
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
Dense Passage Retrieval for Open-domain Question Answering
Abstract
开放域问答依赖于有效的段落检索来选择候选上下文,其中传统的稀疏向量空间模型,如 TF-IDF 或 BM25,是常用方法。 在这项工作中,我们展示了仅通过嵌入一个简单的双编码框架,从少量段落和问题中学习,以密集表示实现检索。 在对广泛的开放域 QA 数据集进行评估时,我们的密集检索器在前 20 个段落检索准确度方面比强大的 LuceneBM25 系统的性能大大优于 9%-19%,并帮助我们的端到端 QA 系统建立 多个开放域 QA 基准测试的最新技术。
TF-IDF or BM25 defacto method retrieval can be implemented using dense representations alone.
Introduction
阅读理解模型框架的简单两步
- 上下文检索器选择一小段,并且其中一些包含答案
- 机器阅读器可以彻底检索上下文并彻底识别
密集编码可以通过嵌入函数调整学习 通过最大内积搜索(MIPS)优化检索
ORQA有两个问题
- ICT的预训练是计算密集型,并不完全清楚常规句子是目标函数的良好替代品
- 上下文编码器没有使用成对的答案和句子微调所以相应的表示一定不是最佳的
提出问题 我们是否只用成对的问题和答案来训练更好的密集嵌入型模型,而不用额外的预训练
我们用相对小的成对问题和段落
- 贡献 首先,我们证明,通过适当的训练设置,只需在现有问题-段落对上微调问题和段落编码器就足以大大优于 BM25。 其次,我们验证,在开放域问答的背景下,更高的检索精度确实转化为更高的端到端 QA 精度。
DPR
overview
大多数可分解的函数是欧氏距离变换的
Encoders
我们用两个独立的BERT网络并且并将 [CLS] 标记处的表示作为输出,因此 d = 768。
Inference
using FAISS
Training
Positive and negative passages
三种负面类型
- Random:来自语料库的任何随机段落
- BM25:BM25返回的不包含答案但匹配大多数问题标记的顶部段落
- Gold:正面段落与训练集中出现的其他问题配对。
我们最好的模型使用来自同一小批量的Glod通道和一个 BM25 负通道。
In-batch negatives
Experimental Setup
Experiments: Passage Retrieval
main result
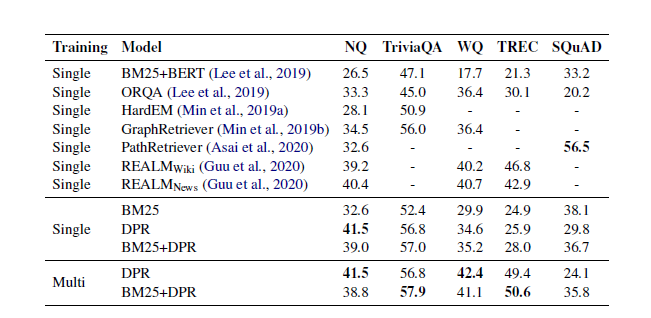
推测在SQuAD低表现的两个原因
- 注释者看到文章后写问题,因此段落问题之间存在高度词汇重叠BM25要好
- 训练仅从500多篇维基百科中数据分布存在偏差
Ablation Study on Model Training
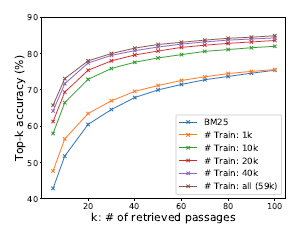
Sample efficiency
使用一般的预训练语言模型,可以用少量的问题-段落对训练高质量的密集检索器。
in-batch negative training
发现当 k >= 20 时,在此设置中选择否定词——Random、BM25 或Gold段落(来自其他问题的积极段落)——不会对 top-k 准确度产生太大影响。
Similarity and loss
L2的性能与dp相当,两者都优于余弦
Cross-dataset generalization
我们仅在自然问题上训练 DPR,并直接在较小的 WebQuestions 和 CuratedTREC 数据集上对其进行测试。

Qualitative Analysis
像 BM25 这样的术语匹配方法对高度选择性的关键字和短语很敏感,而 DPR 可以更好地捕捉词汇变体或语义关系。
run-time Efficiency
DPR每秒处理 995.0 个问题,每个问题返回前 100 个段落。 BM25 23.7/s 相比之下,使用 Lucene 构建倒排索引要便宜得多,总共只需要大约 30 分钟
Experiments Question Answering
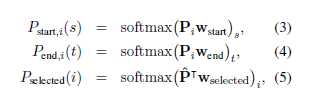
Conclusion
- 我们展示了成功训练密集检索的一些关键因素。
- 更复杂的模型框架或相似函数不一定能提供额外的价值。
Appendix
文本相似度(TF-IDF&BM25)
TF-IDF(Term Frequency-inverse Document Frequency)
是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或一个语料库的重要程度。
一个词的重要程度跟他在的文章出现次数成正比,跟他在语料库出现的次数成反比
- TF(某词在文章出现总次数) TF=$\frac{某词在文档出现的次数}{文档的总词量}$
- IDF(逆向文档频率) IDF=$log\frac{语料库中文档总数}{包含该词文档数+1}$
- TFIDF=TFxIDF TFIDF值越大表示该特征词对于这个文本的重要性越大
BM25(Best Match25)
通常用来做搜索相关性评分。 主要思想: 对Query进行语速解析,生成语速qi,然后对于每个搜索结果D,计算每个语速qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
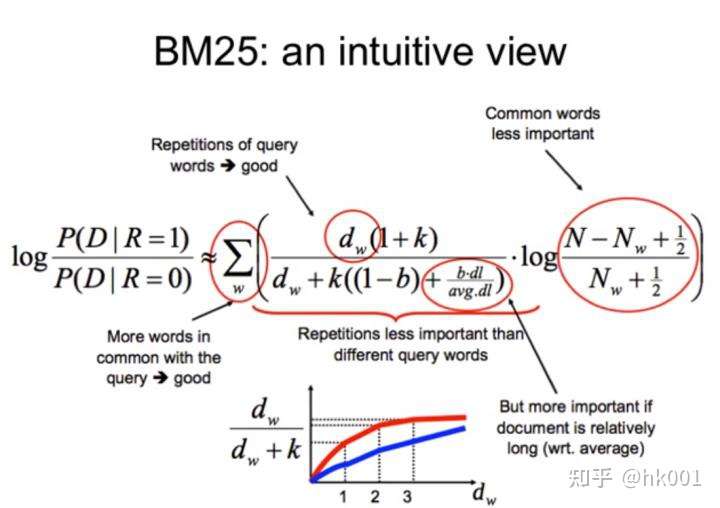 \(score(D,Q)=\sum_{i=1}^nIDF(q_i)·\frac{f(q_i,D)·(k_1+1)}{f(q_i,D)+k_1·(1-b+b·\frac{|D|}{avgdl})}\)
\(score(D,Q)=\sum_{i=1}^nIDF(q_i)·\frac{f(q_i,D)·(k_1+1)}{f(q_i,D)+k_1·(1-b+b·\frac{|D|}{avgdl})}\)
- IDF-IDF
- f-TF
-
D -文档D长度 - avgdl-语料库全部文档平均长度
- $k_1\in{[1.2,2.0]}$
- b = 0.75
MIPS
MIPS的定义很简单,假设你有一堆d维向量,组成集合X,现在输入了一个同样维度的查询向量q(query),请从X中找出一个p,使得p和q的点积在集合X是最大的。用公式写出来就是
\(p=argmax_{x\in X }x^Tq\) 这个问题和最近邻问题很像,最近邻问题只要把上面的定义改成找一个p使得p和q的距离最小,假设这个距离是欧氏距离,则
\(p=argmin_{x\in X}||q-x||^2=(||x||^2-2q^Tx)\) 如果X中的向量模长都一样,那两个问题其实是等价的。然而在很多实际场景例如BERT编码后的句向量、推荐系统里的各种Embedding等,这个约束是不满足的。 最近邻搜索其实应用非常广泛,如图片检索、推荐系统、问答等等。以问答匹配为例,虽然我们可以用BERT这样的大型模型获得很好的准确度,但如果用BERT直接对语料库中的所有问题进行计算,将耗费大量的时间。所以可以先用关键词检索或者向量检索从语料库里召回一些候选语料后再做高精度匹配。
FAISS(Facebook AI Similarity Search)
这是一个开源库,针对高维空间中的海量数据,提供了高效且可靠的检索方法。 暴力检索耗时巨大,对于一个要求实时人脸识别的应用来说是不可取的。 而Faiss则为这种场景提供了一套解决方案。 Faiss从两个方面改善了暴力搜索算法存在的问题:降低空间占用加快检索速度首先, Faiss中提供了若干种方法实现数据压缩,包括PCA、Product-Quantization等
Ref
@inproceedings{karpukhin-etal-2020-dense,
title = "Dense Passage Retrieval for Open-Domain Question Answering",
author = "Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.550",
doi = "10.18653/v1/2020.emnlp-main.550",
pages = "6769--6781",
}