
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
推荐系统
- 离线计算的框架
- hadoop
- spark core ,spark sql
- hive
- 实时计算框架
- spark streaming
- storm
- flink
- 消息中间件
- flume 日志采集系统
- kafka消息队列
- 存储相关
- hbase nosql数据库
- hive sql操作hdfs数据
推荐算法架构
- 召回->排序->策略调整
基于内容的推荐->用户画像/标签
数据模型构建流程
- 数据收集
- 显性评分
- 隐性函数
- 特征工程
- 协同过滤:用户-物品 评分矩阵
- 基于内容: 分词 tf-idf word2vec
- 训练模型
- 协同过滤
- knn
- 矩阵分解
- 协同过滤
- 评估、模型上线
协同过滤(Collaborative Filtering)
- CF 物以类聚,人以群分
- 做系统过滤的话,首先特征工程把用户-物品的评分矩阵创建出来
- 基于用户的协同过滤
- 给用户A找最相似的N个用户
- N个用户消费过那些物品
- N-A
- 基于物品的协同过滤
相似度计算
- 余弦相似度
- pearson’s correlation
- jaccard
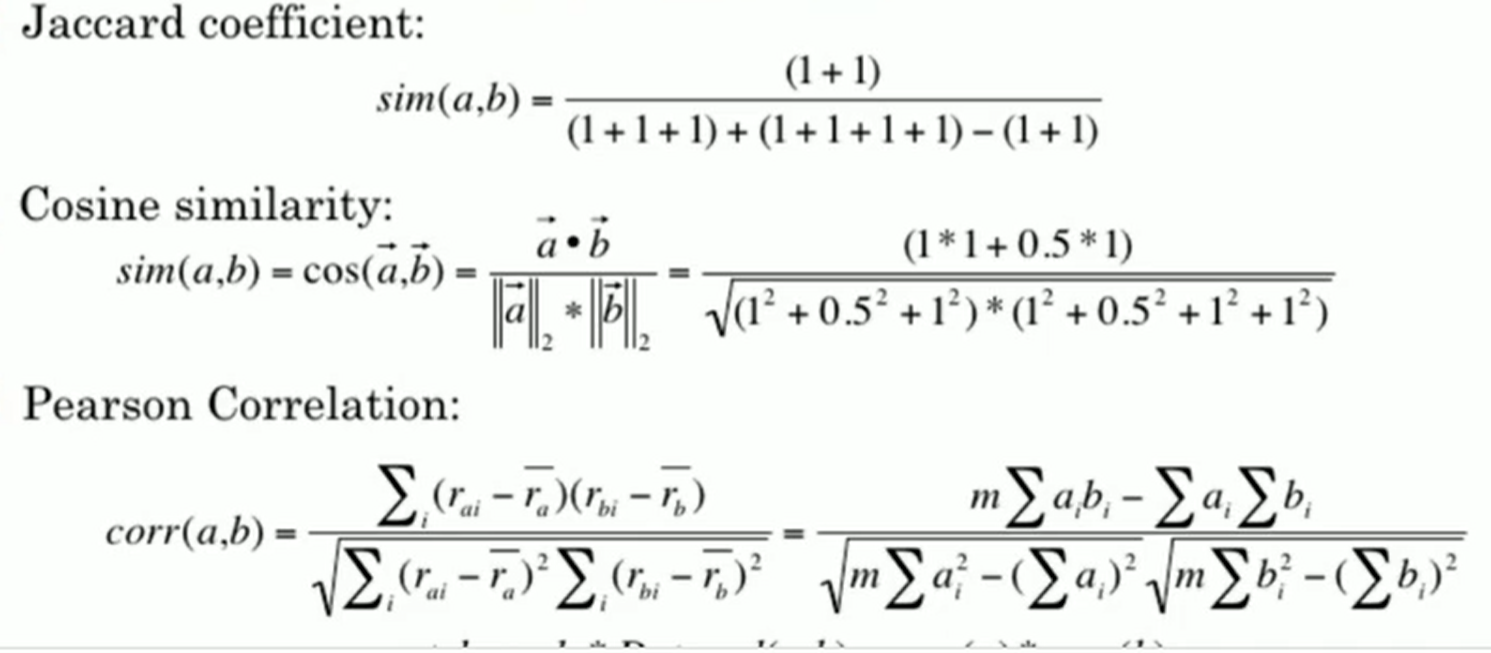
使用不同的相似度计算
- 如果 买/没买 点没点 0/1适合使用jaccard ``` import sklearn.metrics import jaccard_similarity_score jaccard_similarity_score(df[‘item A’],df[‘item B])
from sklearn.metrics.pairwise import pairwise_distances user_similar = 1-pairwise_distances(df.metric=’jaccard’) ```
- 一般用评分推荐pearson
- 基于用户/物品,实践中建议都做出来选择最优
基于模型
算法分类
- 基于图的
- 基于矩阵分解的
- ALS
- SVD
- 矩阵分解
- 把大的矩阵拆成两个小的 用户矩阵 物品矩阵
- 大矩阵约等于用户矩阵乘物品矩阵
- 使用ALS交替最小二乘法来优化损失
- 优化之后的用户矩阵 取出用户向量
- 优化之后的物品矩阵 取出物品向量
- 用户向量点乘物品向量得到最终评分
- EE
- Exploitation & Exploration 探索与利用问题
- Exploitation 利用用户的历史行为只给她曾经看到过/消费过的相似物品
- Exploration 发现用户的新兴趣
- ee问题实际是矛盾
- 评估手段
- 离线评估与在线评估结合,定期做问卷
- 在线评估
- 灰度发布 & A/B 测试
- 在线评估
- 离线评估与在线评估结合,定期做问卷
推荐系统的冷启动
- 用户冷启动
- 物品冷启动
- 系统冷启动
基于内容的推荐 基于物品的协同过滤的区别
- content_base:base:词向量——》物品向量-》计算相似度
- item_based cf : user-item matrix->物品向量->相似度
- content_base item_based cf 不一样
- 物品向量构建过程有区别
- 基于内容的推荐
- 物品向量 文本(物品的描述信息 系统填标签 用户填标签)
- 基于物品的协同过滤
- 用户对物品的评分矩阵 用户的行为数据
LMF




基于内容的推荐流程
建立物品画像
- 用户打TAG,电影的分类值
- 根据电影的id 把TAG和分类值合并起来求tf-idf
- 根据TF-IDF的结果,为每一部电影筛选出TOP-N个关键词
- 电影ID-关键词——关键词位置
建立倒排索引
- 通过关键词找到电影
- 遍历电影ID-关键词-关键词权重数据,读取每一个关键词,用关键词作为key[(关键词对应的电影 id, tfidf)] 作为value保存到dict当中
用户画像
- 看用户看到过那些电影,到电影的 电影id-关键词-关键词权重 数据中找到电影所对应的关键词
- 把用户看过的所有关键词放到一起,统计词频,每个词出现了几次
- 出现次数多的关键词,作为用户的兴趣词,这个兴趣词实际上就是用户画像的关键词
根据用户的兴趣词,找到对应的电影,多个兴趣词可能对应一个电影
- 把每一个电影对应的关键词权重求和之后,排序,权重比较高的排在前面推荐给用户
word2vec
one hot->word2vect
COBW
skip-gram