027, 2131, 1012, 102], [101, 2154, 2011, 2154, 1996, 8866, 2024, 2893, 14163, 8024, 3771, 1012, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
接下来使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将预处理函数prepare_train_features应用到(map)所有样本上。
encoded_dataset = dataset.map(preprocess_function, batched=True)
返回的结果会自动被缓存,避免下次处理的时候重新计算(但是也要注意,如果输入有改动,可能会被缓存影响!)。 datasets库函数会对输入的参数进行检测,判断是否有变化,如果没有变化就使用缓存数据,如果有变化就重新处理。但如果输入参数不变,想改变输入的时候,最好清理调这个缓存(使用load_from_cache_file=False参数)。另外,上面使用到的batched=True这个参数是tokenizer的特点,这会使用多线程同时并行对输入进行处理。
微调预训练模型
数据已经准备好了,我们需要下载并加载预训练模型,然后微调预训练模型。
加载预训练模型
既然是做seq2seq任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForSequenceClassification 这个类。
和tokenizer相似,from_pretrained方法同样可以帮助下载并加载模型,同时也会对模型进行缓存,也可以填入一个包括模型相关文件的文件夹(比如自己预训练的模型),这样会从本地直接加载。理论上可以使用各种各样的transformer模型(模型面板),解决任何文本分类分类任务。
需要注意的是:STS-B是一个回归问题,MNLI是一个3分类问题:
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
task = "cola"
model_checkpoint = "distilbert-base-uncased" #所选择的预训练模型
num_labels = 3 if task.startswith("mnli") else 1 if task=="stsb" else 2
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
由于我们的任务是文本分类任务,而我们加载的是预训练语言模型,所以会提示我们加载模型的时候扔掉了一些不匹配的神经网络参数(比如:预训练语言模型的神经网络head被扔掉了,同时随机初始化了文本分类的神经网络head)
设定训练参数
为了能够得到一个Trainer训练工具,我们还需要训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
batch_size = 16
metric_name = "pearson" if task == "stsb" else "matthews_correlation" if task == "cola" else "accuracy"
args = TrainingArguments(
"test-glue",
evaluation_strategy = "epoch", #每个epcoh会做一次验证评估;
save_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=5,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model=metric_name, #根据哪个评价指标选最优模型
)
定义评估方法
还有一件重要的事,我们需要选择一个合适的评价指标引导模型进行微调。 我们使用🤗 Datasets库来加载评价指标计算库load_metric。metic是datasets.Metric的一个实例:
from datasets import load_metric
import numpy as np
fake_preds = np.random.randint(0, 2, size=(64,))
fake_labels = np.random.randint(0, 2, size=(64,))
metric.compute(predictions=fake_preds, references=fake_labels)
#{'matthews_correlation': 0.1513518081969605}
为Trainer定义各个任务的评估方法compute_metrics:
from datasets import load_metric
def compute_metrics(eval_pred):
predictions, labels = eval_pred
if task != "stsb":
predictions = np.argmax(predictions, axis=1)
else:
predictions = predictions[:, 0]
return metric.compute(predictions=predictions, references=labels)
开始训练
将数据/模型/参数传入Trainer即可:
validation_key = "validation_mismatched" if task == "mnli-mm" else "validation_matched" if task == "mnli" else "validation"
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset[validation_key],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
开始训练:
trainer.train()
模型评估
trainer.evaluate()
超参数搜索
Trainer还支持超参搜索,使用optuna or Ray Tune代码库。
需要安装以下两个依赖:
pip install optuna
pip install ray[tune]
超参搜索时,Trainer将会返回多个训练好的模型,所以需要传入一个定义好的模型从而让Trainer可以不断重新初始化该传入的模型:
def model_init():
return AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
和之前调用 Trainer类似:
trainer = Trainer(
model_init=model_init,
args=args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset[validation_key],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
调用方法hyperparameter_search进行超参数搜索。
注意,这个过程可能很久,可以先用部分数据集进行超参搜索,再进行全量训练。 比如使用1/10的数据进行搜索(利用n_trials设置):
best_run = trainer.hyperparameter_search(n_trials=10, direction="maximize")
hyperparameter_search会返回效果最好的模型相关的参数best_run:
将Trainner设置为搜索到的最好参数best_run,再对全部数据进行训练:
for n, v in best_run.hyperparameters.items():
setattr(trainer.args, n, v)
trainer.train()
上传模型到huggingface
序列标注
任务介绍
序列标注,通常也可以看作是token级别的分类问题:对每一个token进行分类。
token级别的分类任务通常指的是为文本中的每一个token预测一个标签结果。比如命名实体识别任务:
输入:我爱北京天安门
输出:O O B-LOC I-LOC B-POI B-POI I-POI
常见的token级别分类任务:
- NER (Named-entity recognition 名词-实体识别) 分辨出文本中的名词和实体 (person人名, organization组织机构名, location地点名…).
- POS (Part-of-speech tagging词性标注) 根据语法对token进行词性标注 (noun名词, verb动词, adjective形容词…)
- Chunk (Chunking短语组块) 将同一个短语的tokens组块放在一起。
主要分为以下几个部分:
- 数据加载
- 数据预处理
- 微调预训练模型:使用transformer中的Trainer接口对预训练模型进行微调。
前期准备
pip install datasets transformers seqeval
#transformers==4.9.2
#datasets==1.11.0
#seqeval==1.2.2
数据加载
数据集介绍
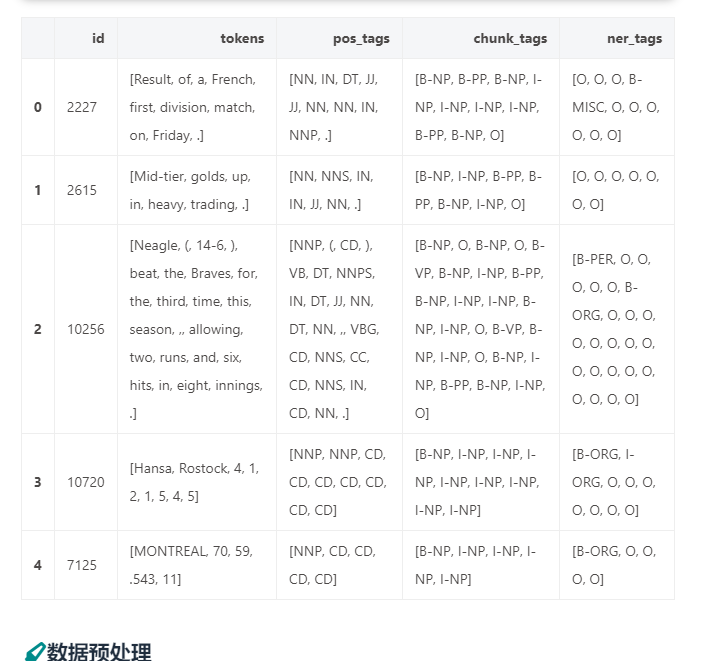
我们使用的是CONLL 2003 dataset数据集。
无论是在训练集、验证机还是测试集中,datasets都包含了一个名为tokens的列(一般来说是将文本切分成了多个token),还包含完成三个不同任务的label列(ner_tag,pos_tag和chunk_tag),对应了不同任务这tokens的标注
加载数据
该数据的加载方式在transformers库中进行了封装,我们可以通过以下语句进行数据加载:
from datasets import load_dataset
datasets = load_dataset("conll2003")
给定一个数据切分的key(train、validation或者test)和下标即可查看数据。
datasets["train"][0]
#{'chunk_tags': [11, 21, 11, 12, 21, 22, 11, 12, 0],
# 'id': '0',
# 'ner_tags': [3, 0, 7, 0, 0, 0, 7, 0, 0],
# 'pos_tags': [22, 42, 16, 21, 35, 37, 16, 21, 7],
# 'tokens': ['EU',
# 'rejects',
# 'German',
# 'call',
# 'to',
# 'boycott',
# 'British',
# 'lamb',
# '.']}
所有的数据标签都已经被编码成了整数,可以直接被预训练transformer模型使用。这些整数的编码所对应的实际类别储存在features中。
datasets["train"].features[f"ner_tags"]
#Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
以NER任务为例,0对应的标签类别是”O“, 1对应的是”B-PER“等等。
”O“表示没有特别实体(no special entity/other)。本例包含4种有价值实体类别分别是(PER、ORG、LOC,MISC),每一种实体类别又分别有B-(实体开始的token)前缀和I-(实体中间的token)前缀。
- ‘PER’ for person
- ‘ORG’ for organization
- ‘LOC’ for location
- ‘MISC’ for miscellaneous
label_list = datasets["train"].features[f"{task}_tags"].feature.names
label_list
#['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
下面的函数将从数据集里随机选择几个例子进行展示:
from datasets import ClassLabel, Sequence
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=4):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
elif isinstance(typ, Sequence) and isinstance(typ.feature, ClassLabel):
df[column] = df[column].transform(lambda x: [typ.feature.names[i] for i in x])
display(HTML(df.to_html()))
show_random_elements(datasets["train"])
数据预处理
初始化Tokenizer
from transformers import AutoTokenizer
model_checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
转化成对应任务输入模型的格式
transformer预训练模型在预训练的时候通常使用的是subword,如果我们的文本输入已经被切分成了word,这些word还会被tokenizer继续切分为subwords,同时,由于预训练模型输入格式的要求,往往还需要加上一些特殊符号比如: [CLS] 和 [SEP]。比如:
example = datasets["train"][4]
tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
print(len(example[f"{task}_tags"]), len(tokenized_input["input_ids"]))
#(31, 39)
print(example["tokens"])
print(tokens)
#['Germany', "'s", 'representative', 'to', 'the', 'European', 'Union', "'s", 'veterinary', 'committee', 'Werner', 'Zwingmann', 'said', 'on', 'Wednesday', 'consumers', 'should', 'buy', 'sheepmeat', 'from', 'countries', 'other', 'than', 'Britain', 'until', 'the', 'scientific', 'advice', 'was', 'clearer', '.']
#['[CLS]', 'germany', "'", 's', 'representative', 'to', 'the', 'european', 'union', "'", 's', 'veterinary', 'committee', 'werner', 'z', '##wing', '##mann', 'said', 'on', 'wednesday', 'consumers', 'should', 'buy', 'sheep', '##me', '##at', 'from', 'countries', 'other', 'than', 'britain', 'until', 'the', 'scientific', 'advice', 'was', 'clearer', '.', '[SEP]']
可以看到单词”Zwingmann” 继续被切分成了3个subtokens: ‘z’, ‘##wing’, ‘##mann’。
由于标注数据通常是在word级别进行标注的,而word被切分成了subwords,那么意味需要对标注数据进行subtokens的对齐。
tokenizer中word_ids方法可以帮助我们解决这个问题。
print(tokenized_input.word_ids())
#[None, 0, 1, 1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10, 11, 11, 11, 12, 13, 14, 15, 16, 17, 18, 18, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, None]
可以看到,word_ids将每一个subtokens位置都对应了一个word的下标。比如第1个位置对应第0个word,然后第2、3个位置对应第1个word。特殊字符对应了None。
利用这个list,我们就能将subtokens和words还有标注的labels对齐。
word_ids = tokenized_input.word_ids()
aligned_labels = [-100 if i is None else example[f"{task}_tags"][i] for i in word_ids]
print(len(aligned_labels), len(tokenized_input["input_ids"]))
#39 39
通常将特殊字符的label设置为-100,在模型中-100通常会被忽略掉不计算loss。 有两种对齐label的方式,通过label_all_tokens = True切换。
- 多个subtokens对齐一个word,对齐一个label;
- 多个subtokens的第一个subtoken对齐word,对齐一个label,其他subtokens直接赋予-100.
所有内容合起来变成我们的预处理函数。is_split_into_words=True因为输入的数据已经是按空格切分成word的格式了。
label_all_tokens = True
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples[f"{task}_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
label_ids.append(label[word_idx] if label_all_tokens else -100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
以上的预处理函数可以处理一个样本,也可以处理多个样本exapmles。如果是处理多个样本,则返回的是多个样本被预处理之后的结果list。
tokenize_and_align_labels(datasets['train'][:5])
#{'input_ids': [[101, 7327, 19164, 2446, 2655, 2000, 17757, 2329, 12559, 1012, 102], [101, 2848, 13934, 102], [101, 9371, 2727, 1011, 5511, 1011, 2570, 102], [101, 1996, 2647, 3222, 2056, 2006, 9432, 2009, 18335, 2007, 2446, 6040, 2000, 10390, 2000, 18454, 2078, 2329, 12559, 2127, 6529, 5646, 3251, 5506, 11190, 4295, 2064, 2022, 11860, 2000, 8351, 1012, 102], [101, 2762, 1005, 1055, 4387, 2000, 1996, 2647, 2586, 1005, 1055, 15651, 2837, 14121, 1062, 9328, 5804, 2056, 2006, 9317, 10390, 2323, 4965, 8351, 4168, 4017, 2013, 3032, 2060, 2084, 3725, 2127, 1996, 4045, 6040, 2001, 24509, 1012, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'labels': [[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, -100], [-100, 1, 2, -100], [-100, 5, 0, 0, 0, 0, 0, -100], [-100, 0, 3, 4, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -100], [-100, 5, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0, -100]]}
接下来使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将预处理函数prepare_train_features应用到(map)所有样本上。
tokenized_datasets = datasets.map(tokenize_and_align_labels, batched=True)
微调预训练模型
加载预训练模型
做序列标注token classification任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForTokenClassification 这个类。 和tokenizer相似,from_pretrained方法同样可以帮助下载并加载模型,同时也会对模型进行缓存,也可以填入一个包括模型相关文件的文件夹(比如自己预训练的模型),这样会从本地直接加载。
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(model_checkpoint, num_labels=len(label_list))
设定训练参数
task='ner'
batch_size = 16
from transformers import TrainingArguments
args = TrainingArguments(
f"test-{task}",
evaluation_strategy = "epoch",#每个epcoh会做一次验证评估
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
)
数据收集器 data collator
接下来需要告诉Trainer如何从预处理的输入数据中构造batch。我们使用数据收集器data collator,将经预处理的输入分batch再次处理后喂给模型。
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer)
定义评估方法
使用seqeval metric来完成评估
from datasets import load_metric
metric = load_metric("seqeval")
评估的输入是预测和label的list:
labels = [label_list[i] for i in example[f"{task}_tags"]]
metric.compute(predictions=[labels], references=[labels])
#{'LOC': {'f1': 1.0, 'number': 2, 'precision': 1.0, 'recall': 1.0},
# 'ORG': {'f1': 1.0, 'number': 1, 'precision': 1.0, 'recall': 1.0},
# 'PER': {'f1': 1.0, 'number': 1, 'precision': 1.0, 'recall': 1.0},
# 'overall_accuracy': 1.0,
# 'overall_f1': 1.0,
# 'overall_precision': 1.0,
# 'overall_recall': 1.0}
将模型预测送入评估之前,还需要做一些数据后处理:
- 选择预测分类最大概率的下标;
- 将下标转化为label;
- 忽略-100所在位置。
下面的函数将上面的步骤合并了起来:
import numpy as np
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2) #选择预测分类最大概率的下标
# Remove ignored index (special tokens)忽略-100所在位置
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
#计算所有类别总的precision/recall/f1,所以会扔掉单个类别的precision/recall/f1
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
开始训练
from transformers import Trainer
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
模型评估
trainer.evaluate()
predictions, labels, _ = trainer.predict(tokenized_datasets["validation"])
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
print(results)
问答任务-多选问答
任务介绍
虽然叫多选问答,但实际上是指给出一个问题的多个可能的答案(备选项),选出其中一个最合理的,其实类似于我们平常做的单选题。该任务的实质同样是分类任务,在多个备选项中进行二分类,找到答案。
比如输入一句话的上半句,给出几个后半句的备选项,选出哪个选项是这个上半句的后半句
输入:("离离原上草",["天安门一游","一岁一枯荣","春风吹又生"])
输出:1
主要分为以下几个部分:
- 数据加载
- 数据预处理
- 微调预训练模型:使用transformer中的Trainer接口对预训练模型进行微调。
数据加载
数据集介绍
我们使用的数据集是SWAG。SWAG是一个关于常识推理的数据集,每个样本描述一种情况,然后给出四个可能的选项。
加载数据
该数据的加载方式在transformers库中进行了封装,我们可以通过以下语句进行数据加载:
from datasets import load_dataset
datasets = load_dataset("swag", "regular")
#给定一个数据切分的key(train、validation或者test)和下标即可查看数据。
datasets["train"][0]
#{'ending0': 'passes by walking down the street playing their instruments.',
# 'ending1': 'has heard approaching them.',
# 'ending2': "arrives and they're outside dancing and asleep.",
# 'ending3': 'turns the lead singer watches the performance.',
# 'fold-ind': '3416',
# 'gold-source': 'gold',
# 'label': 0,
# 'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
# 'sent2': 'A drum line',
# 'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
# 'video-id': 'anetv_jkn6uvmqwh4'}
下面的函数将从数据集里随机选择几个例子进行展示:
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=3):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
show_random_elements(datasets["train"])
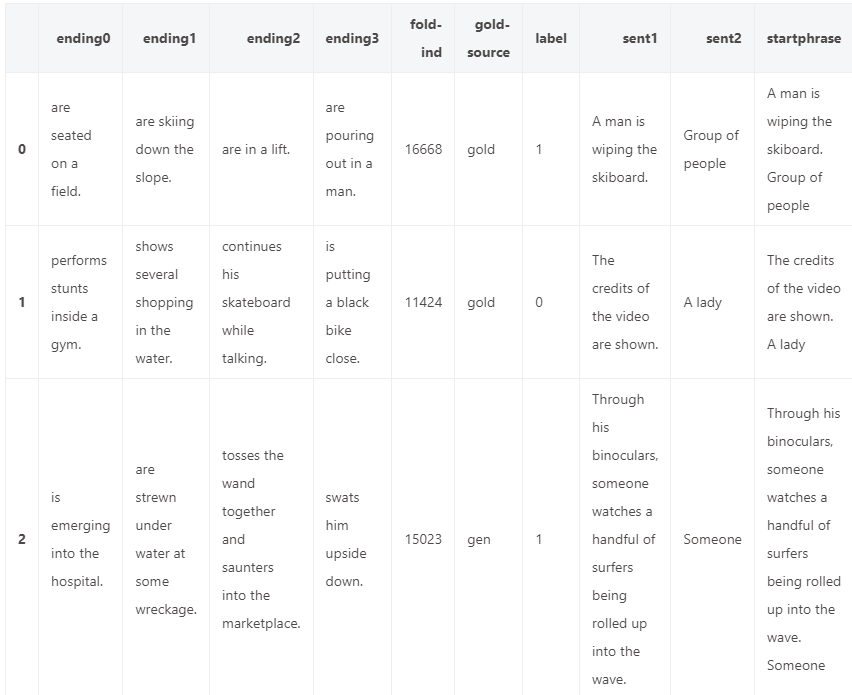
可以看到,数据集中的每个示例都有一个上下文,它是由第一个句子(字段sent1)和第二个句子的简介(字段sent2)组成,并给出四种结尾句子的备选项(字段ending0, ending1, ending2和ending3),然后让模型从中选择正确的一个(由字段label表示)。
数据预处理
from transformers import AutoTokenizer
model_checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
[("Members of the procession walk down the street holding small horn brass instruments.","A drum line passes by walking down the street playing their instruments."),
("Members of the procession walk down the street holding small horn brass instruments.","A drum line has heard approaching them."),
("Members of the procession walk down the street holding small horn brass instruments.","A drum line arrives and they're outside dancing and asleep."),
("Members of the procession walk down the street holding small horn brass instruments.","A drum line turns the lead singer watches the performance.")]
之前已经介绍过Tokenizer的输入可以是一个单句,也可以是两个句子。
那么显然在调用tokenizer之前,我们需要预处理数据集先生成输入Tokenizer的样本。
在preprocess_function函数中:
-
首先将样本中问题和备选项分别放在两个嵌套列表(两个嵌套列表分别存储了每个样本的问题和备选项)中;
比如,e1_sen1表示样本1的问题(相当于输入tokenizer的句子1),e1_sen2_1表示样本1的备选项1(相当于输入tokenizer的句子2)…..
[[e1_sen1,e1_sen1,e1_sen1,e1_sen1],
[e2_sen1,e2_sen1,e2_sen1,e2_sen1],
[e3_sen1,e3_sen1,e3_sen1,e3_sen1]]
[[e1_sen2_1,e1_sen2_2,e1_sen2_3,e1_sen2_4],
[e2_sen2_1,e2_sen2_2,e2_sen2_3,e2_sen2_4],
[e3_sen2_1,e3_sen2_2,e3_sen2_3,e3_sen2_4]]
- 然后将问题列表和备选项列表拉平Flatten(两个嵌套列表各自去掉嵌套),以便tokenizer进行批处理,以问题列表为例:
after flatten->
[e1_sen1,e1_sen1,e1_sen1,e1_sen1,
e2_sen1,e2_sen1,e2_sen1,e2_sen1,
e3_sen1,e3_sen1,e3_sen1,e3_sen1]
after Tokenize->
[e1_tokens1,e1_tokens1,e1_tokens1,e1_tokens1,
e2_tokens1,e2_tokens1,e2_tokens1,e2_tokens1,
e3_tokens1,e3_tokens1,e3_tokens1]
- 经过tokenizer后,再转回每个样本有备选项个数输入id、注意力掩码等。
after unflatten->
[[e1_tokens1,e1_tokens1,e1_tokens1,e1_tokens1],
[e2_tokens1,e2_tokens1,e2_tokens1,e2_tokens1]
[e3_tokens1,e3_tokens1,e3_tokens1]]
参数truncation=True使得比模型所能接受最大长度还长的输入被截断。
ending_names = ["ending0", "ending1", "ending2", "ending3"]
def preprocess_function(examples):
# 预处理输入tokenizer的输入
# Repeat each first sentence four times to go with the four possibilities of second sentences.
first_sentences = [[context] * 4 for context in examples["sent1"]]#构造和备选项个数相同的问题句,也是tokenizer的第一个句子
# Grab all second sentences possible for each context.
question_headers = examples["sent2"] #tokenizer的第二个句子的上半句
second_sentences = [[f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)]#构造上半句拼接下半句作为tokenizer的第二个句子(也就是备选项)
# Flatten everything
first_sentences = sum(first_sentences, []) #合并成一个列表方便tokenizer一次性处理:[[e1_sen1,e1_sen1,e1_sen1,e1_sen1],[e2_sen1,e2_sen1,e2_sen1,e2_sen1],[e3_sen1,e3_sen1,e3_sen1,e3_sen1]]->[e1_sen1,e1_sen1,e1_sen1,e1_sen1,e2_sen1,e2_sen1,e2_sen1,e2_sen1,e3_sen1,e3_sen1,e3_sen1,e3_sen1]
second_sentences = sum(second_sentences, [])#合并成一个列表方便tokenizer一次性处理
# Tokenize
tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
# Un-flatten
# 转化成每个样本(一个样本中包括了四个k=[问题1,问题1,问题1,问题1],v=[备选项1,备选项2,备选项3,备选项4])
# [e1_tokens1,e1_tokens1,e1_tokens1,e1_tokens1,e2_tokens1,e2_tokens1,e2_tokens1,e2_tokens1,e3_tokens1,e3_tokens1,e3_tokens1,e3_tokens1]->[[e1_tokens1,e1_tokens1,e1_tokens1,e1_tokens1],[e2_tokens1,e2_tokens1,e2_tokens1,e2_tokens1],[e3_tokens1,e3_tokens1,e3_tokens1]]
return {k: [v[i:i+4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
以上的预处理函数可以处理一个样本,也可以处理多个样本exapmles。如果是处理多个样本,则返回的是多个样本被预处理之后的结果list。
让我们解码一下给定示例的输入,可以看到一个样本对应四个问题和备选项合并的句子。
examples = datasets["train"][:5]
features = preprocess_function(examples)
idx = 3
[tokenizer.decode(features["input_ids"][idx][i]) for i in range(4)]
#['[CLS] a drum line passes by walking down the street playing their instruments. [SEP] members of the procession are playing ping pong and celebrating one left each in quick. [SEP]',
# '[CLS] a drum line passes by walking down the street playing their instruments. [SEP] members of the procession wait slowly towards the cadets. [SEP]',
# '[CLS] a drum line passes by walking down the street playing their instruments. [SEP] members of the procession makes a square call and ends by jumping down into snowy streets where fans begin to take their positions. [SEP]',
# '[CLS] a drum line passes by walking down the street playing their instruments. [SEP] members of the procession play and go back and forth hitting the drums while the audience claps for them. [SEP]']
接下来使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将预处理函数prepare_train_features应用到(map)所有样本上。参数batched=True可以批量对文本进行编码。这是为了充分利用前面加载fast_tokenizer的优势,它将使用多线程并发地处理批中的文本。
tokenized_datasets = datasets.map(preprocess_function, batched=True)
微调
加载预训练模型
做多项选择任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForMultipleChoice 这个类。
from transformers import AutoModelForMultipleChoice
model = AutoModelForMultipleChoice.from_pretrained(model_checkpoint)
设定训练参数
task='ner'
batch_size = 16
from transformers import TrainingArguments
args = TrainingArguments(
"test-glue",
evaluation_strategy = "epoch",
learning_rate=5e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
)
数据收集器data collator
接下来需要告诉Trainer如何从预处理的输入数据中构造batch。我们使用数据收集器data collator,将经预处理的输入分batch再次处理后喂给模型。
由前面preprocess_function函数的输出我们可以看到,每个样本都还没有做padding,我们在data collator中按照batch将每个batch的句子padding到每个batch最长的长度。注意,因为不同batch中最长的句子不一定都和整个数据集中的最长句子一样长,也就是说不是每个batch都需要那么长的padding,所以这里不直接padding到最大长度,可以有效提升训练效率。
由于transformers库中没有合适的data collator来处理这样特定的问题,我们根据DataCollatorWithPadding稍作改动改编一个合适的。我在代码中补充了features和batch逐步转化的格式变化过程:
from dataclasses import dataclass
from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
from typing import Optional, Union
import torch
@dataclass
class DataCollatorForMultipleChoice:
"""
Data collator that will dynamically pad the inputs for multiple choice received.
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features):
#features:[{'attention_mask':[[],[],...],'input_ids':[[],[],...,'label':_},{'attention_mask':[[],[],...],'input_ids':[[],[],...,'label':_}]
label_name = "label" if "label" in features[0].keys() else "labels"
labels = [feature.pop(label_name) for feature in features] #将label单独弹出,features:[{'attention_mask':[[],[],...],'input_ids':[[],[],...]},{'attention_mask':[[],[],...],'input_ids':[[],[],...]}]
batch_size = len(features)
num_choices = len(features[0]["input_ids"])
#feature:{'attention_mask':[[],[],...],'input_ids':[[],[],...]}
#flattened_features:[[{'attention_mask':[],'input_ids':[]},{},{},{}],[]....]
flattened_features = [[{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features]
#flattened_features:[{'attention_mask':[],'input_ids':[]},{},{},{},{}....]
flattened_features = sum(flattened_features, [])
# batch: {'attention_mask':[[],[],[],[],[],[],...],'input_ids':[[],[],[],[],[],[],...]}
batch = self.tokenizer.pad(
flattened_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
# Un-flatten
# batch: {'attention_mask':[[[],[],[],[]],[[],[],[],[]],[...],...],'input_ids':[[[],[],[],[]],[[],[],[],[]],[...],...]}
batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
# Add back labels
# batch: {'attention_mask':[[[],[],[],[]],[[],[],[],[]],[...],...],'input_ids':[[[],[],[],[]],[[],[],[],[]],[...],...],'label':[]}
batch["labels"] = torch.tensor(labels, dtype=torch.int64)
return batch
在一个10个样本的batch上检查data collator是否正常工作。
在这里我们需要确保features中只有被模型接受的输入特征(但这一步在后面Trainer自动会筛选):
accepted_keys = ["input_ids", "attention_mask", "label"]
features = [{k: v for k, v in encoded_datasets["train"][i].items() if k in accepted_keys} for i in range(10)]
batch = DataCollatorForMultipleChoice(tokenizer)(features)
然后让我们检查单个样本是否完整,利用之前的show_one函数进行对比,看来没错!
[tokenizer.decode(batch["input_ids"][8][i].tolist()) for i in range(4)]
#['[CLS] someone walks over to the radio. [SEP] someone hands her another phone. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]',
# '[CLS] someone walks over to the radio. [SEP] someone takes the drink, then holds it. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]',
# '[CLS] someone walks over to the radio. [SEP] someone looks off then looks at someone. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]',
# '[CLS] someone walks over to the radio. [SEP] someone stares blearily down at the floor. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]']
show_one(datasets["train"][8])
# Context: Someone walks over to the radio.
# A - Someone hands her another phone.
# B - Someone takes the drink, then holds it.
# C - Someone looks off then looks at someone.
# D - Someone stares blearily down at the floor.
#
# Ground truth: option D
定义评估方法
我们使用accuracy对模型进行评估。
需要定义一个函数计算返回精度,取预测logits的argmax得到预测标签preds,和ground_truth进行进行对比,计算精度:
import numpy as np
from datasets import load_metric
def compute_metrics(eval_predictions):
predictions, label_ids = eval_predictions
preds = np.argmax(predictions, axis=1)
return {"accuracy": (preds == label_ids).astype(np.float32).mean().item()}
from transformers import Trainer
trainer = Trainer(
model,
args,
train_dataset=encoded_datasets["train"],
eval_dataset=encoded_datasets["validation"],
tokenizer=tokenizer,
data_collator=DataCollatorForMultipleChoice(tokenizer),
compute_metrics=compute_metrics,
)
trainer.train()
问答任务-抽取式问答
任务介绍
注意我们这里主要解决的是抽取式问答任务:给定一个问题和一段文本,从这段文本中找出能回答该问题的文本片段(span)。抽取式问答任务是从文本中抽取答案,并不是直接生成答案。
输入:
问题:我家在哪里?
文本:我的家在东北。
输出:东北
主要分为一下几个部分
- 数据加载
- 数据预处理
- 微调预训练模型
- 模型评估
数据加载
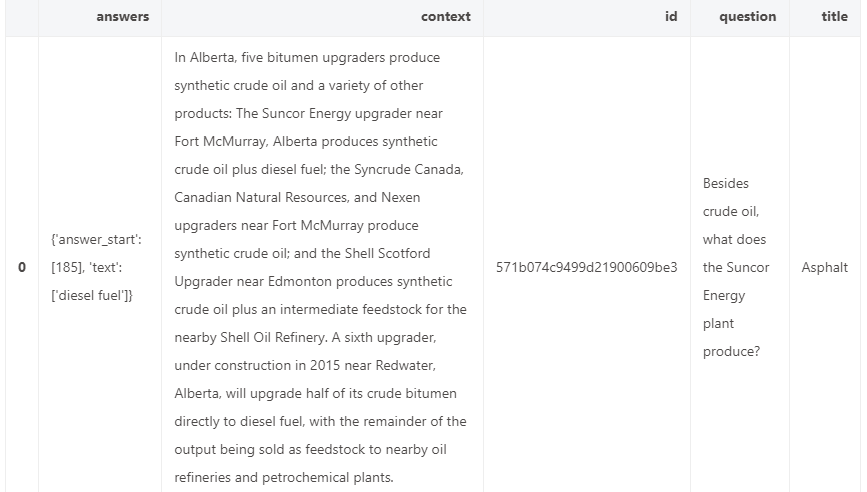
我们使用的数据集是SQUAD 2,Stanford Question Answering Dataset (SQuAD) 是一个阅读理解数据集,由众工对一组维基百科文章提出的问题组成,每个问题的答案都是从相应的阅读文章中节选出来的,或者这个问题可能是无法回答的。
# squad_v2等于True或者False分别代表使用SQUAD v1 或者 SQUAD v2。
# 如果您使用的是其他数据集,那么True代表的是:模型可以回答“不可回答”问题,也就是部分问题不给出答案,而False则代表所有问题必须回答。
squad_v2 = False
# 下载数据(确保有网络)
datasets = load_dataset("squad_v2" if squad_v2 else "squad")
数据预处理
初始化Tokenizer
from transformers import AutoTokenizer
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
转化成对应任务的输入模型的格式
机器问答预训练模型通常将question和context拼接之后作为输入,然后让模型从context里寻找答案。对于context中无答案的情况,我们直接将标注的答案起始位置和结束位置放置在CLS的下标处。
我们将question作为tokenizer的句子1,context作为tokenizer的句子2,tokenizer会将他们拼接起来并加入特殊字符作为模型输入
example = datasets["train"][0]
tokenized_example=tokenizer(example["question"], example["context"])
tokenized_example["input_ids"]
#[101,2000,3183,2106,1996,6261,2984,9382,3711,1999,8517,1999,10223,26371,2605,1029,102,6549,2135,1010,1996,2082,2038,1037,3234,2839,1012,10234,1996,2364,2311,1005,1055,2751,8514,2003,1037,3585,6231,1997,1996,6261,2984,1012,3202,1999,2392,1997,1996,2364,2311,1998,5307,2009,1010,2003,1037,6967,6231,1997,4828,2007,2608,2039,14995,6924,2007,1996,5722,1000,2310,3490,2618,4748,2033,18168,5267,1000,1012,2279,2000,1996,2364,2311,2003,1996,13546,1997,1996,6730,2540,1012,3202,2369,1996,13546,2003,1996,24665,23052,1010,1037,14042,2173,1997,7083,1998,9185,1012,2009,2003,1037,15059,1997,1996,24665,23052,2012,10223,26371,1010,2605,2073,1996,6261,2984,22353,2135,2596,2000,3002,16595,9648,4674,2061,12083,9711,2271,1999,8517,1012,2012,1996,2203,1997,1996,2364,3298,1006,1998,1999,1037,3622,2240,2008,8539,2083,1017,11342,1998,1996,2751,8514,1007,1010,2003,1037,3722,1010,2715,2962,6231,1997,2984,1012,102]
我们使用sequence_ids方法来获取mask区分question和context。 None对应了special tokens,然后0或者1分表代表第1个文本和第2个文本,由于我们question第1个传入,context第2个传入,所以分别对应question和context。
sequence_ids = tokenized_example.sequence_ids()
print(sequence_ids)
#[None,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,None,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,None]
现在需要特别思考一个问题:当遇到超长context时(超过了模型能处理的最大长度)会不会对模型造成影响呢?
一般来说预训练模型输入有最大长度要求,然后通常将超长输入进行截断。但是,如果我们将问答数据三元组<question, context, answer>中超长context截断,那么可能丢掉答案(因为是从context中抽取出一个小片段作为答案)。
那么预训练机器问答模型是如何处理超长文本的呢?
我们首先找到一个超过模型最大长度的例子,然后分析处理上述问题的机制。
for循环遍历数据集,寻找一个超长样本,我们前面选择的模型所要求的最大输入是384(经常使用的还有512):
for i, example in enumerate(datasets["train"]):
if len(tokenizer(example["question"], example["context"])["input_ids"]) > 384:
break
example = datasets["train"][i]
如果不截断的话,那么输入的长度是396,如果我们截断成最大长度384,将会丢失超长部分的信息
len(tokenizer(example["question"], example["context"])["input_ids"])
#396
len(tokenizer(example["question"], example["context"], max_length=max_length, truncation="only_second")["input_ids"]) #truncation="only_second"表示只对句子2进行截断
#384
我们把超长的输入切片为多个较短的输入,每个输入都要满足模型最大长度输入要求。由于答案可能存在与切片的地方,因此允许相邻切片之间有交集,tokenizer中通过doc_stride参数控制。
预训练模型的tokenizer包装了方法帮助我们完成上述步骤,只需要设定一些参数即可。
max_length = 384 # 输入feature的最大长度,question和context拼接之后
doc_stride = 128 # 2个切片之间的重合token数量。
注意:一般来说,我们只对context进行切片,不会对问题进行切片,由于context是拼接在question后面的,对应着第2个文本,所以使用only_second控制。tokenizer使用doc_stride控制切片之间的重合长度。
tokenized_example = tokenizer(
example["question"],
example["context"],
max_length=max_length,
truncation="only_second",
return_overflowing_tokens=True,
stride=doc_stride
)
[len(x) for x in tokenized_example["input_ids"]]
#[384, 157]
#我们可以将预处理后的token IDs,input_ids还原为文本格式,方便检查切片结果。可以发现tokenizer自动帮我们为第二个切片的context拼接了question文本。
for i, x in enumerate(tokenized_example["input_ids"][:2]):
print("切片: {}".format(i))
print(tokenizer.decode(x))
#切片: 0
#[CLS] how many wins does the notre dame men's basketball team have? [SEP] the men's basketball team has over 1, 600 wins, one of only 12 schools who have reached that mark, and have appeared in 28 ncaa tournaments. former player austin carr holds the record for most points scored in a single game of the tournament with 61. although the team has never won the ncaa tournament, they were named by the helms athletic foundation as national champions twice. the team has orchestrated a number of upsets of number one ranked teams, the most notable of which was ending ucla's record 88 - game winning streak in 1974. the team has beaten an additional eight number - one teams, and those nine wins rank second, to ucla's 10, all - time in wins against the top team. the team plays in newly renovated purcell pavilion ( within the edmund p. joyce center ), which reopened for the beginning of the 2009 – 2010 season. the team is coached by mike brey, who, as of the 2014 – 15 season, his fifteenth at notre dame, has achieved a 332 - 165 record. in 2009 they were invited to the nit, where they advanced to the semifinals but were beaten by penn state who went on and beat baylor in the championship. the 2010 – 11 team concluded its regular season ranked number seven in the country, with a record of 25 – 5, brey's fifth straight 20 - win season, and a second - place finish in the big east. during the 2014 - 15 season, the team went 32 - 6 and won the acc conference tournament, later advancing to the elite 8, where the fighting irish lost on a missed buzzer - beater against then undefeated kentucky. led by nba draft picks jerian grant and pat connaughton, the fighting irish beat the eventual national champion duke blue devils twice during the season. the 32 wins were [SEP]
#切片: 1
#[CLS] how many wins does the notre dame men's basketball team have? [SEP] championship. the 2010 – 11 team concluded its regular season ranked number seven in the country, with a record of 25 – 5, brey's fifth straight 20 - win season, and a second - place finish in the big east. during the 2014 - 15 season, the team went 32 - 6 and won the acc conference tournament, later advancing to the elite 8, where the fighting irish lost on a missed buzzer - beater against then undefeated kentucky. led by nba draft picks jerian grant and pat connaughton, the fighting irish beat the eventual national champion duke blue devils twice during the season. the 32 wins were the most by the fighting irish team since 1908 - 09. [SEP]
我们知道机器问答模型将使用答案的位置(答案的起始位置和结束位置,start和end)作为训练标签(而不是答案的token IDS)。那么由于进行了切片,一个新的问题出现了:答案所在的位置被改变了,因此需要重新寻找答案所在位置(相对于每一片context开头的相对位置)。
所以切片需要和原始输入有一个对应关系,每个token在切片后context的位置和原始超长context里位置的对应关系。
获取切片前后的位置对应关系
在tokenizer里可以使用return_offsets_mapping=True参数得到这个对应关系的map:
tokenized_example = tokenizer(
example["question"],
example["context"],
max_length=max_length,
truncation="only_second",
return_overflowing_tokens=True,
return_offsets_mapping=True,
stride=doc_stride
)
我们打印tokenized_example切片1(也就是第二个切片,前30个tokens)在原始context片里的位置。注意特殊token是(如[CLS]设定为(0, 0)),是因为这个token不属于qeustion或者answer的一部分。第2个token对应的起始和结束位置是0和3。可以发现切片1context部分第2个token没有从(0,N)标记,而是从记录了其在原本超长文本中的位置。
# 打印切片前后位置下标的对应关系
print(tokenized_example["offset_mapping"][1][:30])
#[(0, 0), (0, 3), (4, 8), (9, 13), (14, 18), (19, 22), (23, 28), (29, 33), (34, 37), (37, 38), (38, 39), (40, 50), (51, 55), (56, 60), (60, 61), (0, 0), (1093, 1105), (1105, 1106), (1107, 1110), (1111, 1115), (1115, 1116), (1116, 1118), (1119, 1123), (1124, 1133), (1134, 1137), (1138, 1145), (1146, 1152), (1153, 1159), (1160, 1166), (1167, 1172)]
因此我们可以根据切片后的token id转化对应的token,然后使用offset_mapping参数映射回切片前的token位置,找到原始位置的tokens。由于question拼接在context前面,所以直接从question里根据下标找。
first_token_id = tokenized_example["input_ids"][0][1] #2129
offsets = tokenized_example["offset_mapping"][0][1] #(0, 3)
print(tokenizer.convert_ids_to_tokens([first_token_id])[0], example["question"][offsets[0]:offsets[1]])
#how How
因此我们得到更新答案相对切片context位置的流程:
- 我们首先找到context在句子1和句子2拼接后的句子中的起始位置token_start_index、终止位置token_end_index;
- 然后判断答案是否在文本区间外部: 2.1. 若在,则更新答案的位置; 2.2. 若不在,则让答案标注在CLS token位置。
最终我们可以更新标注的答案在预处理之后的features里的位置:
answers = example["answers"] #答案{'answer_start': [30], 'text': ['over 1,600']}
start_char = answers["answer_start"][0] #答案起始位置30
end_char = start_char + len(answers["text"][0])#答案终止位置40
# 找到当前文本的Start token index.
token_start_index = 0 #得到context在句子1和句子2拼接后的句子中的起始位置
while sequence_ids[token_start_index] != 1: #sequence_ids区分question和context
token_start_index += 1
# 找到当前文本的End token index.
token_end_index = len(tokenized_example["input_ids"][0]) - 1#得到context在句子1和句子2拼接后的句子中的终止位置,可能还要去掉一些padding
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# 检测答案是否在文本区间的外部,这种情况下意味着该样本的数据标注在CLS token位置。
offsets = tokenized_example["offset_mapping"][0]
if (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char): #答案在文本内
# 将token_start_index和token_end_index移动到answer所在位置的两侧.
# 注意:答案在最末尾的边界条件.
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1 #之前的token_start_index在context的第一个token位置
start_position = token_start_index - 1
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1#之前的token_end_index在context的最后一个token位置
end_position = token_end_index + 1
print("start_position: {}, end_position: {}".format(start_position, end_position))
else: #答案在文本外
print("The answer is not in this feature.")
start_position: 23, end_position: 26
我们对答案的位置进行验证:使用答案所在位置下标,取到对应的token ID,然后转化为文本,然后和原始答案进行但对比。
print(tokenizer.decode(tokenized_example["input_ids"][0][start_position: end_position+1]))
print(answers["text"][0])
over 1, 600 over 1,600
此外,还需要注意的是:有时候question拼接context,而有时候是context拼接question,不同的模型有不同的要求,因此我们需要使用padding_side参数来指定。
pad_on_right = tokenizer.padding_side == "right" #context在右边
现在,把所有步骤合并到一起。如果allow_impossible_answers这个参数是False的话,无答案的样本都会被扔掉。
def prepare_train_features(examples):
# 既要对examples进行truncation(截断)和padding(补全)还要还要保留所有信息,所以要用的切片的方法。
# 每一个超长文本example会被切片成多个输入,相邻两个输入之间会有交集。
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# 我们使用overflow_to_sample_mapping参数来映射切片片ID到原始ID。
# 比如有2个expamples被切成4片,那么对应是[0, 0, 1, 1],前两片对应原来的第一个example。
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# offset_mapping也对应4片
# offset_mapping参数帮助我们映射到原始输入,由于答案标注在原始输入上,所以有助于我们找到答案的起始和结束位置。
offset_mapping = tokenized_examples.pop("offset_mapping")
# 重新标注数据
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
# 对每一片进行处理
# 将无答案的样本标注到CLS上
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 区分question和context
sequence_ids = tokenized_examples.sequence_ids(i)
# 拿到原始的example 下标.
sample_index = sample_mapping[i]
answers = examples["answers"][sample_index]
# 如果没有答案,则使用CLS所在的位置为答案.
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# 答案的character级别Start/end位置.
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# 找到token级别的index start.
token_start_index = 0
while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
token_start_index += 1
# 找到token级别的index end.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
token_end_index -= 1
# 检测答案是否超出文本长度,超出的话也使用CLS index作为标注.
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# 如果不超出则找到答案token的start和end位置。.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
以上的预处理函数可以处理一个样本,也可以处理多个样本exapmles。如果是处理多个样本,则返回的是多个样本被预处理之后的结果list。
接下来使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将预处理函数prepare_train_features应用到(map)所有样本上。参数batched=True可以批量对文本进行编码。这是为了充分利用前面加载fast_tokenizer的优势,它将使用多线程并发地处理批中的文本。
tokenized_datasets = datasets.map(prepare_train_features, batched=True, remove_columns=datasets["train"].column_names)
微调预训练模型
加载预训练模型
做机器问答任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForQuestionAnswering 这个类。 和之前几篇博客提到的加载方式相同不再赘述。
from transformers import AutoModelForQuestionAnswering
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
设定训练参数
为了能够得到一个Trainer训练工具,我们还需要训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
from transformers import TrainingArguments
args = TrainingArguments(
f"test-squad",
evaluation_strategy = "epoch",
learning_rate=2e-5, #学习率
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3, # 训练的次数
weight_decay=0.01,
)
数据收集器data collator
接下来需要告诉Trainer如何从预处理的输入数据中构造batch。我们使用数据收集器data collator,将经预处理的输入分batch再次处理后喂给模型。
我们使用一个default_data_collator将预处理好的数据喂给模型。
from transformers import default_data_collator
data_collator = default_data_collator
定义评估方法
注意,本次训练的时候,我们将只会计算loss,暂时不定义评估方法。
开始训练
将数据/模型/参数传入Trainer即可:
from transformers import Trainer
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
#及时保存模型
trainer.save_model("test-squad-trained")
模型的输出是answer所在start/end位置的logits。 用第一个batch来举一个例子:
import torch
for batch in trainer.get_eval_dataloader(): #产生batch的迭代器
break
batch = {k: v.to(trainer.args.device) for k, v in batch.items()}
with torch.no_grad():
output = trainer.model(**batch)
output.keys()
#odict_keys(['loss', 'start_logits', 'end_logits'])
还记得我们在分析BERT-based Model源码时,也可以看出BertForQuestionAnswering的输出包括:
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
我们在输出预测结果的时候不需要看loss,每个feature(切片)里的每个token都会有两个logit值(分别组成start_logits,end_logits),直接根据logits找到答案的位置即可。
如何根据logits找到答案的位置?
- 方法1
- 预测answer最简单的方法就是选择start_logits里最大的下标作为answer起始位置,end_logits里最大下标作为answer的结束位置。
output.start_logits.shape, output.end_logits.shape
#(torch.Size([16, 384]), torch.Size([16, 384]))
output.start_logits.argmax(dim=-1), output.end_logits.argmax(dim=-1)
# (tensor([ 46, 57, 78, 43, 118, 15, 72, 35, 15, 34, 73, 41, 80, 91, 156, 35], device='cuda:0'),tensor([ 47, 58, 81, 55, 118, 110, 75, 37, 110, 36, 76, 53, 83, 94, 158, 35], device='cuda:0'))
- 方法2
-
该策略大部分情况下都是不错的。但是,如果我们的输入告诉我们找不到答案:比如start的位置比end的位置下标大,或者start和end的位置指向了question。该怎么办呢? 这个时候,简单的方法是继续需要选择第2好的预测作为答案,实在不行看第3好的预测,以此类推。
但是方法2不太容易找到可行的答案,还有没有更合理一些的方法呢?
- 方法3
- 分为四个步骤:
我们先找到最好的n_best_size个(自定义)start和end对应的可能的备选起始点和终止点; 从中先构建合理的备选答案,不合理的情况包括以下几种: start>end的备选起始点和终止点; start或end超过最大长度; start和end位置对应的文本在question里面而不在context里面(这里埋了一个雷,); 然后将合理备选答案的start和end的logits相加得到新的打分; 最后我们根据score对valid_answers进行排序,找到最好的那一个做为答案。 为了找到第3种不合理的情况,我们在validation的features里添加以下两个信息:
产生feature的example ID-overflow_to_sample_mapping:由于每个example可能会产生多个feature,所以每个feature/切片的feature需要知道他们对应的example是哪一个。 offset mapping-offset_mapping: 将每个切片tokens的位置映射回原始文本基于character的下标位置,把question部分的offset_mapping用None掩码,context部分保留不变。 我们现在利用一个prepare_validation_features函数处理validation验证集,添加上面两个信息,该函数和处理训练的时候的prepare_train_features稍有不同。然后利用处理后的验证集进行评估
def prepare_validation_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
# 我们使用overflow_to_sample_mapping参数来映射切片片ID到原始ID。
# 比如有2个expamples被切成4片,那么对应是[0, 0, 1, 1],前两片对应原来的第一个example。
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# We keep the example_id that gave us this feature and we will store the offset mappings.
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
# One example can give several spans, this is the index of the example containing this span of text.
# 拿到原始的example 下标.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
# 检查答案是否在context中,如果不在offset_mapping为None
# 其实就是把question部分的offset_mapping用None掩码,context部分保留不变
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
和之前一样将prepare_validation_features函数应用到每个验证集合的样本上。
validation_features = datasets["validation"].map(
prepare_validation_features,
batched=True,
remove_columns=datasets["validation"].column_names
)
使用Trainer.predict方法获得所有预测结果:
raw_predictions = trainer.predict(validation_features)
#这个 Trainer 隐藏了 一些模型训练时候没有使用的属性(这里是 example_id和offset_mapping,后处理的时候会用到),所以我们需要把这些设置回来:
validation_features.set_format(type=validation_features.format["type"], columns=list(validation_features.features.keys()))
#经过前面的prepare_validation_features函数处理,当一个token位置对应question部分offset mappings为None,所以我们根据offset mapping可以判断token是否在context里面。
#更近一步地,我们用max_answer_length控制去掉特别长的答案。
n_best_size = 20
max_answer_length = 30
start_logits = output.start_logits[0].cpu().numpy()
end_logits = output.end_logits[0].cpu().numpy()
offset_mapping = validation_features[0]["offset_mapping"]
# The first feature comes from the first example. For the more general case, we will need to be match the example_id to
# an example index
context = datasets["validation"][0]["context"]
# 收集最佳的start和end logits的位置
# Gather the indices the best start/end logits:
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
valid_answers = []
for start_index in start_indexes:
for end_index in end_indexes:
# Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
# to part of the input_ids that are not in the context.
if (#答案不合理
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or offset_mapping[end_index] is None
):
continue
# Don't consider answers with a length that is either < 0 or > max_answer_length.
if end_index < start_index or end_index - start_index + 1 > max_answer_length:#答案不合理
continue
if start_index <= end_index: # We need to refine that test to check the answer is inside the context # 如果start小于end,那么是合理的可能答案
start_char = offset_mapping[start_index][0]
end_char = offset_mapping[end_index][1]
valid_answers.append(
{
"score": start_logits[start_index] + end_logits[end_index],
"text": context[start_char: end_char]# 后续需要根据token的下标将答案找出来
}
)
#最后根据`score`对`valid_answers`进行排序,找到最好的那一个
valid_answers = sorted(valid_answers, key=lambda x: x["score"], reverse=True)[:n_best_size]
valid_answers
这里还有一个问题需要思考:
当一个example被分成多个切片输入模型,模型会把这些切片当作多个单独的“样本”进行训练,那我们在计算正确率和召回率的时候,不能以这多个切片为单位直接计算,而是应该将其对应的一个example为单位进行计算。
对于上面地例子来说,由于答案正好在第1个feature,而第1个feature一定是来自于第1个example,所以相对容易。对于一个超长example产生的其他fearures来说,需要一个features和examples进行映射的map。因此由于一个example可能被切片成多个features,所以我们需要将所有features里的答案全部收集起来。
以下的代码就将exmaple的下标和features的下标进行map映射。
import collections
examples = datasets["validation"]
features = validation_features
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
对于后处理过程基本上已经全部完成了。
但是这里还还还有一个问题:如何解决无答案的情况(squad_v2=True)。
以上的代码都只考虑了context里面的asnwers,我们同样需要将无答案的预测得分进行搜集(无答案的预测对应了CLS token的start和end logits)。如果一个example样本有多个features,那么我们还需要在多个features里预测是不是都无答案。所以无答案的最终得分是所有features的无答案得分最小的那个。(为什么是最小的那个呢?因为答案如果只在一个切片里,其他切片肯定是没有答案的,如果要确保整个example是没有答案的话,相当于最有可能有答案的切片里面也没有答案)只要无答案的最终得分高于其他所有答案的得分,那么该问题就是无答案。
最终的后处理函数:
from tqdm.auto import tqdm
def postprocess_qa_predictions(examples, features, raw_predictions, n_best_size = 20, max_answer_length = 30):
all_start_logits, all_end_logits = raw_predictions
# Build a map example to its corresponding features.
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
# The dictionaries we have to fill.
predictions = collections.OrderedDict()
# Logging.
print(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
# Let's loop over all the examples!
for example_index, example in enumerate(tqdm(examples)):
# Those are the indices of the features associated to the current example.
feature_indices = features_per_example[example_index]
min_null_score = None # Only used if squad_v2 is True.
valid_answers = []
context = example["context"]
# Looping through all the features associated to the current example.
for feature_index in feature_indices:
# We grab the predictions of the model for this feature.
start_logits = all_start_logits[feature_index]
end_logits = all_end_logits[feature_index]
# This is what will allow us to map some the positions in our logits to span of texts in the original
# context.
offset_mapping = features[feature_index]["offset_mapping"]
# Update minimum null prediction.
cls_index = features[feature_index]["input_ids"].index(tokenizer.cls_token_id)
feature_null_score = start_logits[cls_index] + end_logits[cls_index]
if min_null_score is None or min_null_score < feature_null_score:
min_null_score = feature_null_score
# Go through all possibilities for the `n_best_size` greater start and end logits.
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
# to part of the input_ids that are not in the context.
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or offset_mapping[end_index] is None
):
continue
# Don't consider answers with a length that is either < 0 or > max_answer_length.
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
start_char = offset_mapping[start_index][0]
end_char = offset_mapping[end_index][1]
valid_answers.append(
{
"score": start_logits[start_index] + end_logits[end_index],
"text": context[start_char: end_char]
}
)
if len(valid_answers) > 0:
best_answer = sorted(valid_answers, key=lambda x: x["score"], reverse=True)[0]
else:
# In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
# failure.
best_answer = {"text": "", "score": 0.0}
# Let's pick our final answer: the best one or the null answer (only for squad_v2)
if not squad_v2:
predictions[example["id"]] = best_answer["text"]
else:
answer = best_answer["text"] if best_answer["score"] > min_null_score else ""
predictions[example["id"]] = answer
return predictions
将后处理函数应用到原始预测输出上:
final_predictions = postprocess_qa_predictions(datasets["validation"], validation_features, raw_predictions.predictions)
加载评测指标
from datasets import load_metric
metric = load_metric("squad_v2" if squad_v2 else "squad")
基于预测和标注对评测指标进行计算。为了合理的比较,我们需要将预测和标注的格式。对于squad2来说,评测指标还需要no_answer_probability参数(由于已经无答案直接设置成了空字符串,所以这里直接将这个参数设置为0.0)
if squad_v2:
formatted_predictions = [{"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()]
else:
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in final_predictions.items()]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in datasets["validation"]]
metric.compute(predictions=formatted_predictions, references=references)
生成任务-机器翻译
任务介绍
翻译任务,把一种语言信息转变成另一种语言信息。是典型的seq2seq任务,输入为一个序列,输出为不固定长度(由机器自行学习生成的序列应该多长)的序列。
比如输入一句中文,翻译为英文:
输入:我爱中国。
输出:I love China.
数据加载
数据集介绍
我们使用WMT dataset数据集。这是翻译任务最常用的数据集之一。其中包括English/Romanian双语翻译。
加载数据
该数据的加载方式在transformers库中进行了封装,我们可以通过以下语句进行数据加载:
pip install datasets transformers sacrebleu sentencepiece
#transformers==4.9.2
#datasets==1.11.0
#sacrebleu==1.5.1
#sentencepiece==0.1.96
from datasets import load_dataset
raw_datasets = load_dataset("wmt16", "ro-en")
raw_datasets["train"][0]
# 我们可以看到一句英语en对应一句罗马尼亚语言ro
# {'translation': {'en': 'Membership of Parliament: see Minutes','ro': 'Componenţa Parlamentului: a se vedea procesul-verbal'}}
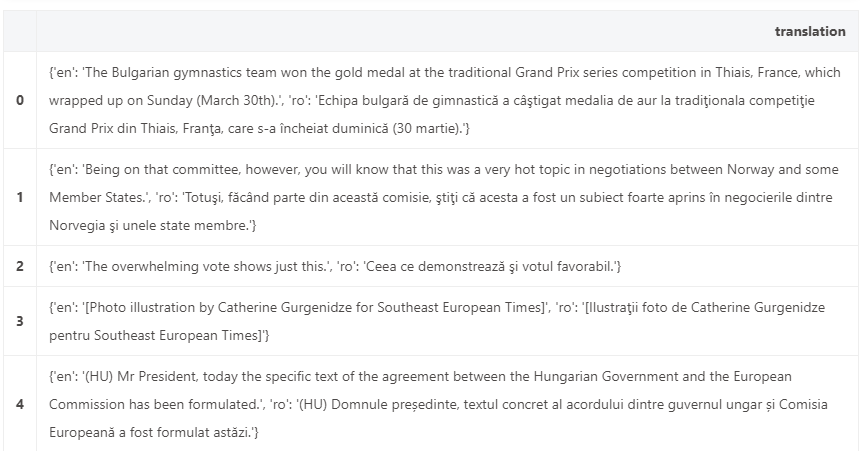
数据预处理
初始化Tokenizer
from transformers import AutoTokenizer
model_checkpoint = "Helsinki-NLP/opus-mt-en-ro"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
if "mbart" in model_checkpoint:
tokenizer.src_lang = "en-XX"
tokenizer.tgt_lang = "ro-RO"
转化成对应任务输入模型的格式
with tokenizer.as_target_tokenizer():
print(tokenizer("Hello, this one sentence!"))
model_input = tokenizer("Hello, this one sentence!")
tokens = tokenizer.convert_ids_to_tokens(model_input['input_ids'])
# 打印看一下special toke
print('tokens: {}'.format(tokens))
#{'input_ids': [10334, 1204, 3, 15, 8915, 27, 452, 59, 29579, 581, 23, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
#tokens: ['▁Hel', 'lo', ',', '▁', 'this', '▁o', 'ne', '▁se', 'nten', 'ce', '!', '</s>']
如果使用的是T5预训练模型的checkpoints,需要对特殊的前缀进行检查。T5使用特殊的前缀来告诉模型具体要做的任务(”translate English to Romanian: “),具体前缀例子如下:
if model_checkpoint in ["t5-small", "t5-base", "t5-larg", "t5-3b", "t5-11b"]:
prefix = "translate English to Romanian: "
else:
prefix = ""
现在我们可以把上面的内容放在一起组成预处理函数preprocess_function。对样本进行预处理的时候,使用truncation=True参数来确保超长文本被截断。默认情况下,对与比较短的句子会自动padding。
max_input_length = 128
max_target_length = 128
source_lang = "en"
target_lang = "ro"
def preprocess_function(examples):
inputs = [prefix + ex[source_lang] for ex in examples["translation"]]
targets = [ex[target_lang] for ex in examples["translation"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
以上的预处理函数可以处理一个样本,也可以处理多个样本exapmles。如果是处理多个样本,则返回的是多个样本被预处理之后的结果list。
接下来使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将预处理函数preprocess_function应用到(map)所有样本上。参数batched=True可以批量对文本进行编码。这是为了充分利用前面加载fast_tokenizer的优势,它将使用多线程并发地处理批中的文本。
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
加载预训练模型
做seq2seq任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForSeq2SeqLM 这个类。
from transformers import AutoModelForSeq2SeqLM,
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
设定训练参数
from transformers import Seq2SeqTrainingArguments
batch_size = 16
args = Seq2SeqTrainingArguments(
"test-translation",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3, #至多保存模型个数
num_train_epochs=1,
predict_with_generate=True,
fp16=False,
)
数据收集器data collator
接下来需要告诉Trainer如何从预处理的输入数据中构造batch。我们使用数据收集器DataCollatorForSeq2Seq,将经预处理的输入分batch再次处理后喂给模型。
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
定义评估方法
我们使用’bleu’指标,利用metric.compute计算该指标对模型进行评估。
metric.compute对比predictions和labels,从而计算得分。predictions和labels都需要是一个list。具体格式见下面的例子:
fake_preds = ["hello there", "general kenobi"]
fake_labels = [["hello there"], ["general kenobi"]]
metric.compute(predictions=fake_preds, references=fake_labels)
#{'bp': 1.0,
# 'counts': [4, 2, 0, 0],
# 'precisions': [100.0, 100.0, 0.0, 0.0],
# 'ref_len': 4,
# 'score': 0.0,
# 'sys_len': 4,
# 'totals': [4, 2, 0, 0]}
# 将模型预测送入评估之前,还需要写postprocess_text函数做一些数据后处理:
import numpy as np
from datasets import load_metric
metric = load_metric("sacrebleu")
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
开始训练
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
生成任务-生成摘要
任务介绍
摘要生成,用一些精炼的话(摘要)来概括整片文章的大意,用户通过读文摘就可以了解到原文要表达。
数据加载
数据集介绍
我们使用XSum dataset数据集,其中包含了多篇BBC的文章和一句对应的摘要。
加载数据
pip install datasets transformers rouge-score nltk
#transformers==4.9.2
#datasets==1.11.0
#rouge-score==0.0.4
#nltk==3.6.2
from datasets import load_dataset
raw_datasets = load_dataset("xsum")
raw_datasets["train"][0]
# {'document': 'Recent reports have linked some France-based players with returns to Wales.\n"I\'ve always felt - and this is with my rugby hat on now; this is not region or WRU - I\'d rather spend that money on keeping players in Wales," said Davies.\nThe WRU provides £2m to the fund and £1.3m comes from the regions.\nFormer Wales and British and Irish Lions fly-half Davies became WRU chairman on Tuesday 21 October, succeeding deposed David Pickering following governing body elections.\nHe is now serving a notice period to leave his role as Newport Gwent Dragons chief executive after being voted on to the WRU board in September.\nDavies was among the leading figures among Dragons, Ospreys, Scarlets and Cardiff Blues officials who were embroiled in a protracted dispute with the WRU that ended in a £60m deal in August this year.\nIn the wake of that deal being done, Davies said the £3.3m should be spent on ensuring current Wales-based stars remain there.\nIn recent weeks, Racing Metro flanker Dan Lydiate was linked with returning to Wales.\nLikewise the Paris club\'s scrum-half Mike Phillips and centre Jamie Roberts were also touted for possible returns.\nWales coach Warren Gatland has said: "We haven\'t instigated contact with the players.\n"But we are aware that one or two of them are keen to return to Wales sooner rather than later."\nSpeaking to Scrum V on BBC Radio Wales, Davies re-iterated his stance, saying keeping players such as Scarlets full-back Liam Williams and Ospreys flanker Justin Tipuric in Wales should take precedence.\n"It\'s obviously a limited amount of money [available]. The union are contributing 60% of that contract and the regions are putting £1.3m in.\n"So it\'s a total pot of just over £3m and if you look at the sorts of salaries that the... guys... have been tempted to go overseas for [are] significant amounts of money.\n"So if we were to bring the players back, we\'d probably get five or six players.\n"And I\'ve always felt - and this is with my rugby hat on now; this is not region or WRU - I\'d rather spend that money on keeping players in Wales.\n"There are players coming out of contract, perhaps in the next year or so… you\'re looking at your Liam Williams\' of the world; Justin Tipuric for example - we need to keep these guys in Wales.\n"We actually want them there. They are the ones who are going to impress the young kids, for example.\n"They are the sort of heroes that our young kids want to emulate.\n"So I would start off [by saying] with the limited pot of money, we have to retain players in Wales.\n"Now, if that can be done and there\'s some spare monies available at the end, yes, let\'s look to bring players back.\n"But it\'s a cruel world, isn\'t it?\n"It\'s fine to take the buck and go, but great if you can get them back as well, provided there\'s enough money."\nBritish and Irish Lions centre Roberts has insisted he will see out his Racing Metro contract.\nHe and Phillips also earlier dismissed the idea of leaving Paris.\nRoberts also admitted being hurt by comments in French Newspaper L\'Equipe attributed to Racing Coach Laurent Labit questioning their effectiveness.\nCentre Roberts and flanker Lydiate joined Racing ahead of the 2013-14 season while scrum-half Phillips moved there in December 2013 after being dismissed for disciplinary reasons by former club Bayonne.',
# 'id': '29750031',
# 'summary': 'New Welsh Rugby Union chairman Gareth Davies believes a joint £3.3m WRU-regions fund should be used to retain home-based talent such as Liam Williams, not bring back exiled stars.'}

数据预处理
from transformers import AutoTokenizer
model_checkpoint = "t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
with tokenizer.as_target_tokenizer():
print(tokenizer(["Hello, this one sentence!", "This is another sentence."]))
#{'input_ids': [[8774, 6, 48, 80, 7142, 55, 1], [100, 19, 430, 7142, 5, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]}
if model_checkpoint in ["t5-small", "t5-base", "t5-larg", "t5-3b", "t5-11b"]:
prefix = "summarize: "
else:
prefix = ""
max_input_length = 1024
max_target_length = 128
def preprocess_function(examples):
inputs = [prefix + doc for doc in examples["document"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples["summary"], max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
微调预训练模型
from transformers import AutoModelForSeq2SeqLM,
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
from transformers import Seq2SeqTrainingArguments
batch_size = 16
args = Seq2SeqTrainingArguments(
"test-summarization",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,#至多保存3个模型
num_train_epochs=1,
predict_with_generate=True,
fp16=True,
)
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
fake_preds = ["hello there", "general kenobi"]
fake_labels = ["hello there", "general kenobi"]
metric.compute(predictions=fake_preds, references=fake_labels)
#{'rouge1': AggregateScore(low=Score(precision=1.0, recall=1.0, fmeasure=1.0), mid=Score(precision=1.0, recall=1.0, fmeasure=1.0), high=Score(precision=1.0, recall=1.0, fmeasure=1.0)),
# 'rouge2': AggregateScore(low=Score(precision=1.0, recall=1.0, fmeasure=1.0), mid=Score(precision=1.0, recall=1.0, fmeasure=1.0), high=Score(precision=1.0, recall=1.0, fmeasure=1.0)),
# 'rougeL': AggregateScore(low=Score(precision=1.0, recall=1.0, fmeasure=1.0), mid=Score(precision=1.0, recall=1.0, fmeasure=1.0), high=Score(precision=1.0, recall=1.0, fmeasure=1.0)),
# 'rougeLsum': AggregateScore(low=Score(precision=1.0, recall=1.0, fmeasure=1.0), mid=Score(precision=1.0, recall=1.0, fmeasure=1.0), high=Score(precision=1.0, recall=1.0, fmeasure=1.0))}
import nltk
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Rouge expects a newline after each sentence
decoded_preds = ["\n".join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds] #按句子分割后换行符拼接
decoded_labels = ["\n".join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
# Extract a few results
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
# Add mean generated length
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
result["gen_len"] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
生成任务-语言模型
任务介绍
介绍两类语言模型建模任务
-
因果语言模型(Causal language modeling,CLM):模型需要预测句子中的下一位置处的字符(类似BERT类模型的decoder和GPT,从左往右输入字符)。模型会使用矩阵对角线attention mask机制防止模型提前看到答案。例如,当模型试图预测句子中的i+1位置处的字符时,这个掩码将阻止它访问位置之后的字符。
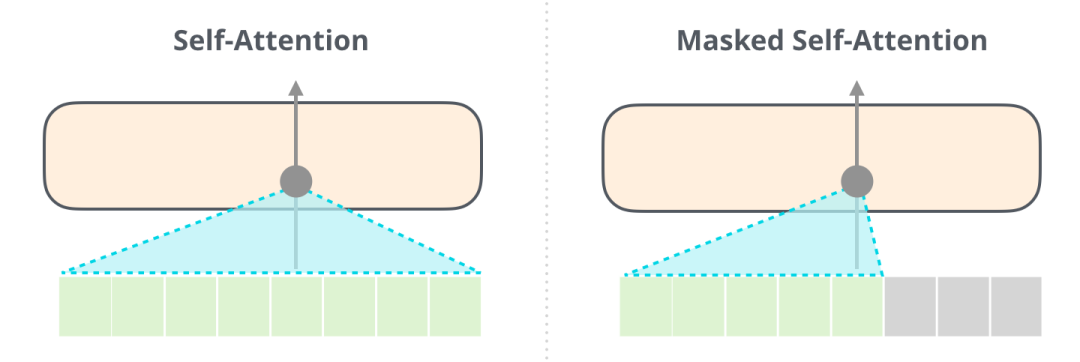
-
掩码语言建模(Masked language modeling,MLM):模型需要恢复输入中被”MASK”掉的一些字符(BERT类模型的预训练任务,只用transformer的encoder部分)。模型可以看到整个句子,因此模型可以根据“[MASK]”标记之前和之后的字符来预测该位置被“[MASK]”之前的字符。
数据加载
数据集介绍
我们使用Wikitext 2数据集,其中包括了从Wikipedia上经过验证的Good和Featured文章集中提取的超过1亿个token的集合。
加载数据
pip install datasets transformers sacrebleu sentencepiece
#transformers==4.9.2
#datasets==1.11.0
from datasets import load_dataset
datasets = load_dataset('wikitext', 'wikitext-2-raw-v1')

CLM
数据预处理
from transformers import AutoTokenizer
model_checkpoint = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
对于因果语言模型(CLM),我们首先获取到数据集中的所有文本并分词,之后将它们连接起来。最后,在特定序列长度的例子中拆分它们,将各个拆分部分作为模型输入。
通过这种方式,模型将接收如下的连续文本块,[BOS_TOKEN]用于分割拼接了来自不同内容的文本。
输入类型1:文本1
输入类型2:文本1结尾 [BOS_TOKEN] 文本2开头
def tokenize_function(examples):
return tokenizer(examples["text"])
使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将函数tokenize_function应用到(map)所有样本上。使用batch=True和4个进程来加速预处理。这是为了充分利用前面加载fast_tokenizer的优势,它将使用多线程并发地处理批中的文本。之后我们并不需要text列,所以将其舍弃(remove_columns)。
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"])
我们需要将所有文本连接在一起,然后将结果分割成特定block_size的小块。block_size设置为预训练模型时所使用的最大长度。
编写预处理函数来对文本进行组合和拆分:
# block_size = tokenizer.model_max_length
block_size = 128
def group_texts(examples):
# 拼接所有文本
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# 我们将余数对应的部分去掉。但如果模型支持的话,可以添加padding,您可以根据需要定制此部件。
total_length = (total_length // block_size) * block_size
# 通过max_len进行分割。
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
注意:因为我们做的是因果语言模型,其预测label就是其输入的input_id,所以我们复制了标签的输入。
我们将再次使用map方法,batched=True表示允许通过返回不同数量的样本来改变数据集中的样本数量,这样可以从一批示例中创建新的示例。
注意,在默认情况下,map方法将发送一批1,000个示例,由预处理函数处理。可以通过传递不同batch_size来调整。也可以使用num_proc来加速预处理。
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
num_proc=4,
)
检查一下数据集是否发生了变化:
tokenizer.decode(lm_datasets["train"][1]["input_ids"])
微调预训练模型
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_checkpoint)
设定训练参数
为了能够得到一个Trainer训练工具,我们还需要训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
from transformers import TrainingArguments
batch_size = 16
training_args = TrainingArguments(
"test-clm",
evaluation_strategy = "epoch",
learning_rate=2e-5,
weight_decay=0.01,
)
完成该任务不需要特别定义评估指标处理函数,模型将直接计算困惑度perplexity作为评估指标。
开始训练
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"][:1000],
eval_dataset=lm_datasets["validation"][:1000],
)
trainer.train()
评估模型
import math
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
MLM
from transformers import AutoTokenizer
model_checkpoint = "distilroberta-base"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
对于掩码语言模型(MLM),我们首先获取到数据集中的所有文本并分词,之后将它们连接起来,接着在特定序列长度的例子中拆分它们。与因果语言模型不同的是,我们在拆分后还需要随机”MASK”一些字符(使用”[MASK]”进行替换)以及调整标签为只包含在”[MASK]”位置处的标签(因为我们不需要预测没有被”MASK”的字符),最后将各个经掩码的拆分部分作为模型输入。
def tokenize_function(examples):
return tokenizer(examples["text"])
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"])
# block_size = tokenizer.model_max_length
block_size = 128
def group_texts(examples):
# 拼接所有文本
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# 我们将余数对应的部分去掉。但如果模型支持的话,可以添加padding,您可以根据需要定制此部件。
total_length = (total_length // block_size) * block_size
# 通过max_len进行分割。
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
注意:我们这里仍然复制了标签的输入作为label,因为掩码语言模型的本质还是预测原文,而掩码在data collator中通过添加特别的参数进行处理,下文会着重说明。
我们将再次使用map方法,batched=True表示允许通过返回不同数量的样本来改变数据集中的样本数量,这样可以从一批示例中创建新的示例。
注意,在默认情况下,map方法将发送一批1,000个示例,由预处理函数处理。可以通过传递不同batch_size来调整。也可以使用num_proc来加速预处理
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
num_proc=4,
)
微调预训练模型
为了能够得到一个Trainer训练工具,我们还需要训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
from transformers import TrainingArguments
batch_size = 16
training_args = TrainingArguments(
"test-clm",
evaluation_strategy = "epoch",
learning_rate=2e-5,
weight_decay=0.01,
)
数据收集器data collator
data_collator是一个函数,负责获取样本并将它们批处理成张量。data_collator负责获取样本并将它们批处理成张量。掩码语言模型任务需要使用一个特殊的data_collator,用于随机”MASK”句子中的token。
注意:我们可以将MASK作为预处理步骤(tokenizer)进行处理,但tokenizer在每个阶段字符总是以相同的方式被掩盖。而通过在data_collator中执行这一步,可以确保每次生成数据时都以新的方式完成掩码(随机)。
为了实现随机mask,Transformers为掩码语言模型提供了一个特殊的DataCollatorForLanguageModeling。可以通过mlm_probability调整掩码的概率:
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
开始训练
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"][:1000],
eval_dataset=lm_datasets["validation"][:100],
data_collator=data_collator,
)
trainer.train()
import math
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")