
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
key point
- GLM
existing pretraining framework
- autoregressive
- autoencoding
- encoder-decoder
##
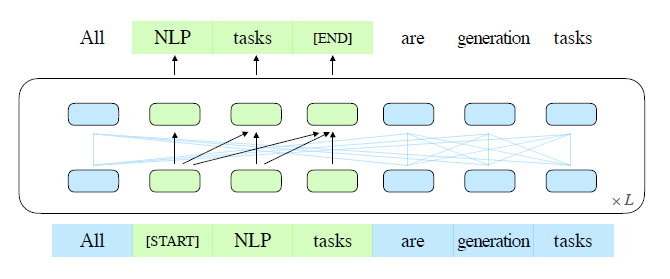
we propose a pretraining framework named GML (General Language Model),based on autoregressive blank infilling.
we propose two improvements,
- span shuffling
- 2D positional encoding
Pretraining objective
Autoregressive Blank Infilling
Multi-Task Pretraining
- Document-level
- Ssentence-level
Model Architecture
GLM uses a single Transformer with several modifications to the architecture
2D Positional Encoding

Finetuning GLM
Experiments
pretraining setup
data using
- BooksCorpus
- English Wikipedia
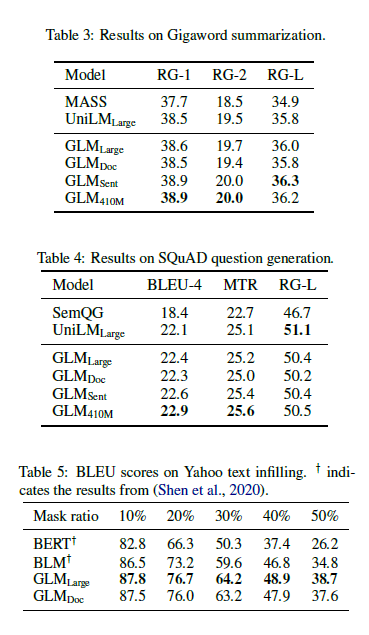
multi-task pretraining
two Large-sized model with a mixture of the blank infilling objective, denoted as GLM(doc) and GLM(sent)
Compare with SOTA models
superGLUE
Multi-Task Pretraining
we evaluate the multi-task model for NLU ,seq2seq,blank infilling, and zero-shot language modeling.
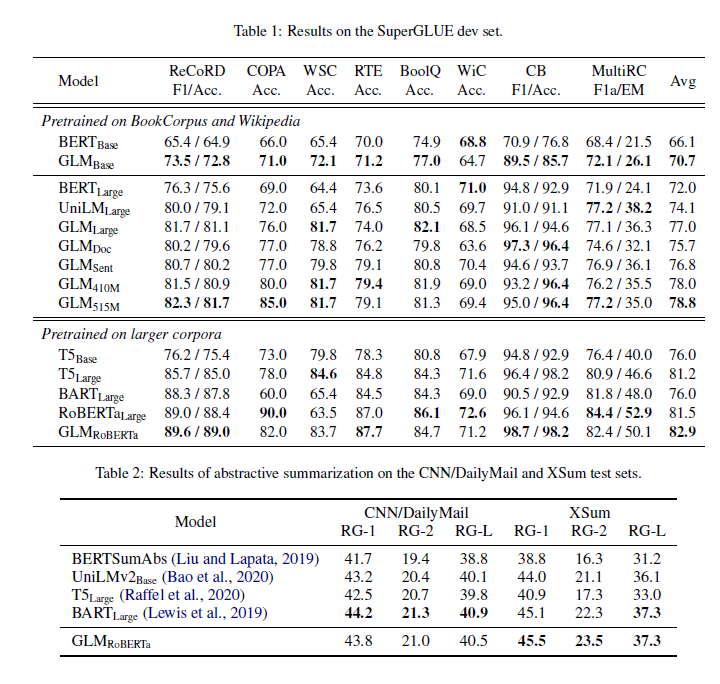
- SuperGLUE
- Sequence-to-Sequence
- Text Infilling
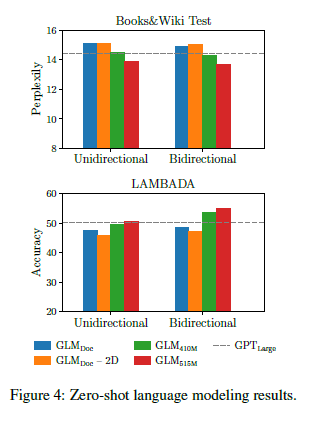
Ablation Study
重新梳理补充GLM130B系列
这应该算是第三遍读该文章,emmm没办法太菜了。我后面尽量补充我理解到的细节
GLM
2022年3月见刊不过工作应该是2021年完成的
- GLM是一个自回归模型,
- 提升填空预测通过2D位置编码并且允许随机序列去预测空白,使其在NLU任务上超过BERT和T5。
- GLM可以预训练不同种类的任务通过非定长数字和长度的空。
之前有工作想大一统NLP所有任务,目前貌似没有能继承所有框架优势的。
GLM随机blank输入
GLM自然可以处理完形填空问题的多标记答案 通过自回归空白填充。
条件文本生成和语言建模任务一起共享参数。
- 自回归空白填充
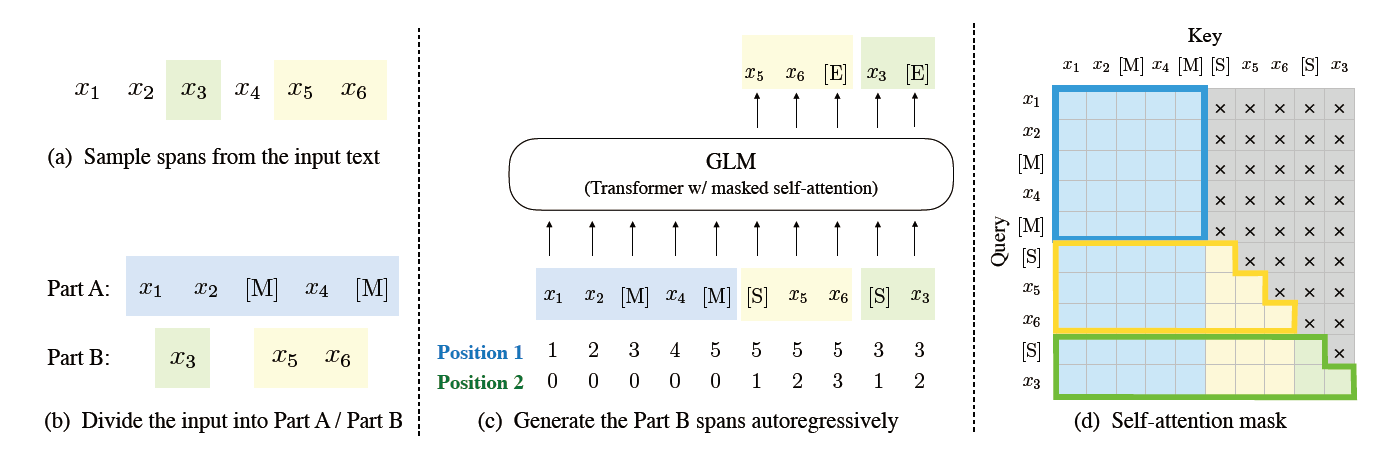
给定一个输入 $x=[x_1,…,x_n]$ 采样多文本spans {$s_1,…,s_m$} 每一个span $s_i$对应的x一系列连续的tokens $[s_{i,1},…,s_{i,l_i}]$ 每一个span都会被单独的MASKtoken代替 从而形成损坏文本$x_{corrupt}$
模型会从损坏文本中通过自回归方式预测消失的token
这意味着在预测消失的token在span中时,模型可以获取损坏文本和之前预测的span。 为了尽可能抓取不同span间的内在关系。我们随机排列span的顺序。
形式上,设 $Z_m$ 为所有可能的集合 长度为 m 的索引序列的排列
$[1,2,…,m]$
$s_{z<i}$代表$[s_{z1},…,s_{z_{i-1}}]$
那我们定义预训练目标为
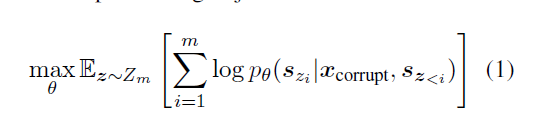
产生spans $s_i$ 的概率为
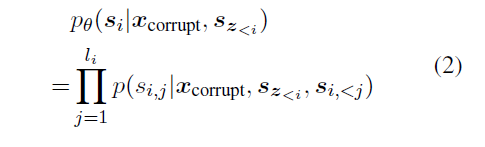
我们把输入x分成两部分
A:是损坏文本$x_{corrupt}$ B:是masked的span A不能加入B.只能同类加入 B可以加入A,但自身不能加入任何子序列
为了可以做自回归生成,每个span用特殊的token[START]和[END]填充
通过这种方式,我们的模型会自动学习双向编码器(A),和单项解码器(B)在一个统一的模型中。
我们随机采样span长度通过位置分布$\lambda=3$,我们重复采样新的span直到剩下的15%token。(经验)
为了能适应NLU任务和生成任务: 我们考虑如下两个目标:
-
文档级别: 采样span长度在50%-100%,目的在长文本生成。
-
句子级别: 我们限制masked的span必须是整句。大概会覆盖源文本的15%左右。目的在seq2seq任务。
这俩唯一的区别就是spans的数量和span的长度
模型结构
GLM 用一个单独的transformer和几个修改构成
- 我们重排了正则层和残差连接,避免数字错误
- 我们用单一的线性层作为output的token预测
- 我们用GeLUs代替了ReLU激活层
2D位置编码
每个token有两个位置id。
- 第一个位置id表示损坏文本$x_{corrupt}$
- 第二个位置id表示跨度内(intra-span)位置
对于A来说,第二个位置id=0 对于B来说,第二个位置id=1——span长度 两个文职id在两个向量通过可学习嵌入表,都加入输入token的embedding中。
微调
我们针对NLU分类任务重塑为生成的完形填空(PET)
“{SENTENCE}. It’s really MASK”
推理
本模型推理依赖Megatron-M和DeepSpeed
GLM130B
从2022-5-6到2022-7-3
本次训练用了96张DGX-A100(8X40G)集群
130B刚好可以满足单个A100服务器推理
同时采用了int4精度
关于训练稳定性问题
- 选择合适的LN(layer Normalization) Post-LN 和 DeepNorm 展现出稳定性的潜力
Positional Encoding 和 FFNs.
-
对于位置编码采用Rotary Positional Encoding(RoPE)
-
对于Transformer中的FFN选择GLU同时+GeLU激活层作为选择
3D并行策略: 流水线并行
混合精度
Embedding层梯度压缩
INT4 Quantization for RTX 3090s/2080s.