
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
自动微分
在训练神经网络时,最常用的算法是 反向传播。在该算法中,参数(模型权重)根据损失函数相对于给定参数的梯度进行调整。
为了计算这些梯度,PyTorch 有一个内置的微分引擎,称为torch.autograd. 它支持任何计算图的梯度自动计算。
考虑最简单的一层神经网络,具有输入x、参数w和b以及一些损失函数。它可以通过以下方式在 PyTorch 中定义:
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
张量、函数和计算图
此代码定义以下计算图:
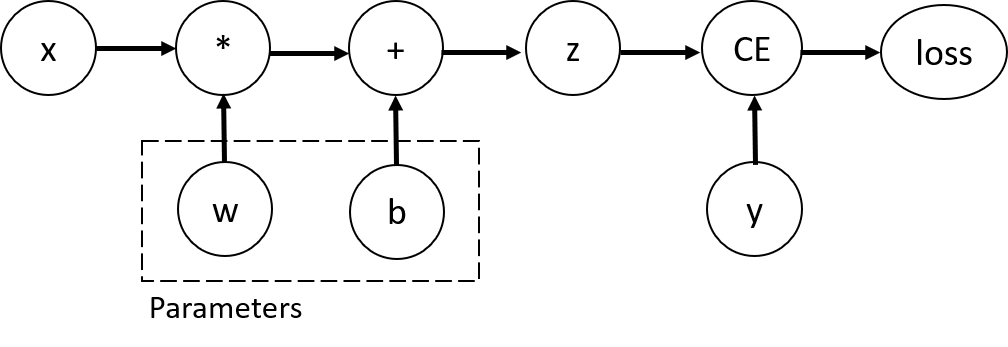
在这个网络中,w和b是我们需要优化的参数。因此,我们需要能够计算损失函数相对于这些变量的梯度。为了做到这一点,我们设置了requires_grad这些张量的属性。
您可以在创建张量时设置 的值,也可以requires_grad稍后使用x.requires_grad_(True)方法设置。
我们应用于张量以构建计算图的函数实际上是 class 的一个对象Function。这个对象知道如何计算正向的函数,以及如何在反向传播步骤中计算它的导数。对反向传播函数的引用存储在grad_fn张量的属性中。Function 您可以在文档中找到更多信息。
print(f"Gradient function for z = {z.grad_fn}")
print(f"Gradient function for loss = {loss.grad_fn}")
OUT:
Gradient function for z = <AddBackward0 object at 0x7f2f16380490>
Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward0 object at 0x7f2f0ce96a10>
计算梯度
为了优化神经网络中参数的权重,我们需要计算我们的损失函数对参数的导数,即我们需要\frac{\partial loss}{\partial w} ∂ w ∂ l oss 和 \frac{\部分损失}{\partial b} ∂ b ∂ l oss x在和的一些固定值下 y。为了计算这些导数,我们调用 loss.backward(),然后从w.grad和 检索值b.grad
loss.backward()
print(w.grad)
print(b.grad)
OUT:
tensor([[0.0067, 0.3295, 0.0549],
[0.0067, 0.3295, 0.0549],
[0.0067, 0.3295, 0.0549],
[0.0067, 0.3295, 0.0549],
[0.0067, 0.3295, 0.0549]])
tensor([0.0067, 0.3295, 0.0549])
- 我们只能获取grad计算图的叶节点的属性,这些叶节点的requires_grad属性设置为True。对于我们图中的所有其他节点,梯度将不可用。
- 出于性能原因,我们只能 backward在给定图上使用一次执行梯度计算。如果我们需要backward在同一个图上进行多次调用,我们需要传递 retain_graph=True给backward调用。
禁用梯度跟踪
默认情况下,所有张量requires_grad=True都在跟踪它们的计算历史并支持梯度计算。但是,在某些情况下我们不需要这样做,例如,当我们训练了模型并且只想将其应用于某些输入数据时,即我们只想通过网络进行前向计算。我们可以通过用块包围我们的计算代码来停止跟踪计算 torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
OUT:
True
False
实现相同结果的另一种方法是使用detach()张量上的方法:
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
OUT:
False
您可能希望禁用梯度跟踪的原因如下:
-
将神经网络中的一些参数标记为冻结参数。这是 微调预训练网络的一个非常常见的场景
-
当您只进行前向传递时加快计算速度,因为在不跟踪梯度的张量上进行计算会更有效。
关于计算图
从概念上讲,autograd 在由 Function 对象组成的有向无环图 (DAG) 中记录数据(张量)和所有执行的操作(以及生成的新张量)。在这个 DAG 中,叶子是输入张量,根是输出张量。通过从根到叶跟踪此图,您可以使用链式法则自动计算梯度。
在前向传递中,autograd 同时做两件事:
-
运行请求的操作以计算结果张量
-
在 DAG 中保持操作的梯度函数。
.backward()在 DAG 根上调用后向传递开始。autograd然后:
-
计算每个 的梯度.grad_fn,
-
将它们累积在相应张量的.grad属性中
-
使用链式法则,一直传播到叶张量。
DAG 在 PyTorch 中是动态 的 需要注意的重要一点是图形是从头开始重新创建的;每次 .backward()调用后,autograd 开始填充新图表。这正是允许您在模型中使用控制流语句的原因;如果需要,您可以在每次迭代时更改形状、大小和操作。
张量梯度和雅可比积
在许多情况下,我们有一个标量损失函数,我们需要计算一些参数的梯度。但是,有些情况下输出函数是任意张量。在这种情况下,PyTorch 允许您计算所谓的雅可比积,而不是实际的梯度。
对于向量函数\vec{y}=f(\vec{x})
是的
=f (
X
), 在哪里 \vec{x}=\langle x_1,\dots,x_n\rangle
X
=⟨ x
1
,…,X
n
⟩和 \vec{y}=\langle y_1,\dots,y_m\rangle
是的
=⟨是
1
,…,是的
米
⟩, 梯度 \vec{y}
是的
关于\vec{x}
X
由雅可比矩阵给出:
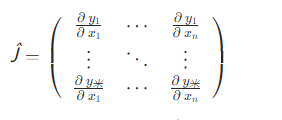
PyTorch 无需计算雅可比矩阵本身,而是允许您计算雅可比积 v^T\cdot Jv 吨 ⋅Ĵ对于给定的输入向量 v=(v_1 \dots v_m)v=(五 1 …v 米 ). 这是通过调用来实现backward的 vv作为论据。的大小vv应该与我们想要计算乘积的原始张量的大小相同
inp = torch.eye(5, requires_grad=True)
out = (inp+1).pow(2)
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"First call\n{inp.grad}")
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
OUT:
First call
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])
Second call
tensor([[8., 4., 4., 4., 4.],
[4., 8., 4., 4., 4.],
[4., 4., 8., 4., 4.],
[4., 4., 4., 8., 4.],
[4., 4., 4., 4., 8.]])
Call after zeroing gradients
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])
请注意,当我们backward使用相同的参数第二次调用时,梯度的值是不同的。发生这种情况是因为在进行backward传播时,PyTorch会累积梯度,即计算梯度的值被添加到 grad计算图的所有叶节点的属性中。如果要计算正确的梯度,则需要grad 先将属性归零。在现实生活中的训练中,优化器可以帮助我们做到这一点。
以前我们是在backward()没有参数的情况下调用函数。这本质上等同于调用 backward(torch.tensor(1.0)),这是在标量值函数的情况下计算梯度的有用方法,例如神经网络训练期间的损失。