
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
生成语言模型
本文仅为自己梳理用,大部分参考 轩明月 on December 21, 2020的博客
总结摘要,理清脉络
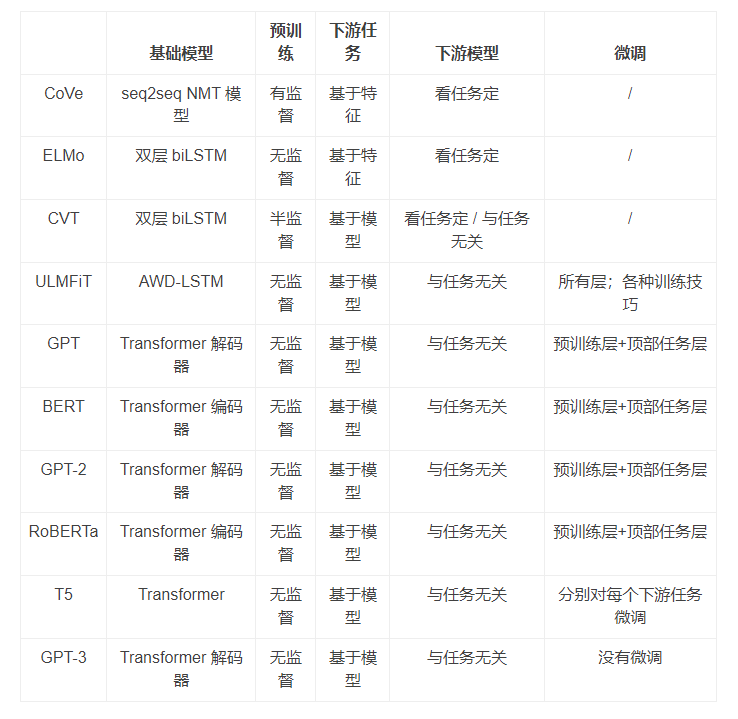
CoVe 2017
语境词向量(Contextual Word Vectors, Cove, McCann等人 2017) 是一类用编码器做词嵌入的方法,编码器就是基于注意力的 seq-to-seq 机器翻译模型里用的那种。不同于传统的词嵌入方法,CoVe 的词表示是关于整个输入序列的函数。
Seq2Seq
Seq2Seq大致的意思是将一个序列信号,通过编码器和解码器生成一个新的序列信号,通常用于机器翻译、语音识别、自动对话等任务,在经典的实现中,编码器和解码器各由一个循环神经网络构成,一般选择RNN/LSTM模型,在训练中这两个网络是同时训练的。
将Seq2Seq模型按照循环神经网络表示入下:
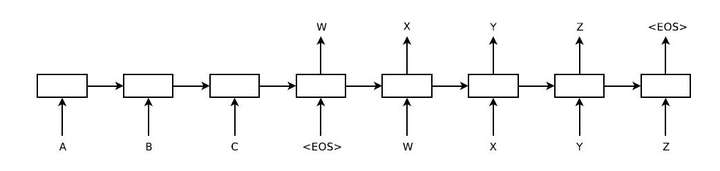
上图是将一个翻译过程展开的图,其中A,B,C表示为输入的句子,W,X,Y,Z为翻译出来的句子,其中前四个神经元是ENCODER,后四个为DECODER,并且在输入的时序末尾会加一个“EOS”表示这个时序已经输入完成,可以进行解码工作了,同样的解码部分最后也会输出“EOS”表示解码已经完成。
假设模型是用于机器翻译的,那么整个模型的目标函数是对输入词向量 $(x_1,x_2,…,x_T)$做处理输出可能性最大的翻译$(y_1,y_2,…,y_{T’})$,因为输入和输入的长度不同,所以用不同长度$T$和$T’$表示。

训练Seq2Seq
- ENCODER和DECODER两部分用不同的RNN/LSTM,使模型做到同步训练多个语言对,并且效果更好
- 实验证明深层的LSTM的训练结果好于浅层的,一般选择4层的RNN/LSTM训练
- 对要输入的词向量倒序输入,比如$A,B,C=>W,X,Y,Z$,经过倒序处理后会是$C,B,A=>W,X,Y,Z$,这样做LSTM可以更好的学习到长距离的依赖关系,对提升模型的准确率很有价值。
| DECODER的解码工作就是将概率最大翻译序列找出来,即取训练后$p(T | S)$概率最大的T序列,如何选择概率最大的T序列,最基础的做法是使用贪心算法,选取一种度量标准后,每次都在当前状态下选择最佳的一个结果,直到结束,但这种方法大概率会得到一个局部最优的序列,即后面的序列对整个序列影响很小,找出的序列并不是最佳的。这里我们使用beam search算法进行解码工作。 |
beam search
也被称为集束搜索,该算法会根据概率大小选择当前beam size个单词做为最佳选项,然后将这些词作为输入,输入到DECODER中,产生下一个时序的单词,其中每个上一时刻的候选词都会产生beam search个候选词选,再从中选择出来概率最大的beam size个组合,接着扩展排序,选择前beam size个进行保存,循环迭代,直到结束时选择最好的一个作为解码的结果。如果beam search为1就会退化为贪心算法了。
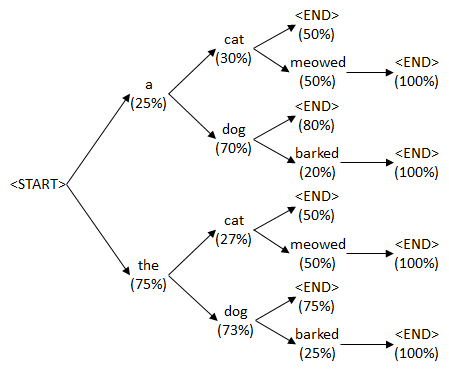
比如上面的例子,例子中beam size为2,“EOS”作为编码器最后一个输出后,解码已经解码的第一个词有两个候选项 a 和 the,然后将 a 和 the输入到解码器中,得到一系列候选序列a cat、a dog、the cat、the dog等。最后从候选序列中选择最优的两个序列 the cat和the dog再输入到解码器中,得到候选序列,选择最优的两个,直到遇到”EOS”结束。再从候选序列中找出最佳序列。在实际任务中,一般beam size在8到12之间
NMT 概述
这里的神经机翻译(NMT)模型由一个标准的双层双向 LSTM 编码器,和一个额外的基于注意力的双层单向 LSTM 解码器构成。模型预先在英语-德语翻译任务上进行训练。编码器学习并优化英文单词的 embedding 向量,好将其译为德文。直觉上编码器能在将词转为其他语言形式学到高维语义和句法特征,编码器输出的情景化词嵌入可供各种下游语言任务使用。
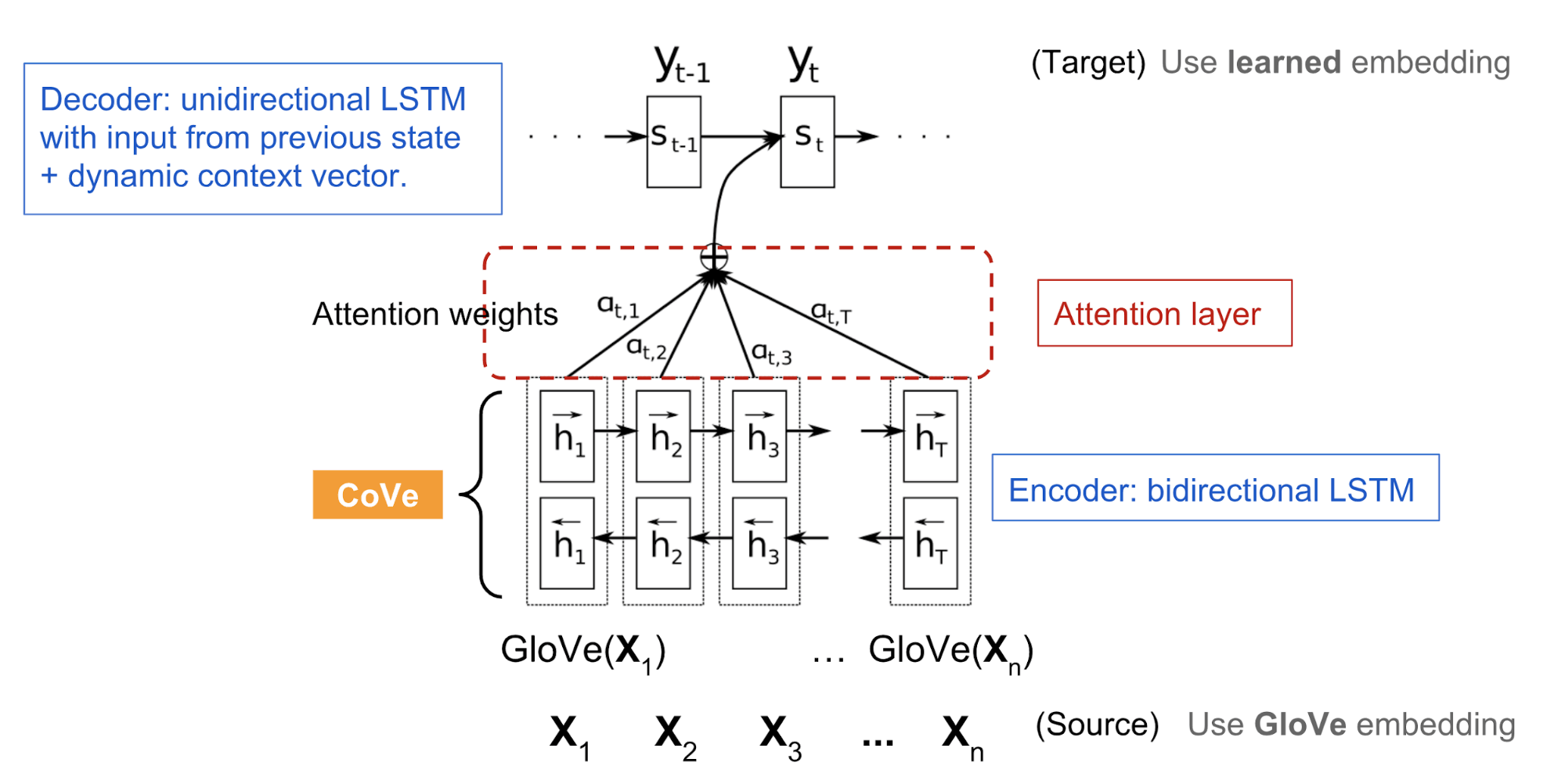

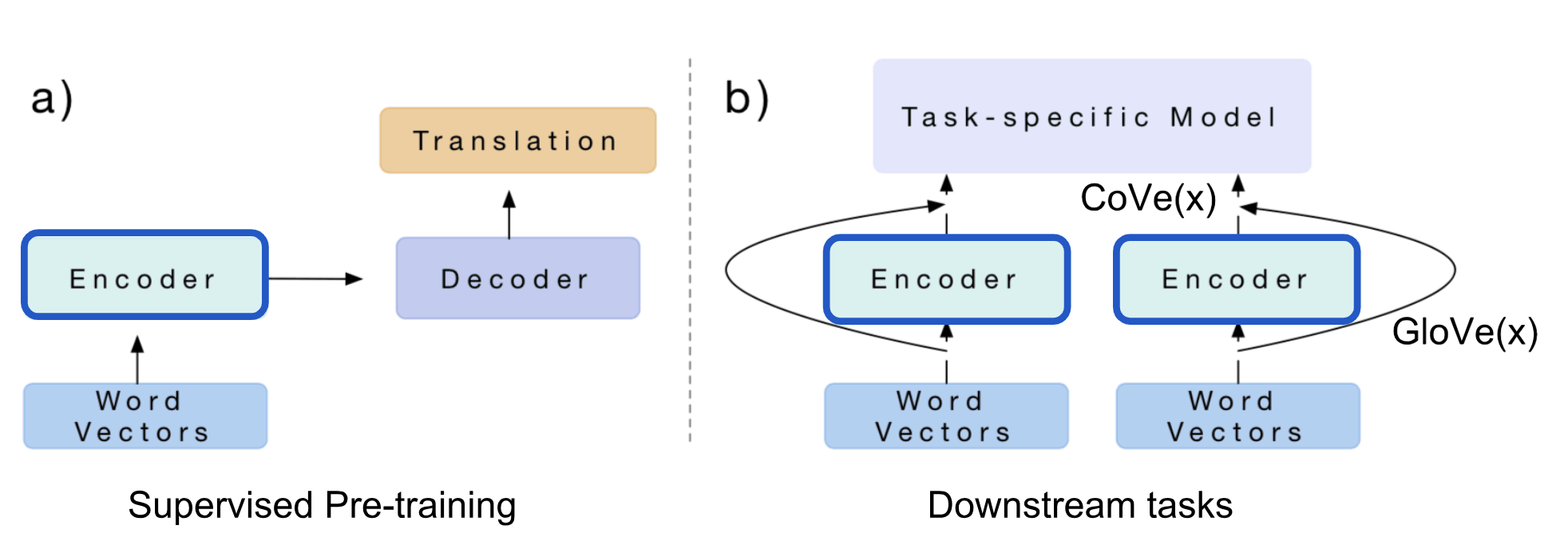
下游任务使用CoVe
NMT 编码器的隐态在其他语言任务中称为环境向量(context vector): \(CoVe(x)=biLSTM(GloVe(x))\) 论文将 GloVe 和 CoVe 串联用于问答和分类任务。GloVe 从全局字词共现比率中学习,所以没有句子语境,而 CoVe 是通过处理文本序列得到的,能够捕捉情境信息。 \(v=[GloVe(x);CoVe(x)]\) 对特定下游任务,我们先生成输入字词的 GloVe+CoVe 的串联向量,然后将其作为附加特征喂给特定任务模型。
CoVe 的局限性很明显
- 预训练受限于有监督翻译任务能得到哪些数据集
- CoVe 对最终效果的贡献受制于任务模型
下面看到ELMo通过无监督预训练克服了局限数据集 OpenAI GPT和BERT进一步通过预测训练+对不同下游任务采用生成模型架构将两个局限都解决了
ELMo
语言模型嵌入(Embeddings from Language Model,ELMo,Peters 等人 2018)通过 无监督 的方式预训练一个语言模型来获取情境化字词表示。
双向语言模型
双向语言模型(bidirectional Language Model,biLM) 是 ELMo 的基础,当输入为 n 个标识组成的序列时,(x1,…,xn),语言模型会学着根据历史预测下个标识的概率。 前向传递期间,历史由目标标识之前的字词构成, \(p(x_1,...,x_n) = \prod_{i=1}^np(x_i|x_1,...,x_{i-1})\) 反向传递时,历史则由目标标识之后的字词构成 \(p(x_1,...,x_n)=\prod_{i=1}^np(x_i|x_{i+1},...,x_n)\)
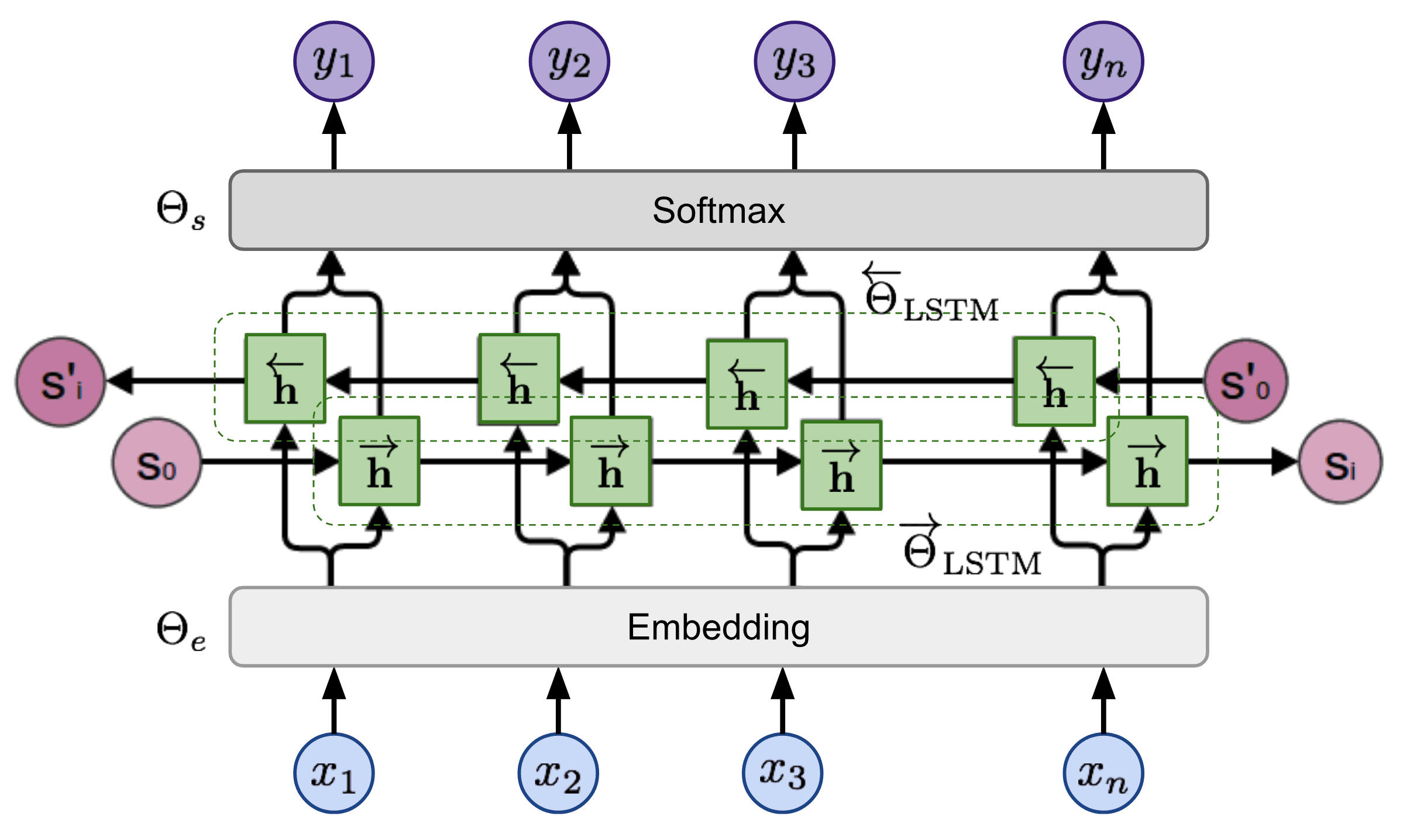
两个方向的预测由多层 LSTM 负责建模,输入表示$x_i在l=1,…,L$层的隐态为$h^{->}{i,l}和h^{<-}{i,l}$经过softmax归一化,用最后一层的隐态$h_{i,L}=[h^{->}{i,l};h^{<-}{i,l}]$ 获取标识概率,嵌入层和softmax层共享,参数分别为$\Theta_e,\Theta_s$. 模型要使两个方向的负对数似然概率最小化(= 正确词的对数似然概率最大化):
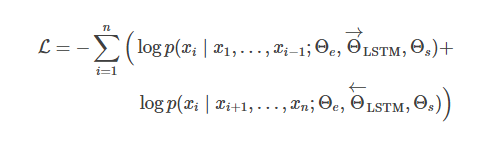
ELMo表示
在L层的biLM基础上,ELMo针对任务学习了一种线性组合方式,跨层将所有隐态堆叠起来,标识$x_i$的隐太表示有$2L+1$个向量: \(R_i=\{ h_{i,l}|l=0,...,L\}\) 其中$h_0,l$是嵌入层输出,$h_{i,l}=[h^{\rightarrow}{i,l};h^{\leftarrow}{i,l}]$每个终端任务都要学习一组线性组合权重$s^{task}$并用softmax做归一化,比例因子$\gamma^{task}$用于纠正biLM隐态分布和任务表示分布之间的偏差。 \(v_i=f(R_i;\Theta^{task})=\gamma^{task}\sum^L_{l=0}s_i^{task}h_{i,l}\)
为了评估从跨层隐态上得到了哪类信息,分别用不同 biLM 层的表示在语义和语法任务上对 ELMo 进行测试:
- 语义任务 :词义消除(word sense disambiguation)
- 语法任务 : 词性标注(part-of-speech tagging)
对比研究表明语法信息较低的层表示更好,而语义信息更高处的层领悟更深。因为不同层携带着不同类型的信息,将其堆叠起来会有所帮助
下游任务使用ELMo
和 CoVe 助力不同下游任务的方式类似,ELMo 嵌入向量常见于输入或任务模型的底层。此外,对某些任务(即 SNLI,SQuAD,不包括 SRL)在输出层加上他们同样有所助益。
对那些只有少量有监督数据的任务来说,ELMo 带来的提升是最大的。有了 ELMo,即使标签数据再少我们也能取得类似的效果。
总结:语言模型的预训练是无监督式的,而且鉴于无标注文本语料之丰富,理论上预训练规模可以尽可能的大些。但它还是得依赖特定任务模型,所以改善只是渐进式的,给每个任务找个好模型架构仍然很重要。
跨视角训练
ELMo 中无监督的预训练和指定任务的学习,是在两个独立训练阶段由两个独立模型完成的。 跨视角训练(Cross-View Training,CVT, Clark 等人, 2018) 将二者结合,组成了一个统一的半监督学习过程,辅助任务中有标注数据的监督学习和无标注数据的无监督学习都能改善 biLSTM 编码器的表示。
模型架构
模型由一个双层双向的 LSTM 编码器和一个主预测模块构成。训练时交替将标注数据和无标注数据分批喂给模型。
- 对有标注的样本,所有模型参数都通过标准监督学习进行更新。损失是标准交叉熵
- 对无标注样本,主预测模块依旧可以得到一个“柔性”目标,尽管我们并不清楚这有多准。两个辅助任务中,预测器只能看到并处理有限视角下的输入内容,比如只用单方向上的编码器隐态表示。我们希望辅助任务的输出能和初步预测目标匹配,这样就能得知输入全貌了。
这样,编码器被强制将完整的上下文知识提炼为不完整的表示。在这一阶段,biLSTM 编码器处于反向传播状态,但主预测模块是 固定 的。辅助预测和主预测间的差距就是我们要最小化的损失。
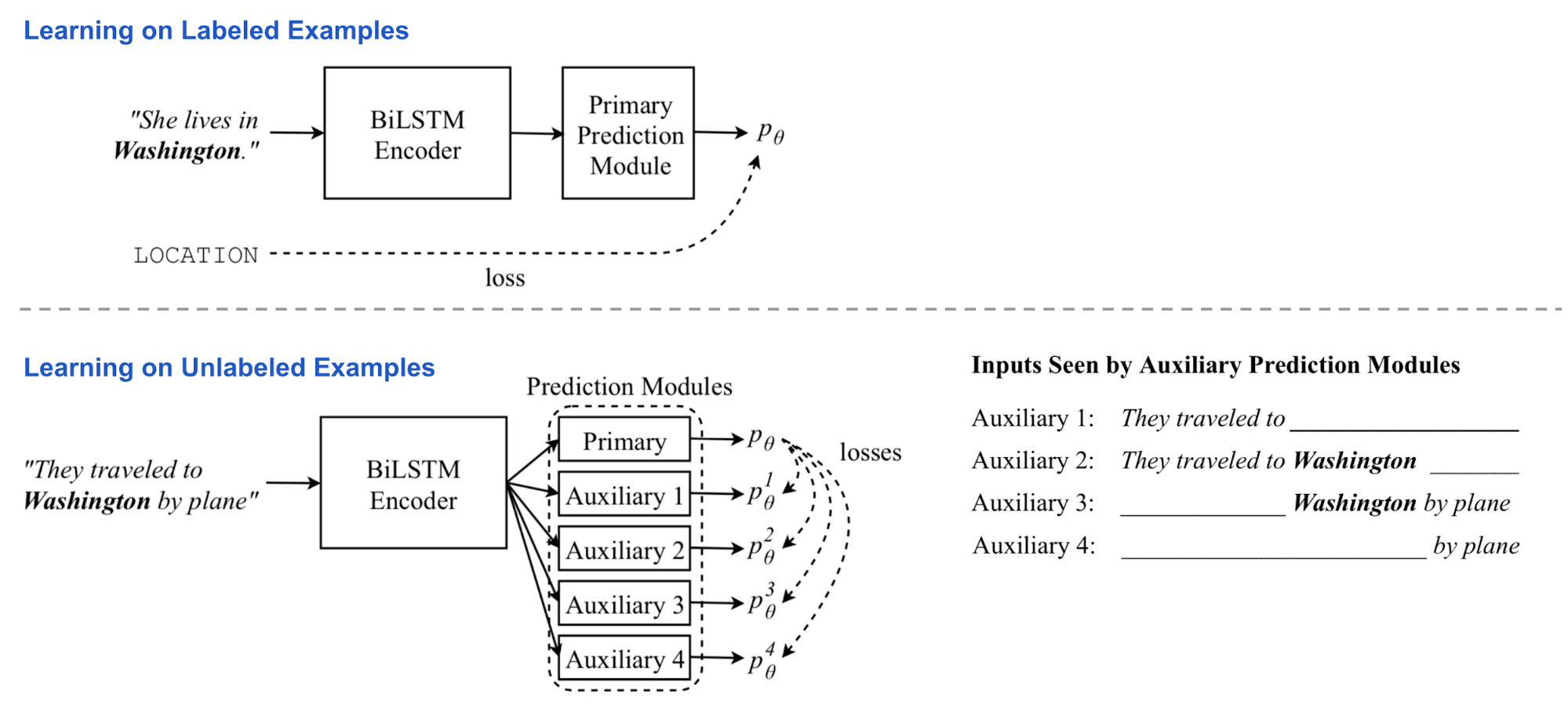
多任务学习
在同步训练多个任务的时候,CVT 给附加的任务加了几个主预测模型,它们共享同样的句子表示编码器。监督训练时,随机选择一个任务后,相应预测器参数和表示编码器得到更新。如果是无标注数据样本,联结所有任务优化编码器,力求每个任务上辅助输出和主预测间的差异最小。
多任务学习有利于增强表示的泛化能力,与此同时还收获一个很好的副产物:从无标注数据得到的全任务标注样本,他们是十分宝贵的数据标签,考虑到跨任务标签有用太稀少。
下游任务使用 CVT
在像 NER 或 POS tagging 这样的序列标注任务(给每个标识分类)中,预测器模块包括两个完整的全连接层,和给输出加上的 softmax 层,以此生成类别标签的概率分布。对每个标识$x_i$,两层对应的隐态为$h_1^i$和$h_2^i$
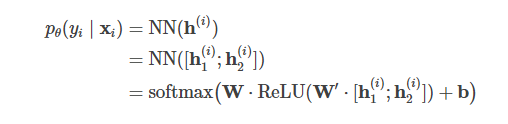
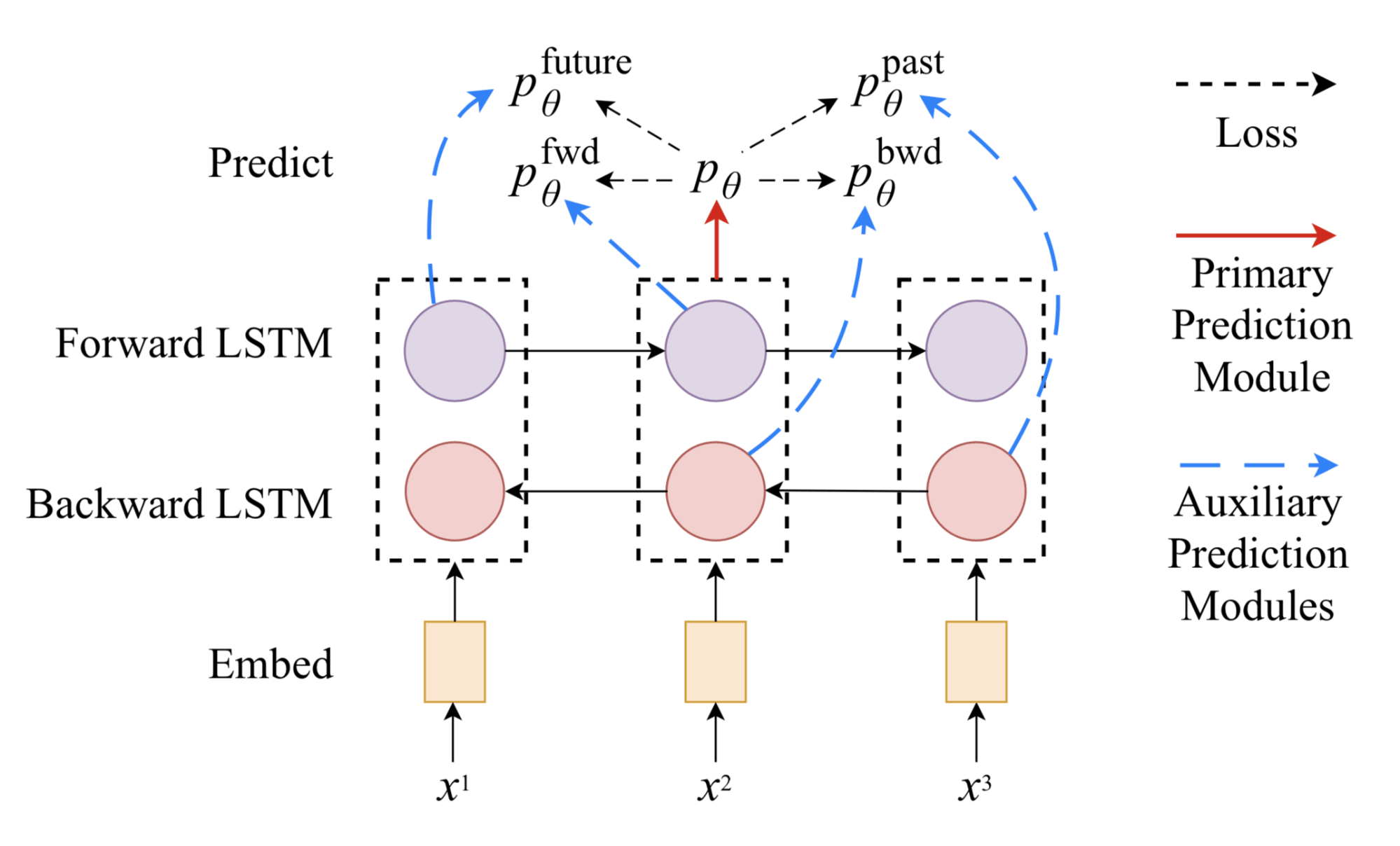
如果主预测模块有 dropout,那处理有标注数据的时候 dropout 层照常工作,但用无标注数据训练,为辅助任务生成“柔性”目标时不参与计算。
机器翻译任务中,主预测模块换成了标准的带 attention 的标准单向 LSTM 解码器。涉及两个辅助任务:
- dropout,随机使 attention 权重向量的一些值清零;
- 预测目标序列的未来词。用固定的主解码器对输入做集束搜索得到的最优预测目标序列就是辅助任务要努力逼近的主预测项了。
ULMFiT
ULMFiT 通过下面三步在下游语言分类任务上取得了良好的迁移学习效果: 1) 通用 LM 预训练:Wikipedia 语料 2) 目标任务 LM 微调:ULMFiT 提出了两个训练技术来稳定微调过程。 - 差异化微调(Discriminative fine-tuning) - 斜三角学习率(Slanted triangular learning rates,STLR) 3) 目标任务分类器微调:用两个标准前馈层强化预训练 LM,并在末端加上 softmax 归一化来预测目标标签分布。
- 连接池化(Concat pooling)
- 逐步解封(Gradual unfreezing)
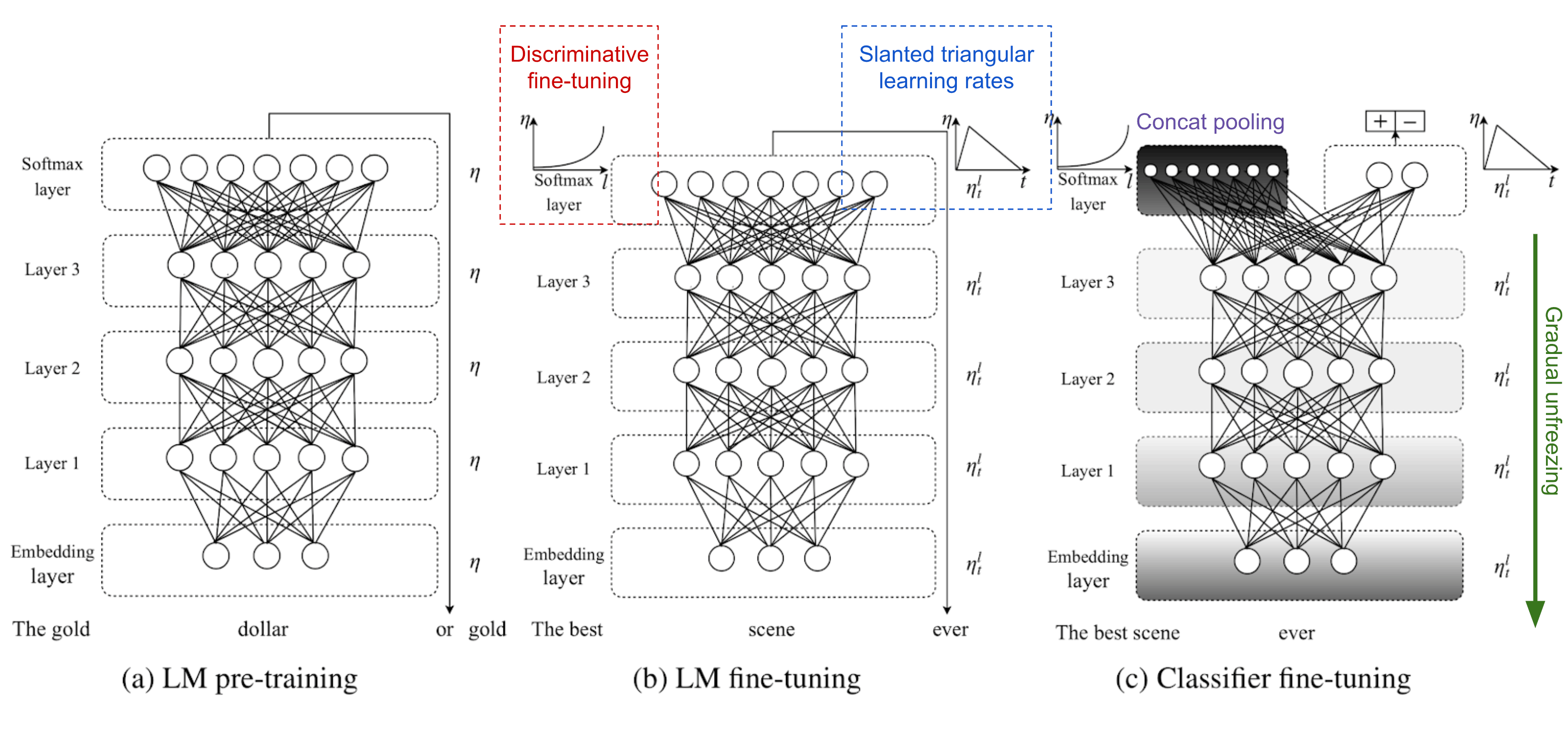
OpenAI GPT
OpenAI 的生成式预训练 Transformer(Generative Pre-training Transformer,GPT,Radford 等人, 2018) 通过在巨量文本语料上训练,极大的增加了无监督语言模型的规模。抛开相似之处,GPT 和 ELMo 主要有两点不同。
- 模型架构不同
- ELMo 是将独立训练的自左向右和自右向左的多层 LSTM 进行浅拼接
- GPT 是个多层 transformer 解码器
- 情境化嵌入在下游任务中的用法不同
- ELMo 是将 embedding 作为额外特征喂给特定任务模型
- GPT 是将相同的基准模型进行微调来解决各式任务
拿 Transformer 解码器当语言模型
模型在输入序列的 embedding 上加了多层 transformer 块进行处理。每一块内都有一个遮罩多头自注意力(multi-headed self-attention)层和一个元素级前馈(pointwise feed-forward)层。经 softmax 归一化后最终可以得到一个目标标识的分布。
![]()
字节对编码
字节对编码(Byte Pair Encoding,BPE)用于给输入序列编码。因为在译为某种新语言的时候很容易遇到少见或未知的词。直觉上稀有或未知词经常可以拆成多个子词,BPE 就不断迭代,贪婪地合并常见字符对以寻找最佳分词方式。
有监督微调
OpenAI GPT 所做的最大改进是与任务模型解耦,直接用预训练语言模型! 以分类任务为例。标注数据集中每个输入有N个表示,X=(x1,…,xn),和一个标签y,GPT先用预训练过的transformer解码器处理输入序列x,最后一个标识$x_n$,在最后一层的输出为$h_L^{(n)}$靠着仅有的训练得到的权重矩阵$W_y$模型可以预测类别标签的分布。

损失是求实际标签的负对数似然概率的最小化,此外作者发现加上 LM 损失作为辅助损失会有好处,因为:
- 训练时利于加速收敛
- 改善监督模型的泛化效果

![]()
总结:当时(2018.6)看到这样一个通用框架在大多数语言任务上取得 SOTA,让人感觉很巧妙且倍受鼓舞。一阶段,语言模型的生成式预训练过程可以从尽可能多的免费文本语料中进行学习。二阶段,用一个较小的标注数据集针对特定任务对模型进行微调,并学习一小批新参数。
GPT 的一个局限之处在于单向性——模型只会自左向右的预测上下文。
BERT
Transformer 双向编码器表示(Bidirectional Encoder Representations from Transformers,BERT,Devlin 等人, 2019) 算是 GPT 的直系后代:在免费语料上训练一个大规模语言模型,然后针对特定任务微调而不需要单独定制网络架构。 相较于 GPT,BERT 最大的区别和改善之处在于双向训练,模型会学着预测左右两边的上下文,按论文中消融研究结果所述:
预训练任务
- 任务 1:遮罩语言模型(Mask language model,MLM)15%
- 任务 2:下一句预测 许多下游任务涉及到对句子间关系的理解(QA,NLI),BERT 额外加了一个辅助任务,训练一个二分类器(binary classifier)判断一句话是不是另一句的下文:
输入嵌入
- 字段标识嵌入(WordPiece tokenization embeddings)
- 片段嵌入(segment embedding)
- 位置嵌入(position embeddings)
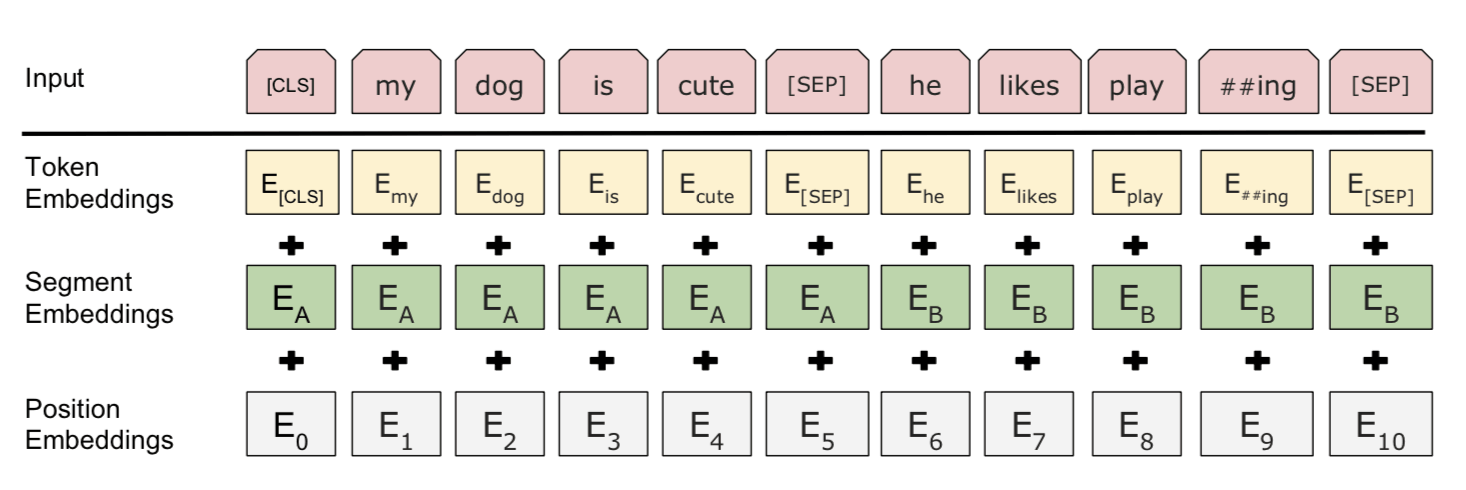 注意第一个标识必须是 [CLS]——之后下游任务预测中会用到的占位符
注意第一个标识必须是 [CLS]——之后下游任务预测中会用到的占位符
下游任务使用BERT
总体来讲微调下游任务时加上的内容很少——一两个权重矩阵,负责将 Transform 隐态转换成可解释形式。其他情况的实施细节可以看论文了解。
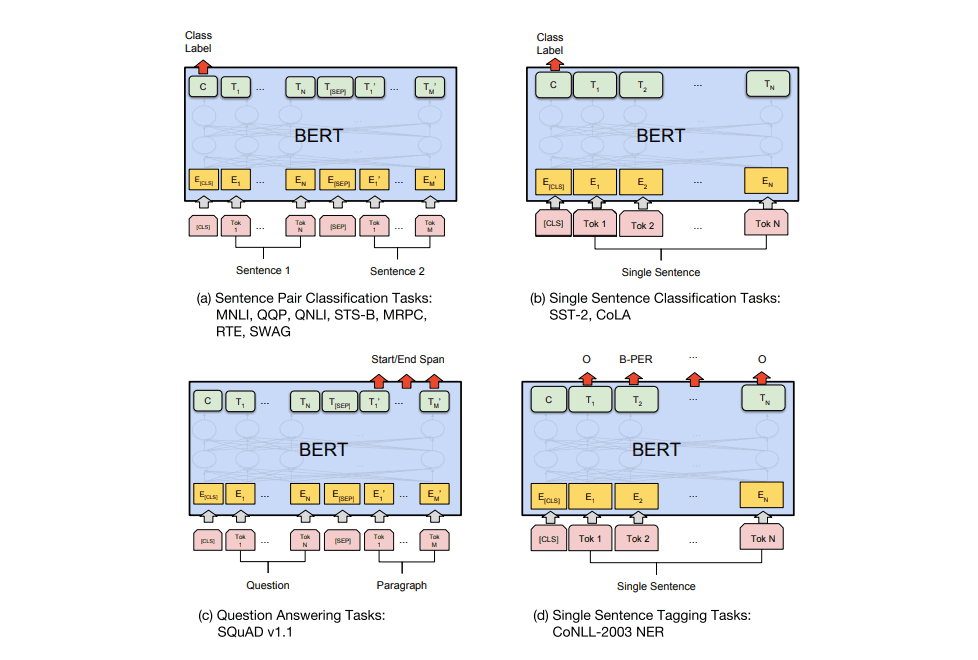

ALBERT
分解式嵌入参数化
理论上,标识嵌入应当学习的是情境独立的表示,而隐态是依赖环境的,所以将隐层大小和词表嵌入的大小分开考虑比较合理。通过分解式嵌入参数化
跨层参数共享
参数跨层共享有多种方式
- 只共享前馈部分
- 只共享注意力参数
- 共享所有参数。该方法可以大量削减参数,同时又不会太伤害性能。
句子顺序预测
有趣的是,BERT 的下一句预测(NSP)任务被证明太简单了。ALBERT 换成了句子顺序预测(sentence-order prediction,SOP)的自监督损失,
- 正样本:同文档中连续的两个部分
- 负样本:和上面一样但次序颠倒
对于 NSP 任务,当 A 和 B 的情境不同时,如果模型能检测到所谈话题它就能做出合理预测。相较而言,SOP 更难一些,因为这要求模型充分理解片段间的一致性和顺序关系。
OpenAI GPT-2
零尝试迁移
GPT-2 的预训练就纯是语言建模。所有下游语言任务都被规制成对条件概率的预测,不存在对任务的微调。

RoBERTa
- 用更大的 batch size 进行更多步的训练
- 删掉下一句预测任务
- 训练数据格式上用更长的序列。论文指出用单独的句子作输入会伤害下游性能,应该连续采样多句构建更长的片段
- 动态调整遮罩模式。原 BERT 就在预训练时用了一次遮罩,导致训练时都是一个静态罩子。RoBERTa 在 40 轮训练中用了 10 种不同的遮罩方式。
T5
文本到文本迁移 Transformer(Text-to-Text Transfer Transformer,T5,Colin 等人, 2020) 是按原 Transformer 架构实现的编码器-解码器语言模型:标识→ embedding →编码器 →解码器 →输出。T5 采用“全能自然语言”框架(McCann 等人, 2018),许多常见 NLP 任务被转换成针对上下文的问答形式。相较于显式的 QA 格式,T5 用较短的任务前缀区分任务意图,并分别对每个任务做了模型微调。文本到文本架构用同样的模型解决不同的任务,极大简化了迁移学习的评估过程。
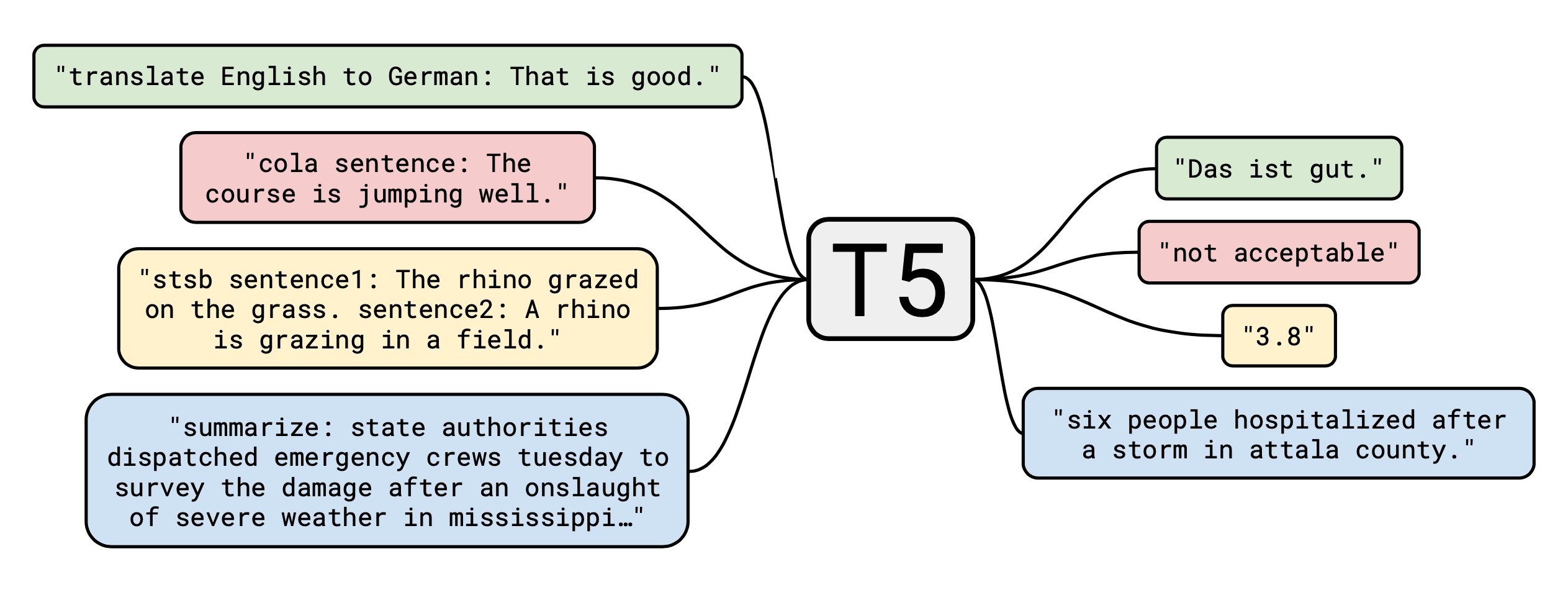
GPT-3
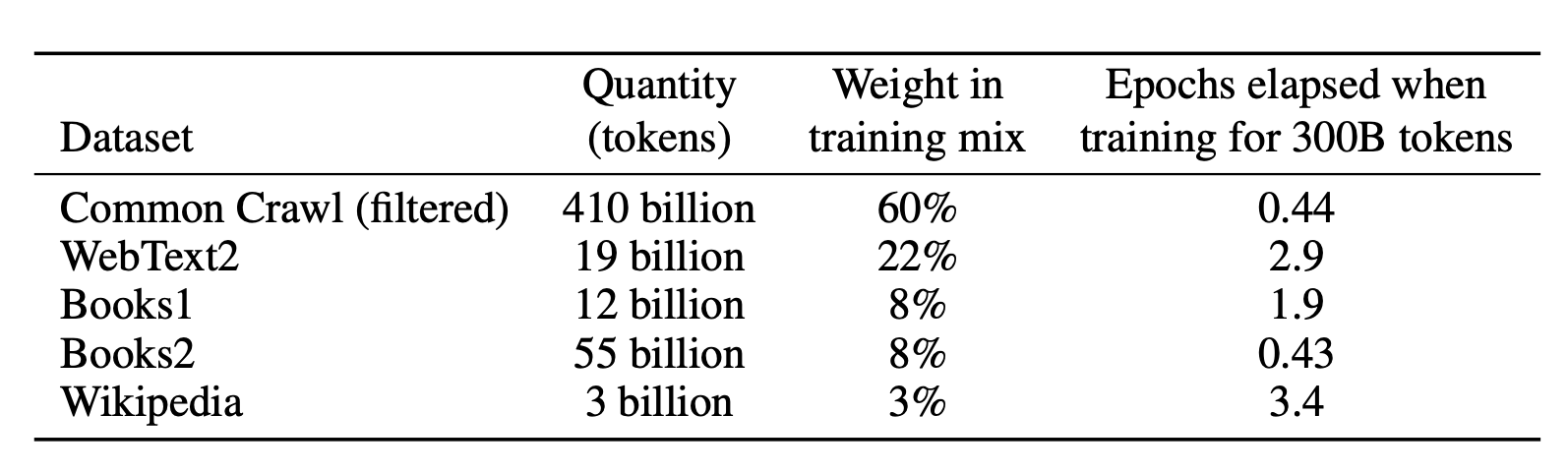
GPT-3(Brown 等,2020)和 GPT-2 架构相同但有 175B 个参数,比 GPT-2(1.5B) 大 10 多倍。此外,GPT-3 使用了稠密模式和局部带状模式交替的稀疏注意力,和稀疏 transformer 里的一样。为了把这么大的模型塞到 GPU 集群里,GPT-3 采用了沿深度和宽度方向的分区训练方式。训练数据是 Common Crawl 的过滤板,还额外混合了少数高品质数据集。为了防止下游任务出现在训练数据里造成污染,作者试着从训练集里删掉了所有基准数据集间的重叠部分。不幸的是因为有 bug 过滤过程并不完美
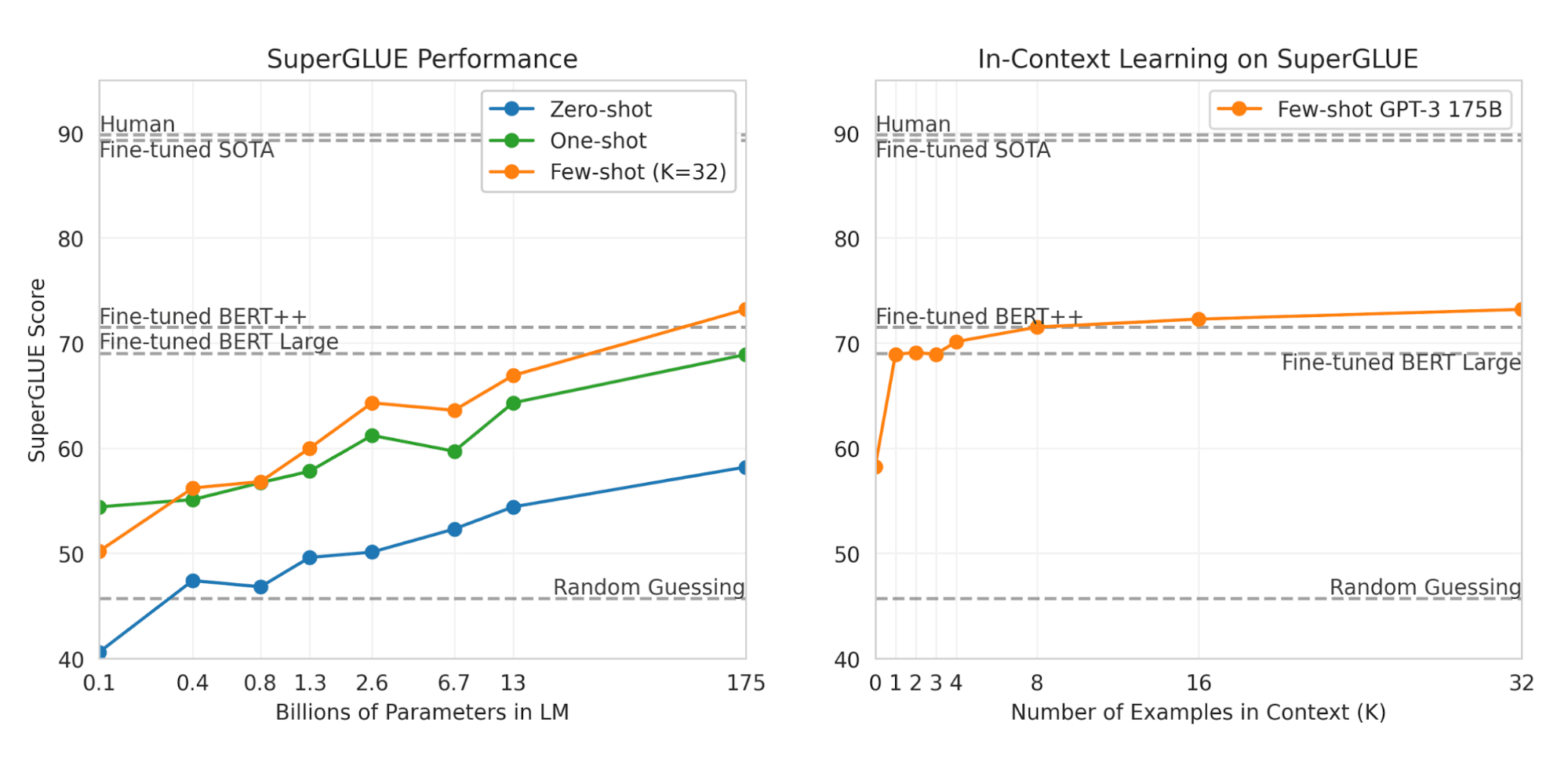
对于所有下游任务的评估,GPT-3 只是在少样本环境下做了测试,没用任何基于梯度的微调,这里的少数样本算是给了部分提示。相比于微调过的 BERT 模型,GPT-3 在很多 NLP 数据集上取得了亮眼表现。
总结
指标:复杂度
复杂度通常作为一个固有评估指标,衡量给定情境下语言模型对实际分布的学习效果。
离散概率分布$p$ 的复杂度被定义为熵的乘方: \(2^{H(p)}=2^{-\sum_xp(x)log_2p(x)}\) 给定N个词构成的序列,$s=(W_1,…,w_N)$,简单假设每个词的频率相同,都是1/N,则熵的形式如下: \(H(s)=-\sum^N_{i=1}P(w_i)log_2p(w_i)=-\sum^N_{i=1}1/N log_2p(w_i)\)
于是句子的复杂度就变为 \(2^{H(s)}=2^{-1/N\sum^N_{i=1}log_2p(w_i)}=(p(w_1)...p(w_N))^{-1/N}\)
语言模型够好,做预测给的概率越高,因此复杂度月底越好。
常见任务和数据集
问答
- SQuAD (Stanford Question Answering Dataset):阅读理解数据集
- RACE (ReAding Comprehension from Examinations):超大规模阅读理解数据集
常识推理
- Story Cloze Test:一个常识推理框架,考察故事理解和生成能力
- SWAG (Situations With Adversarial Generations):多项选择
自然语言推理(Natural Language Inference,NLI):也叫文本推演(Text Entailment)
- RTE (Recognizing Textual Entailment)
- SNLI (Stanford Natural Language Inference)
- MNLI (Multi-Genre NLI)
- QNLI (Question NLI)
- SciTail
命名实体识别(Named Entity Recognition,NER)
- CoNLL 2003 NER task
- OntoNotes 5.0
- Reuters Corpus
- Fine-Grained NER (FGN)
情感分析
- SST (Stanford Sentiment Treebank)
- IMDb:大规模影评数据集
语义成分标注(Semantic Role Labeling,SRL)
- CoNLL-2004 & CoNLL-2005
句子相似度
- MRPC (MicRosoft Paraphrase Corpus)
- QQP (Quora Question Pairs)
- STS Benchmark: Semantic Textual Similarity
句子接受度
- CoLA (Corpus of Linguistic Acceptability):
文本分块:
- CoNLL-2000
词性标注(Part-of-Speech [POS] Tagging):给每个标识打上词性成分,比如名词,动词,形容词等。
机器翻译:
- WMT 2015 English-Czech data (Large)
- WMT 2014 English-German data (Medium)
- IWSLT 2015 English-Vietnamese data (Small)
共指消解:对指代相同潜在实体的部分聚类
- CoNLL-2012
远程依赖
- LAMBADA (LAnguage Modeling Broadened to Account for Discourse Aspects):
- Children’s Book Test:
多任务基准
- GLUE 多任务基准
- decaNLP 基准
无监督预训练数据集
- Books corpus:超 7000 本不同的未出版图书,类型覆盖冒险,幻想,浪漫等
- 1B Word Language Model Benchmark
- 英文维基百科: 大约 25 亿个词