
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
DNN
\(h_t=\sigma(x_t*w_{xt}+b)\)
CNN
用全连接神经网络处理大尺寸图像具有三个明显的缺点:
1) 首先将图像展开为向量会丢失空间信息;
2) 其次参数过多效率低下,训练困难;
3) 同时大量的参数也很快会导致网络过拟合。
而使用卷积神经网络可以很好地解决上面的三个问题。
卷积神经网络的各层中的神经元是3维排列
- 宽度
- 高度
- 深度(激活数据体的第三个维度) 网络深度指的是网络层数
eg:
使用CIFAR-10中的图像是作为卷积神经网络的输 入
- 输入数据体(32x32x3) 我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式
- 输出维度1x1x10
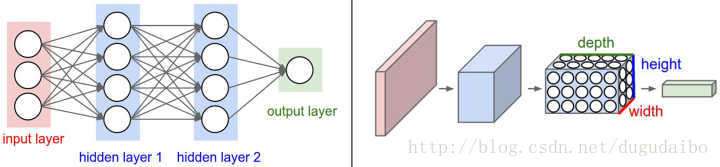
因为在卷积神经网络结构的最后部分将会把全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的
层构成
- 输入层
- 卷积层
- ReLU层(通常向上合并一起)
- 池化层
- 全连接层
卷积层
作用
- 滤波器/卷积(深度和输入数据一致)
- 看作神经元的一个输出
- 降低参数的数量
感受野
神经元与输入数据的局部区域连接,该连接空间的大小叫做神经元的感受野
- 尺寸(滤波器的空间尺寸)
- 深度方向,连接大小总是和输入量的深度相等
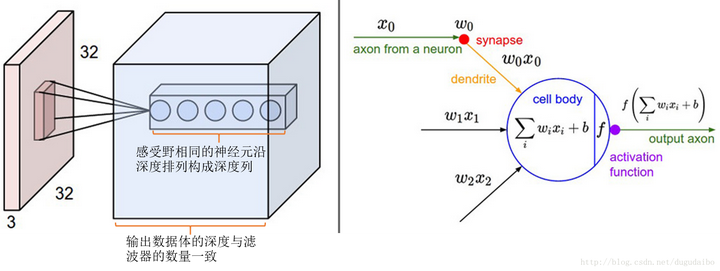
神经元的空间排列
输出数据体控制参数
- 深度(depth)
- 步长 (stride)
- 零填充 (zero-padding)
权值共享
在卷积层中权值共享是用来控制参数的数量。 在反向传播的时候,都要计算每个神经元对它的权重的梯度,但是需要把同一个深度切片上的所有神经元对权重的梯度累加,这样就得到了对共享权重的梯度。这样,每个切片只更新一个权重集。这样做的原因可以通过下面这张图进行解释 不同深度的神经元不会公用相同的权重,所以只能更新一个权重集
滤波器(filter)(或卷积核(kernel))
池化层
通常在连续的卷积层之间会周期性地插入一个池化层。它的作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合
pooling
- 输入数据体 $W_1·H_1·D_1$
- 空间大小$FF$
- 步长$SS$
- 输出数据体$W_2·H_2·D_2$
最大池化层通常只有两种形式:一种是F=3,S=2F=3,S=2,也叫重叠汇聚(overlapping pooling),另一个更常用的是F=2,S=2F=2,S=2。对更大感受野进行池化需要的池化尺寸也更大,而且往往对网络有破坏性。
- 普通池化(General Pooling)
- 平均池化(average pooling)
- L-2范式池化(L2-norm pooling)
- 反向传播
- 不使用汇聚层
- VAEs:variational autoencoders
- GANs:generative adversarial networks
归一化层
在卷积神经网络的结构中,提出了很多不同类型的归一化层,有时候是为了实现在生物大脑中观测到的抑制机制。但是这些层渐渐都不再流行,因为实践证明它们的效果即使存在,也是极其有限的。
全连接层
这个常规神经网络中一样,它们的激活可以先用矩阵乘法,再加上偏差。
有名结构体
- LeNet
- AlexNet
- ZF Net
- GoogLeNet
- VGGNet
- ResNet
RNN
结构
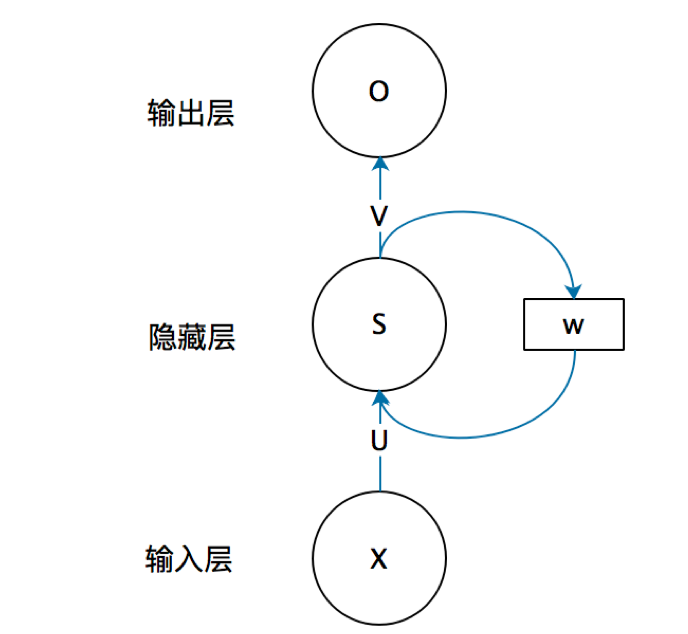
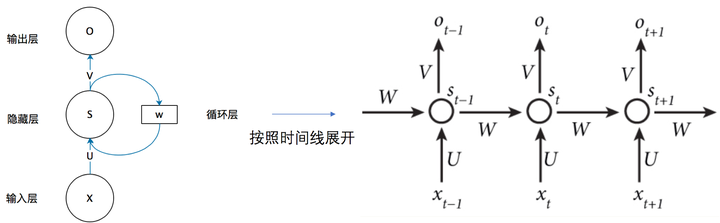
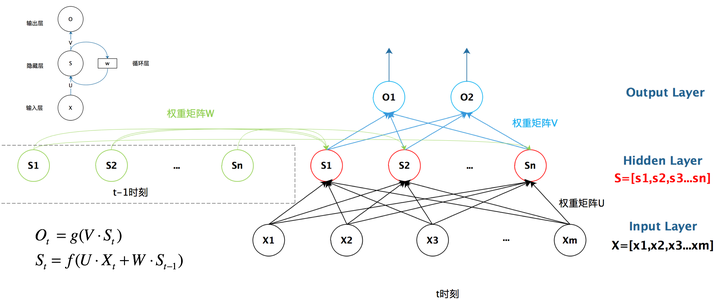 循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
Long Term Dependencies
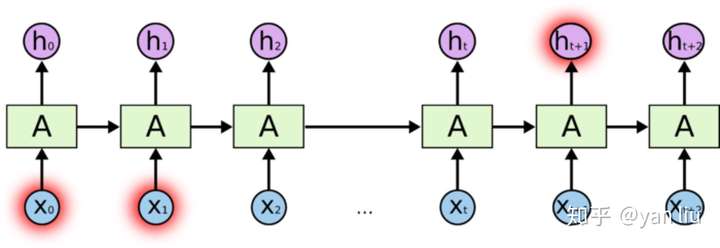
长期依赖产生的原因是当神经网络的节点经过许多阶段的计算后,之前比较长的时间片的特征已经被覆盖
随着数据时间片的增加,RNN丧失了学习连接如此远的信息的能力(图2)。
梯度消失/爆炸
梯度消失和梯度爆炸主要存在RNN中,因为RNN中每个时间片使用相同的权值矩阵。对于一个DNN,虽然也涉及多个矩阵的相乘,但是通过精心设计权值的比例可以避免梯度消失和梯度爆炸的问题
- 处理梯度爆炸可以采用梯度截断的方法。
- 梯度消失不能简单的通过类似梯度截断的阈值式方法来解决,因为长期依赖的现象也会产生很小的梯度。
LSTM
而LSTM之所以能够解决RNN的长期依赖问题,是因为LSTM引入了门(gate)机制用于控制特征的流通和损失。对于上面的例子,LSTM可以做到在t9时刻将t2时刻的特征传过来,这样就可以非常有效的判断t9时刻使用单数还是复数了。LSTM是由一系列LSTM单元(LSTM Unit)组成,其链式结构如下图
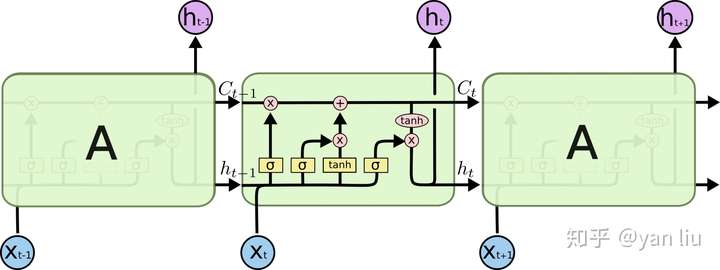
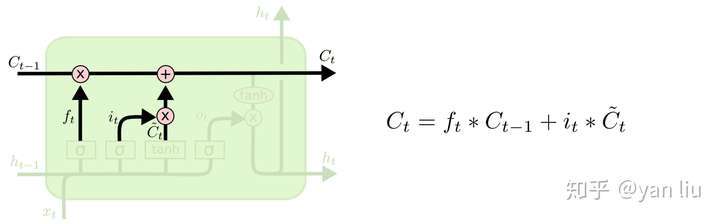
 LSTM的核心部分是在图4中最上边类似于传送带的部分(图6),这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中
LSTM的核心部分是在图4中最上边类似于传送带的部分(图6),这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中
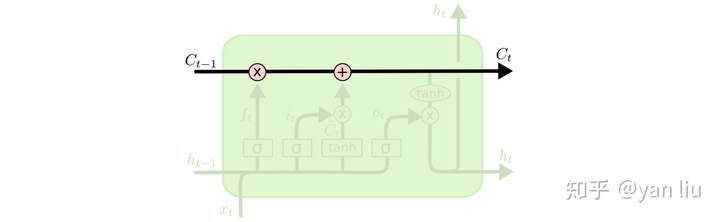
- 遗忘门
- 输入门
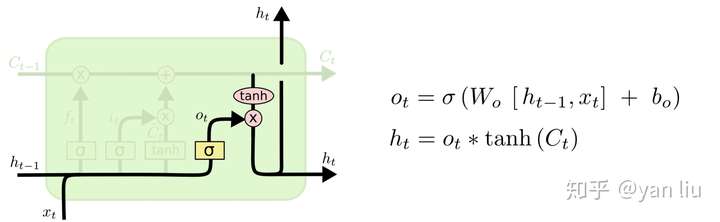
- 输出门
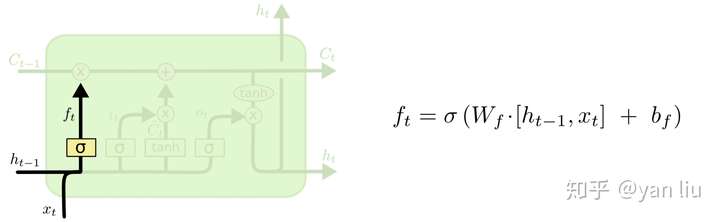
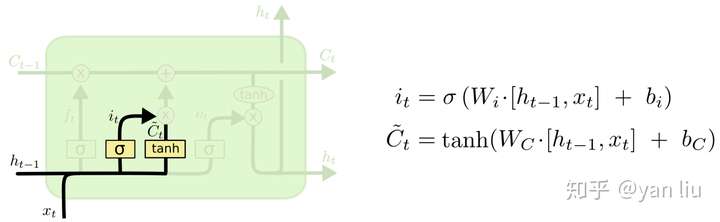
Transformer
Attention is all you need
Transformer整体结构
流程
-
step 1 输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
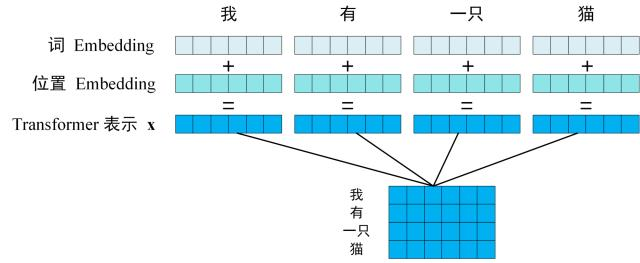
-
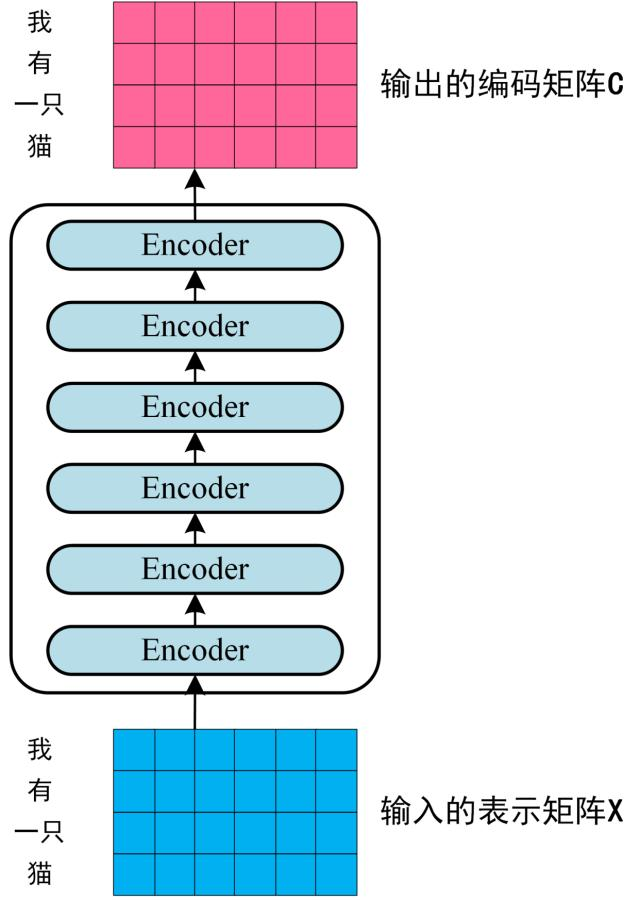
step2 经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C
- 单词向量矩阵用$X_{n*d}$
- n句子中单词个数
- d向量维度
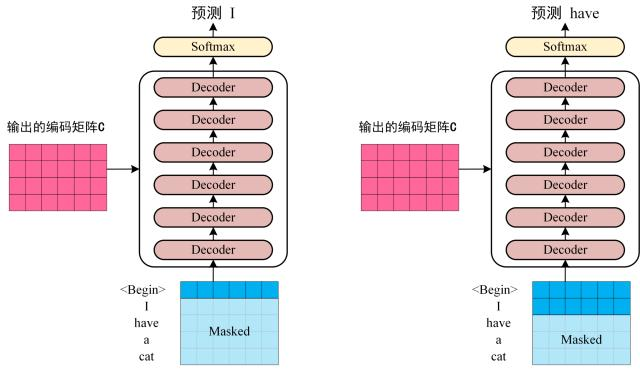
- step3
将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
Self-Attention
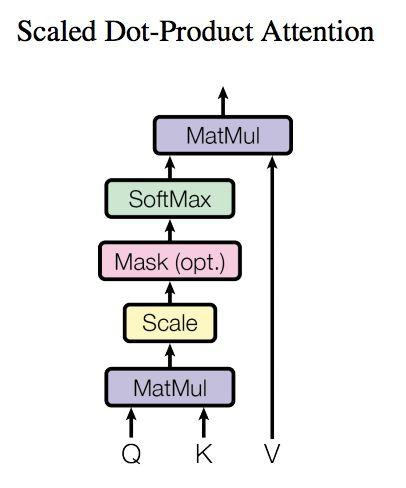 上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的

Multi-Head Attention
Multi-Head Attention 是由多个 Self-Attention 组合形成的
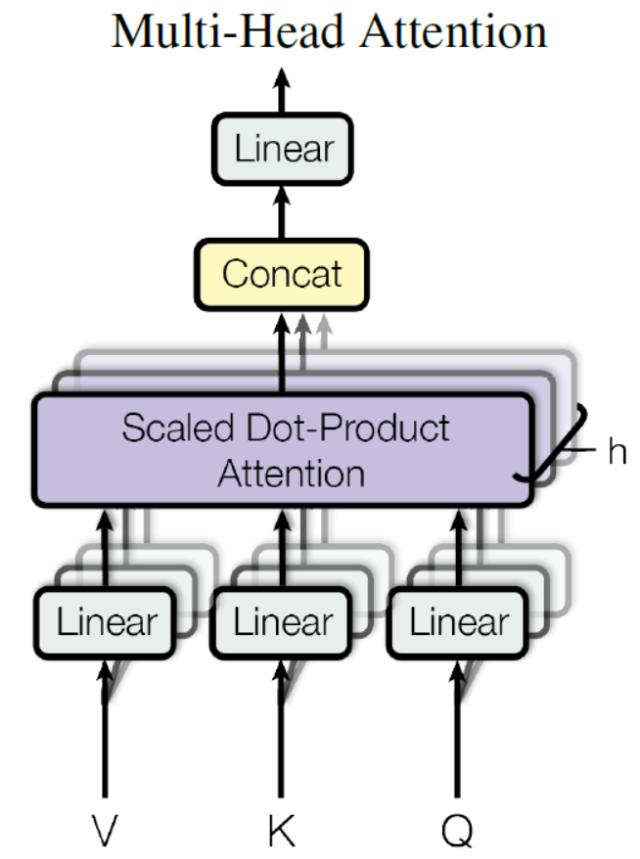 得到 8 个输出矩阵$Z_1$到$Z_8$之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
得到 8 个输出矩阵$Z_1$到$Z_8$之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
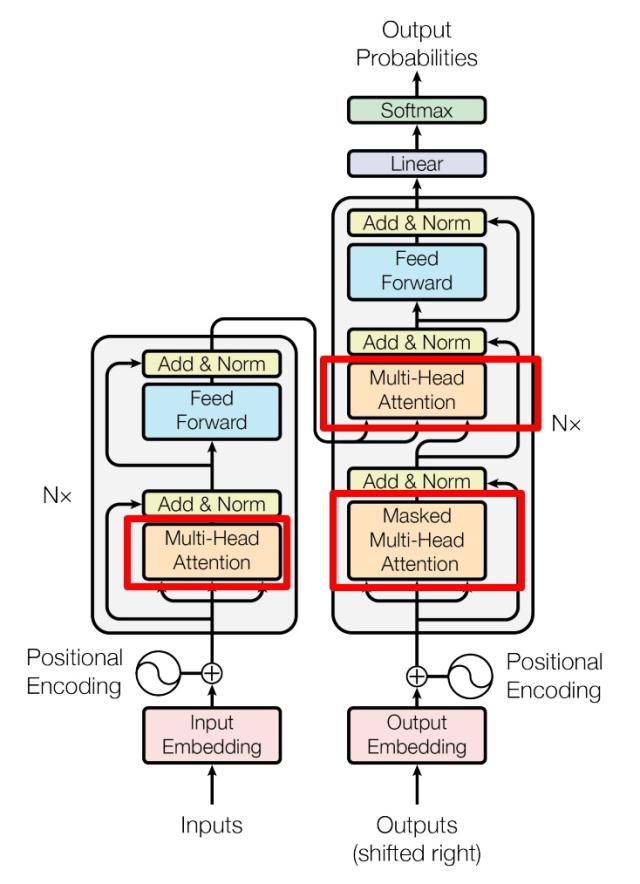
Encoder
- Multi-Head Attention
- Add & Norm
- Feed Forward
- Add & Norm
Add & Norm

- 表示 Multi-Head Attention 或者 Feed Forward 的输入
- MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到:

Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
Feed Forward
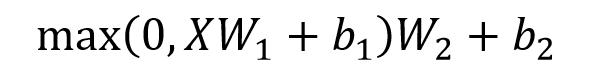
Decoder
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。