CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
review
word2vector
- COBW
- skip-gram
there are two main improvement methods for word2vec:
- Negative sampleing
- Hierarchical softmax
Other tips for learning word embeddings
- soft sliding window
RNN
Application
- sequence labeling
- sequence prediction
- photograph description
- text classification
Advantages:
- can process any length input
- model size does not increase for longer input
- weights are shared across timesteps
- computiation for step i can (in theory ) use information from many steps back
disadvantages:
- Recurrent computation is slow
- In practice , it’s difficult to access information from many steps back
Gradient problem for RNN
- Gradient vanish or explode
GRU
- upadte gate
- reset gate
LSTM
- state Ct
- forget gate
- input gate
- output gate
bidirectional RNNs
- the whole input sequence
CNN
Sentiment classification,Relation classification,phrases and other local grammer structures
CNN extract pattens by:
- computing representations for all possible n-gram phrases in a sentence.
- without relying on external linguistic tools
Architecture
- input layer
- convolutional layer
- max-pooling Layer
- Non-linear layer
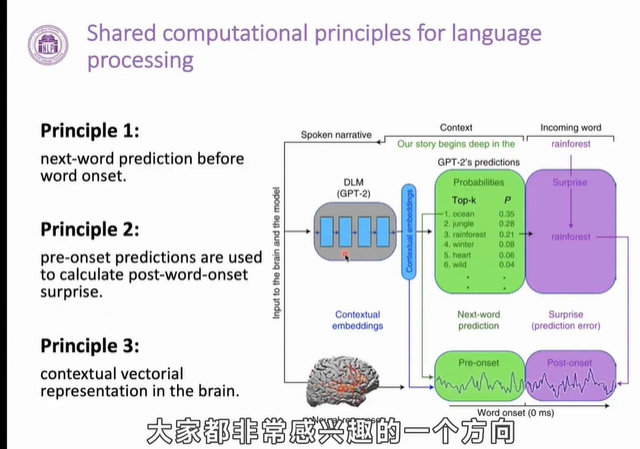
Transformer
Attenton
- the bottleneck problem
single vector needs to capture all information
limits the representation capacity of the encoder
at each step of decoder,focus on particular part of the source sequence
-
Given a query vector and a set of value vectors, the attention technique computes a weighted sum of the values accorrding to the query

-
Insights of Attention
- Attetion sloves the bottleneck problem
- Attention helps with vanishing gradient problem
- Attention provides some inerpretability
Input encoding
- Byte Pair Encoding (BPE)
- a word segmentation algorithm
- start with a vocabulary of characters
- turn the most frequent n-gram to new n-gram
- low :5 lower :2 newest :6 wildest:3
solve OOV(out of vocabulary) problem
- Positional Encoding(PE)

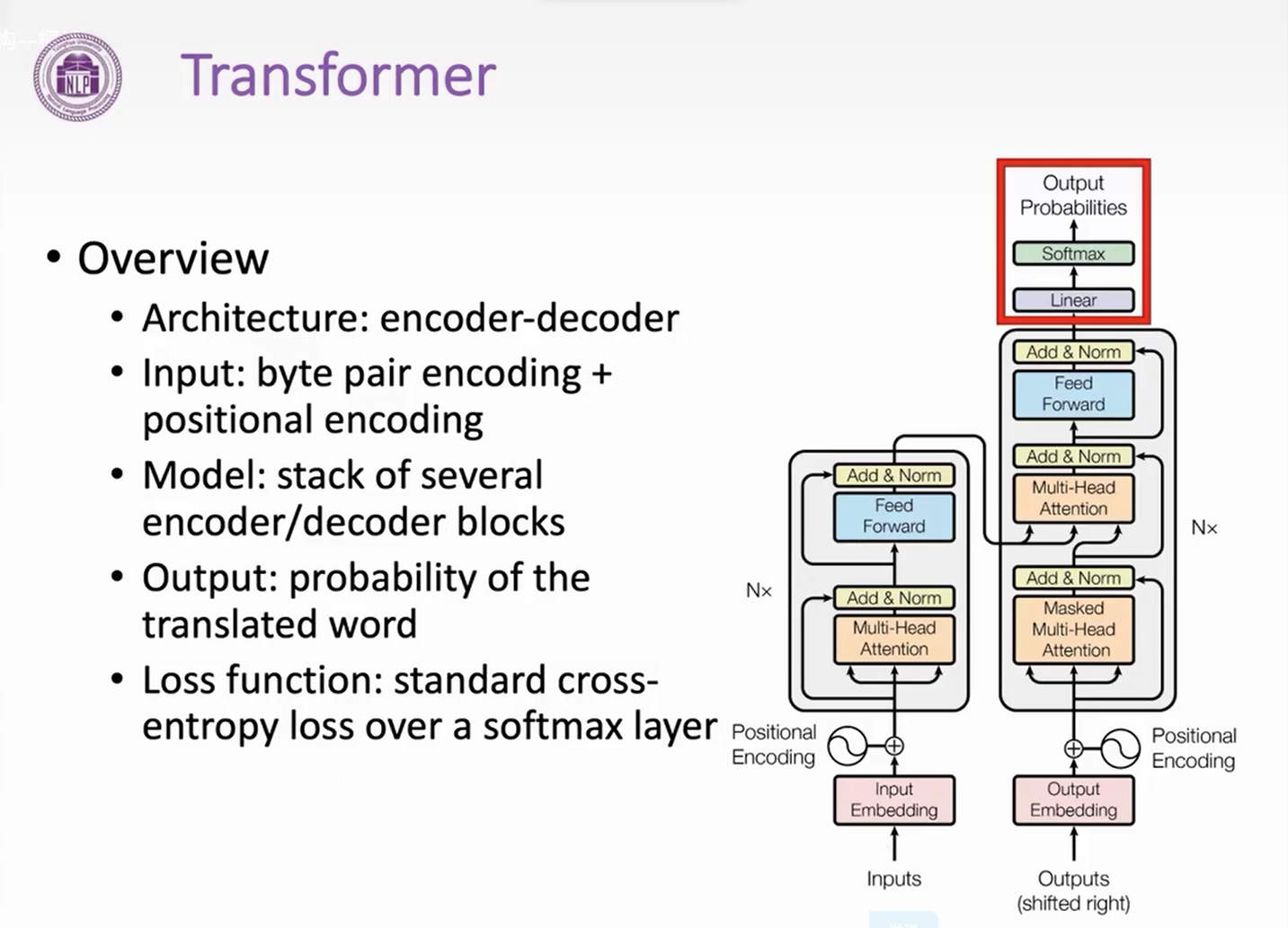
encoder
transformer Block
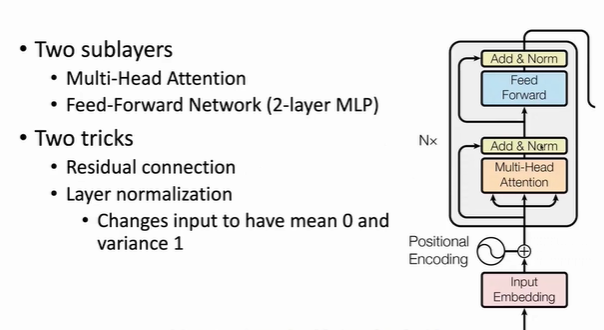
- Two sublayers
- Two tricks
-
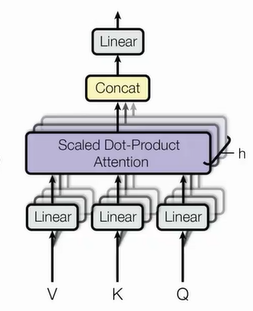
General Dot-Product Attentions
-
Scaled Dot-Product Attention
-
Multi-head Attention
decoder
- Two changes:
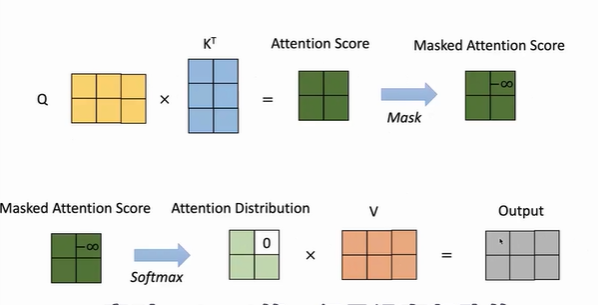
- Masked self-attention
- Encoder-decoder attention
- Blocks are also repeated 6 times
tricks
- checkpoint averaging
- ADAM optimizer
- Dropout during training at every layer just before adding residual
- label smoothing
- Auto-regressive decoding with beam search and length penalties

PLM
GPT
- GPT is the first work to pre-train a PLM based on Transformer
- Transformer + Left-to-right LM
- Fine-tuned on downstream tasks
GPT2
- A huge Transformer LM
- Trained on 40Gb of text
- SOTA perplexities on datasets it’s not even trained on
Zero-shot Learning
Ask LM to gengerate from a prompt
reading Comprehension
Summarization
Question Answering
Bert 2019
BERT : Masked LM

BERT:Next Sentence Prediction
- To learn relationships between sentences , predict whether Sentence B is the actual sentence that proceeds Sentence A , or just a random sentence
BERT: Input Representation
Use 30000 WordPiece vocabulary on input (data driven slipt way)
BERT problem
- gap
- efficiency
RoBERTa
- Explore several pre-training approaches for a more robust BERT
- Dynamic Masking
- Model Input Format
- Next Sentence Prediction
- Training with Large Batches
- Text Encoding
- Massive experiments
ELECTRA
- recall
- Traditional LM
- Replaced Token Detection
forcast
- GPT3
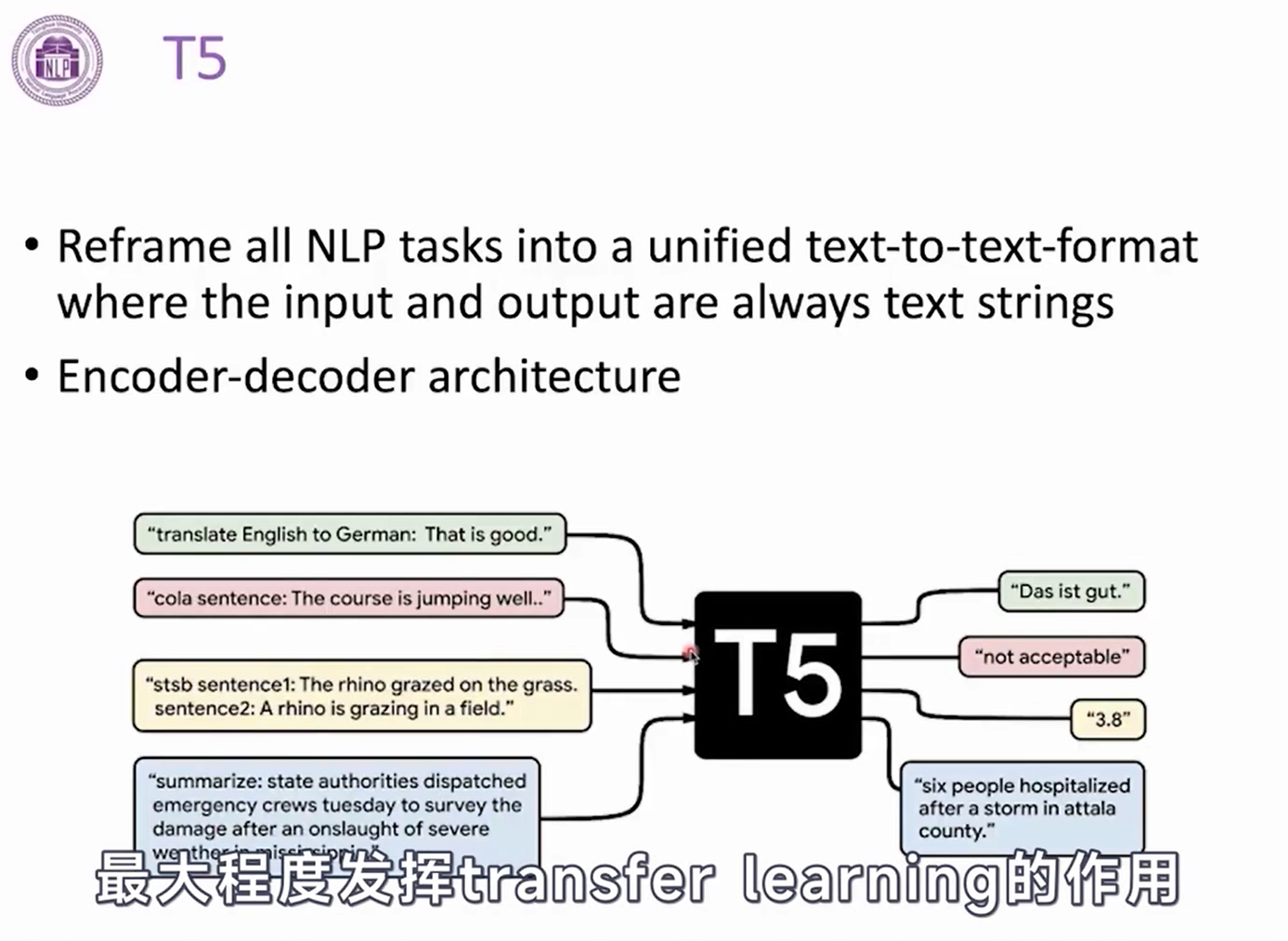
- T5
- Larger Model with MoE
- Enhance encoder-decoder with MoE(Mixture of Experts)
- Gshard 600B parameters
- Switch Transformer 1571B parameters
Transformers
Pipeline
Tokenization


prompt-Learning & delta - learning

prompt-Learning
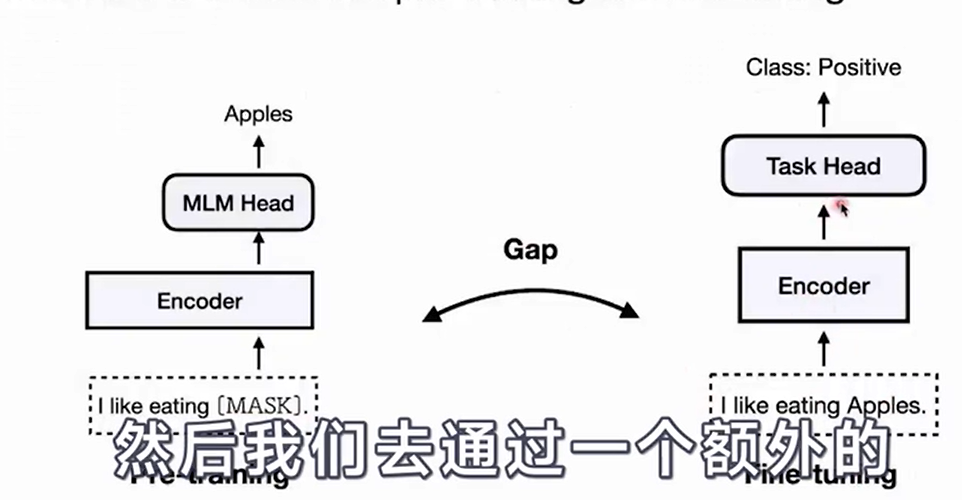
- Prompt-learning
- use PLMs as base encoders
- Add additional neural layers for specific tasks
- Tune all the parameters
- There is a GAP between pre-training and fine-tuning
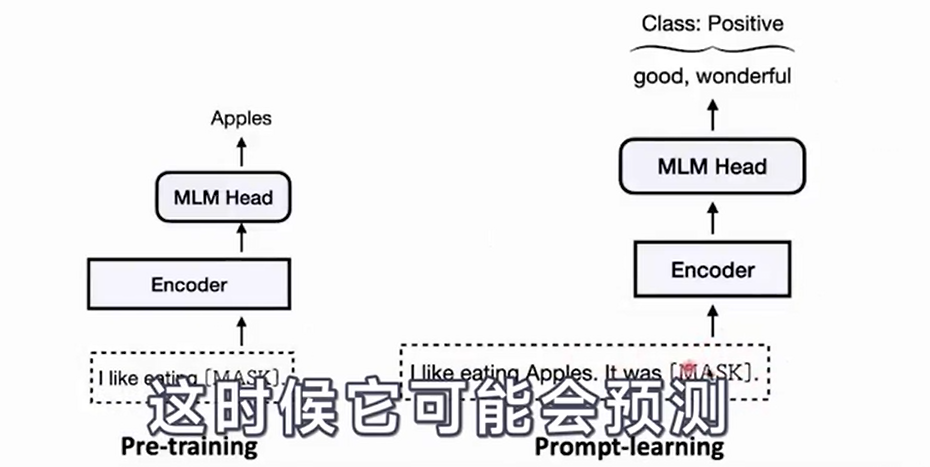
- prompt-learning
- Use PLMs as base encoders
- Add additional context(template) with a [MASK] position
- Project labels to label words (verbalizer)
- Bridge the GAP between pre-training and fine-tuning
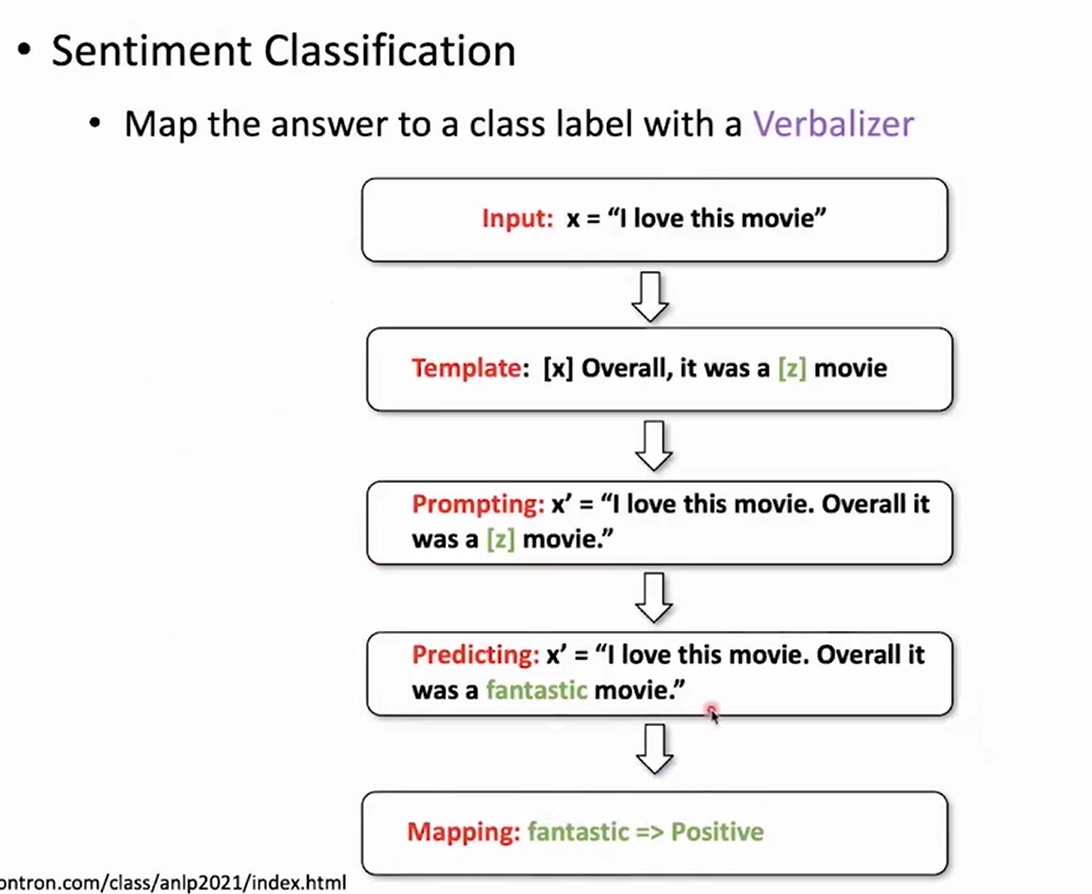
Considerations
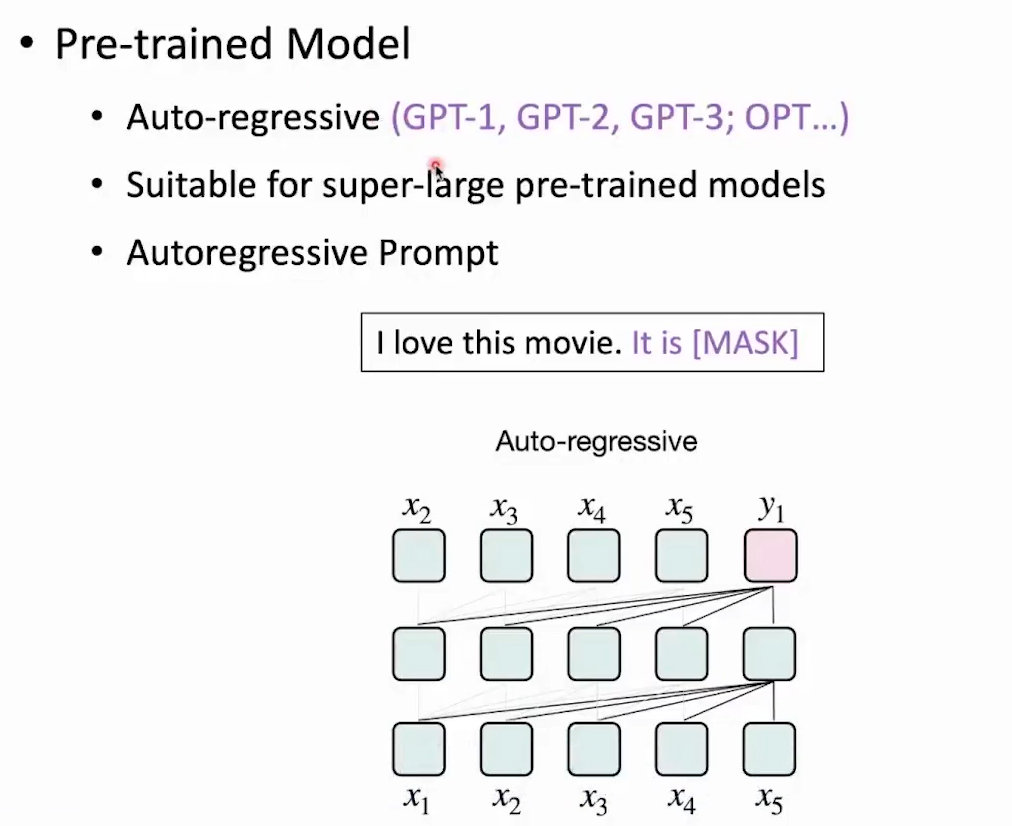
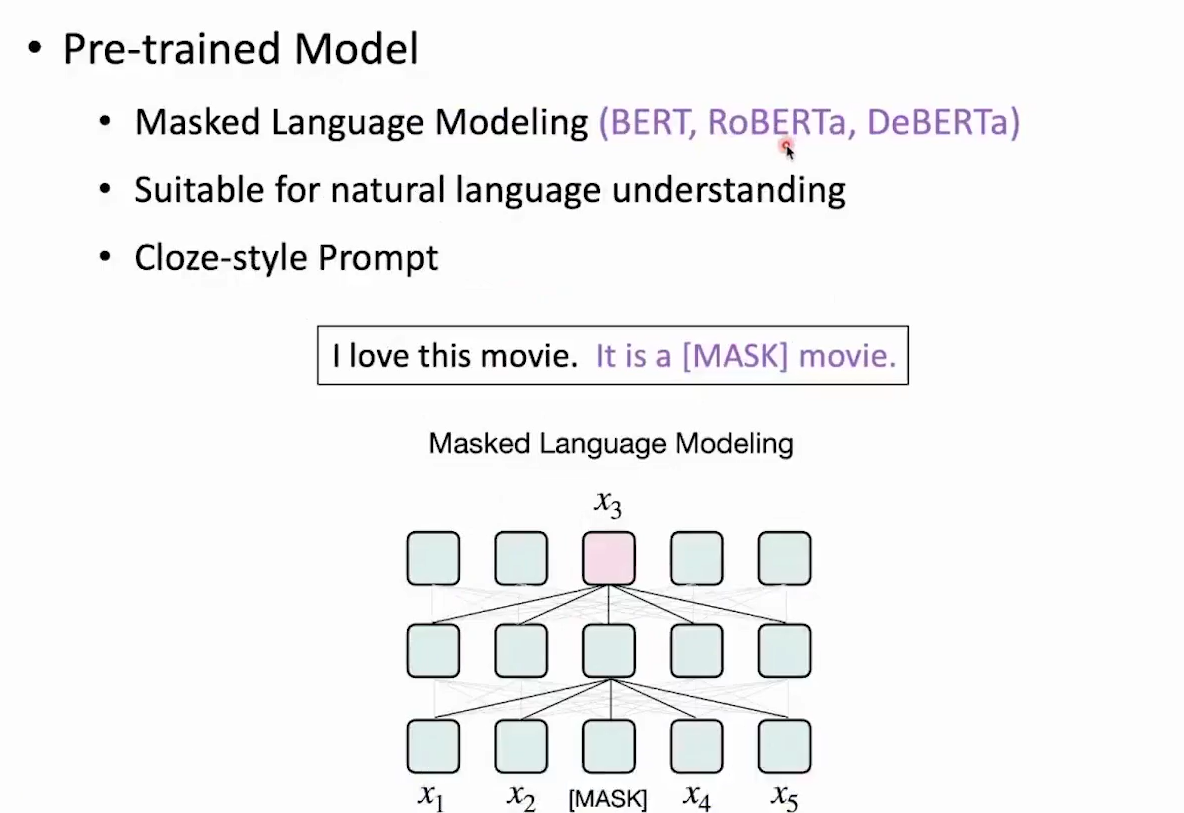
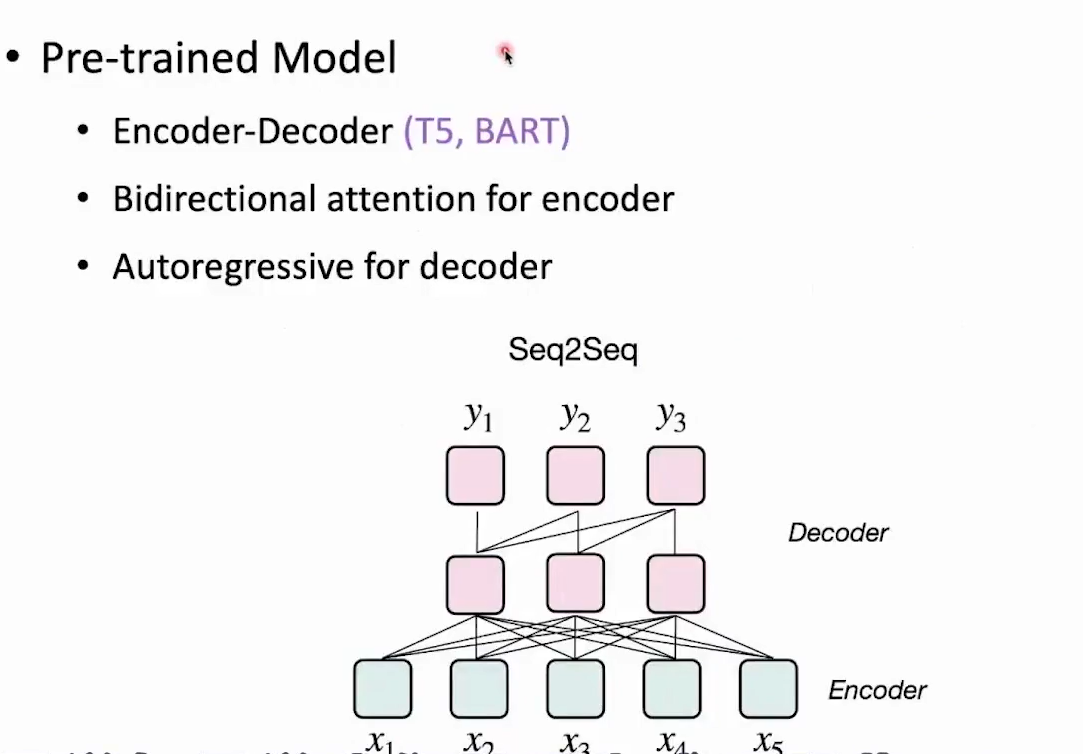
- pre-trained Model
- auto-regressive
- MLM
- Encoder-Decoder
- Template
- Manually Desing
- Auto Generation
- Textual or Continuous
- Verbalizer
- Manually Design
- Expanding by external konwledge
pre
Template
- Template Construction
- Manually Design based on the characteristics of the task
- Auto Generation with search or optimization
- Textual or Continuous
- Structured incorporating with rules
Delta Tuning
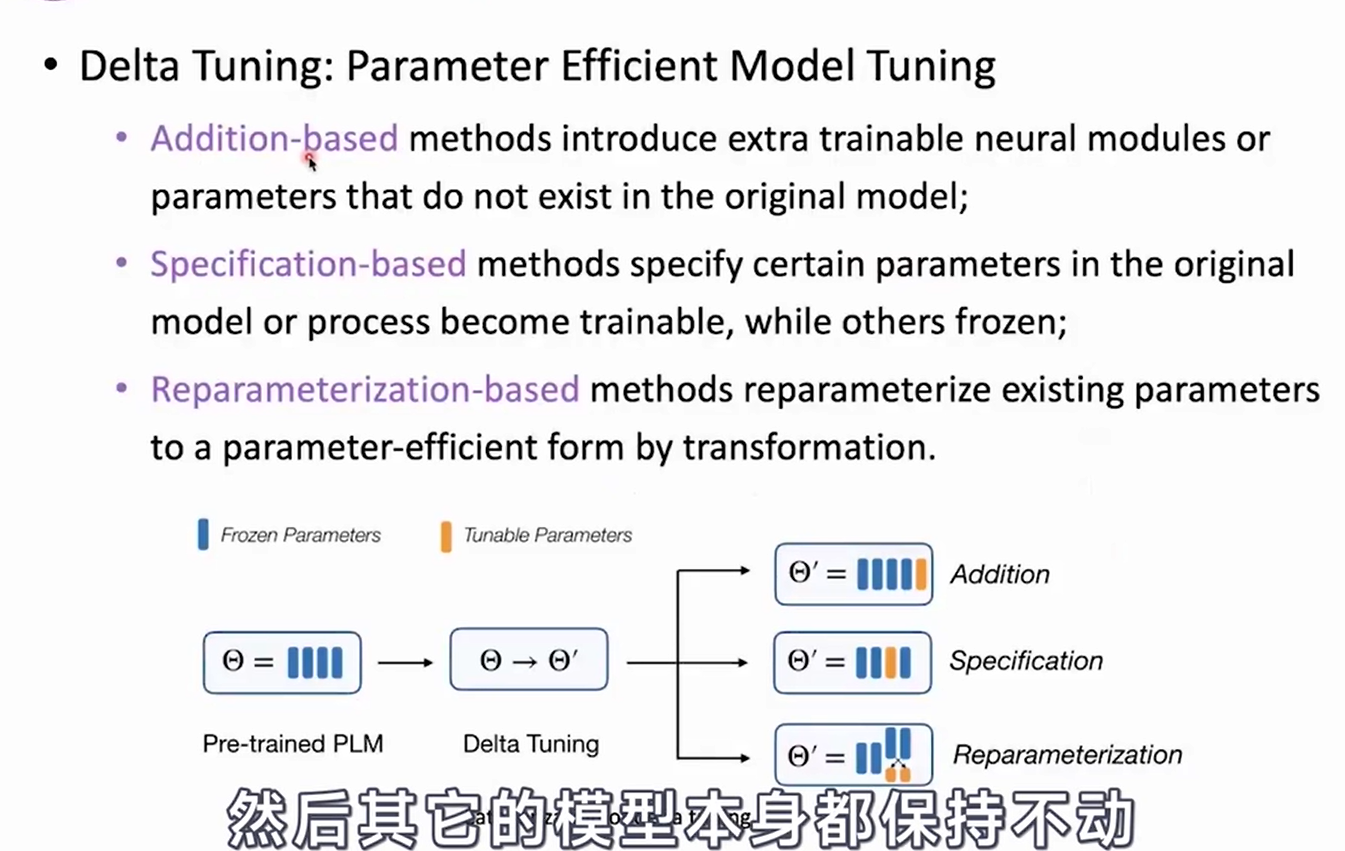
- Adapter-Tuning
- Injecting small neural modules()
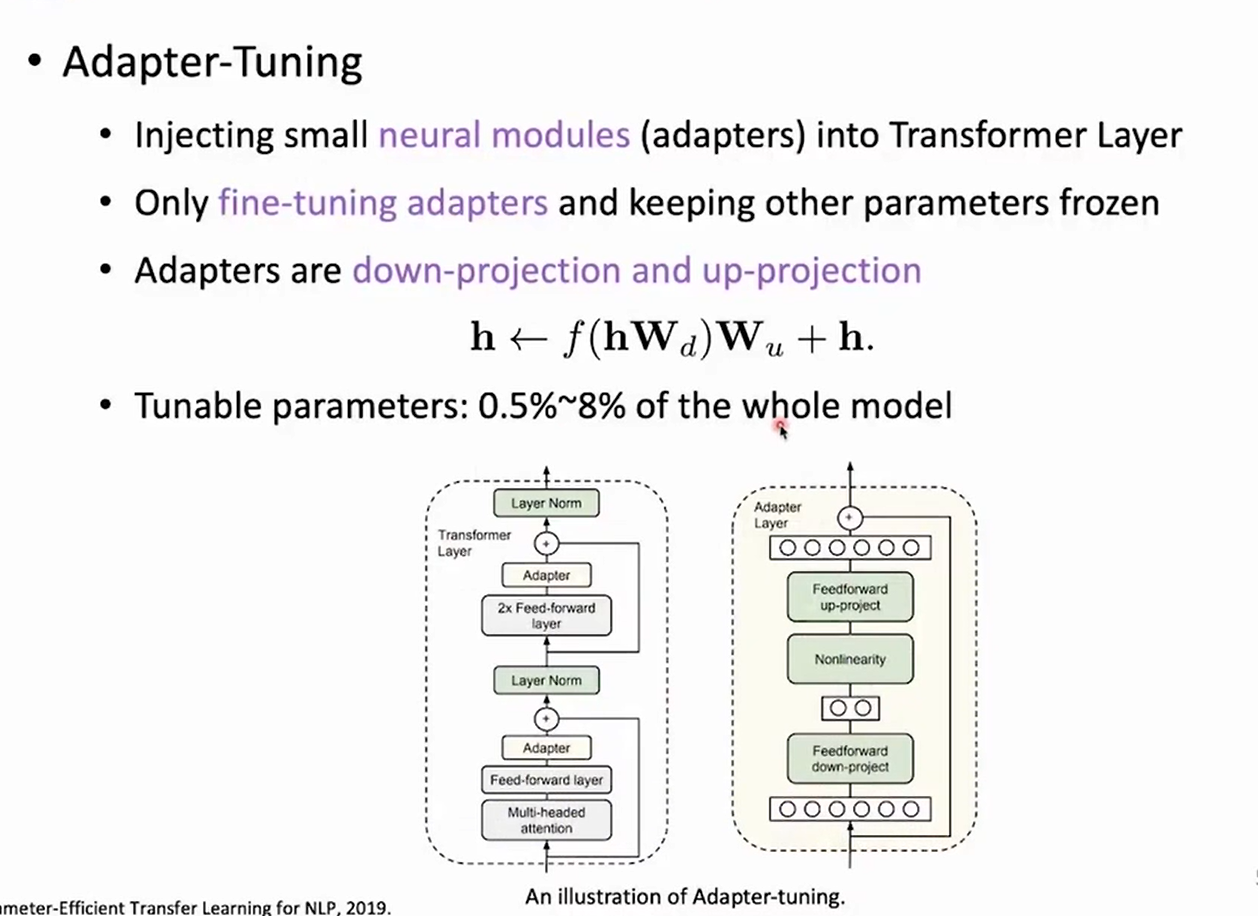
- Injecting small neural modules()
- Move the Adapter out of the Backbone
-
Prefix-Tuning
-
BitFit
- Intrinstic Prompt Tuning
OpenPrompt & OpenDelta API
BMtrain

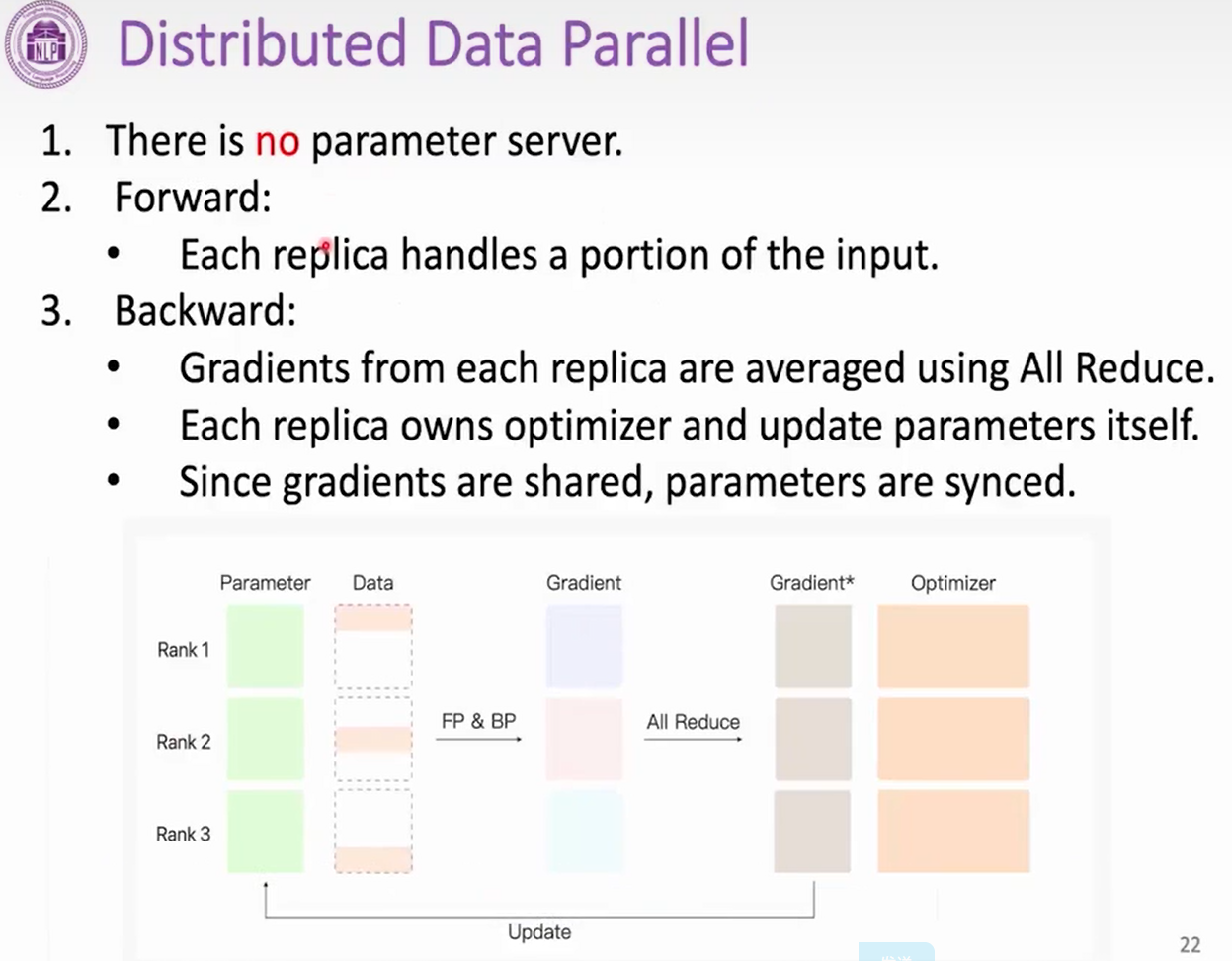
- Data Parallel
- There is a parameter server
- forward
- the parameter is replicated on each divce -echa replica handles a portion of the input
- Backward
- Gradients from each replica are averaged
- Avergaed gradients are used to update the parameter server
Broadcast
send data from one GPU to other GPUs
Reduce
Reduce (sum/Average) data of all GPUs, send to one GPU.
All Reduce
Reduce (Sum/Average) data of all GPUs ,send to all GPUs
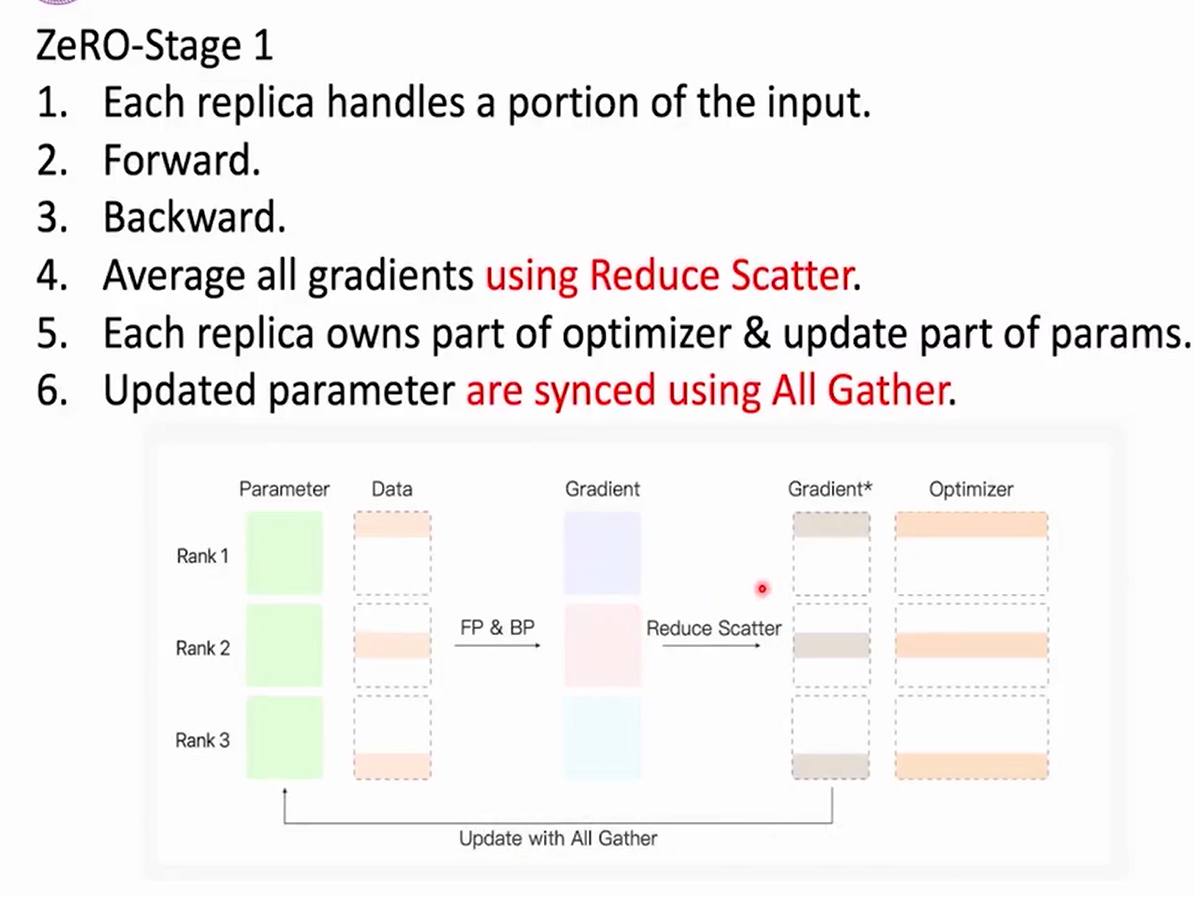
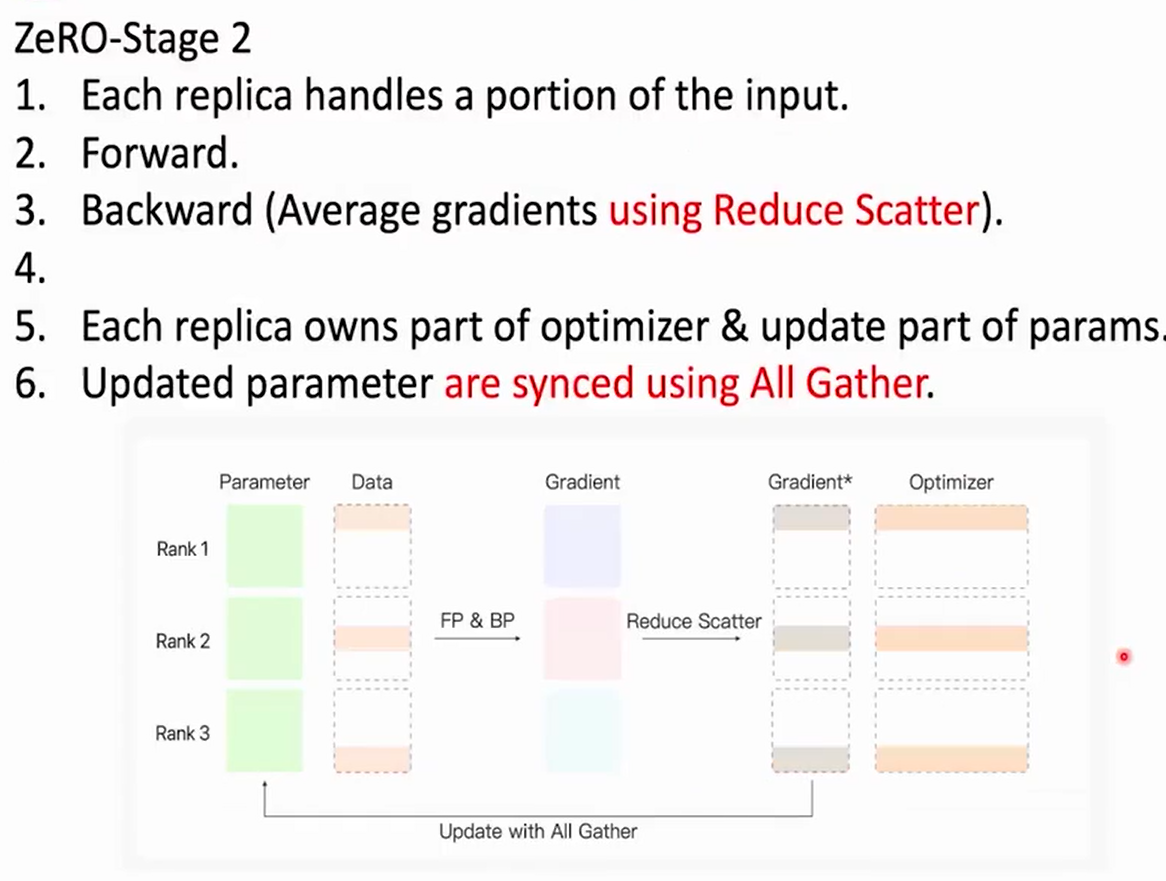
Reduce Scatter
Reduce (Sum/Average) data of all GPUs,send portions to all GPUs.
ALL Gather
Gather data of all GPUs,send all GPUs
Methods
- Data Parallel
- Model Parallel
- ZeRO
- Pipeline Parallel
Data Parallel
Model Parallel
Zore Redundancy Optimizer

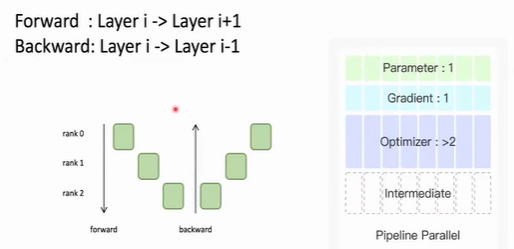
Pieline parallel
1 Transformer are partitioned layer by layer 2 Different layers are put on different GPUs.
Mixed Precision
FP32:1.18e-38~3.40e38 with 6-9 significant decimal digits precision
FP16:6.10e-5~65504 with 4 significant decimal digits precision.
advantages:
- Math operations run much faster
- Math operations run even more faster with Tensor Core support
- Data transfer operations require less memory bandwidth
- Smaller range but not overflow
disadvantages
- Weight update ~~ gradient*lr samller range,especially underflow.
Offloading
- Bind each GPU with multiple GPUs
- Offload the partitioned optimizer states to CPU
Overlapping
- Memory operations are asynchronous
- thus ,we can overlap Memory operations with Calculations.
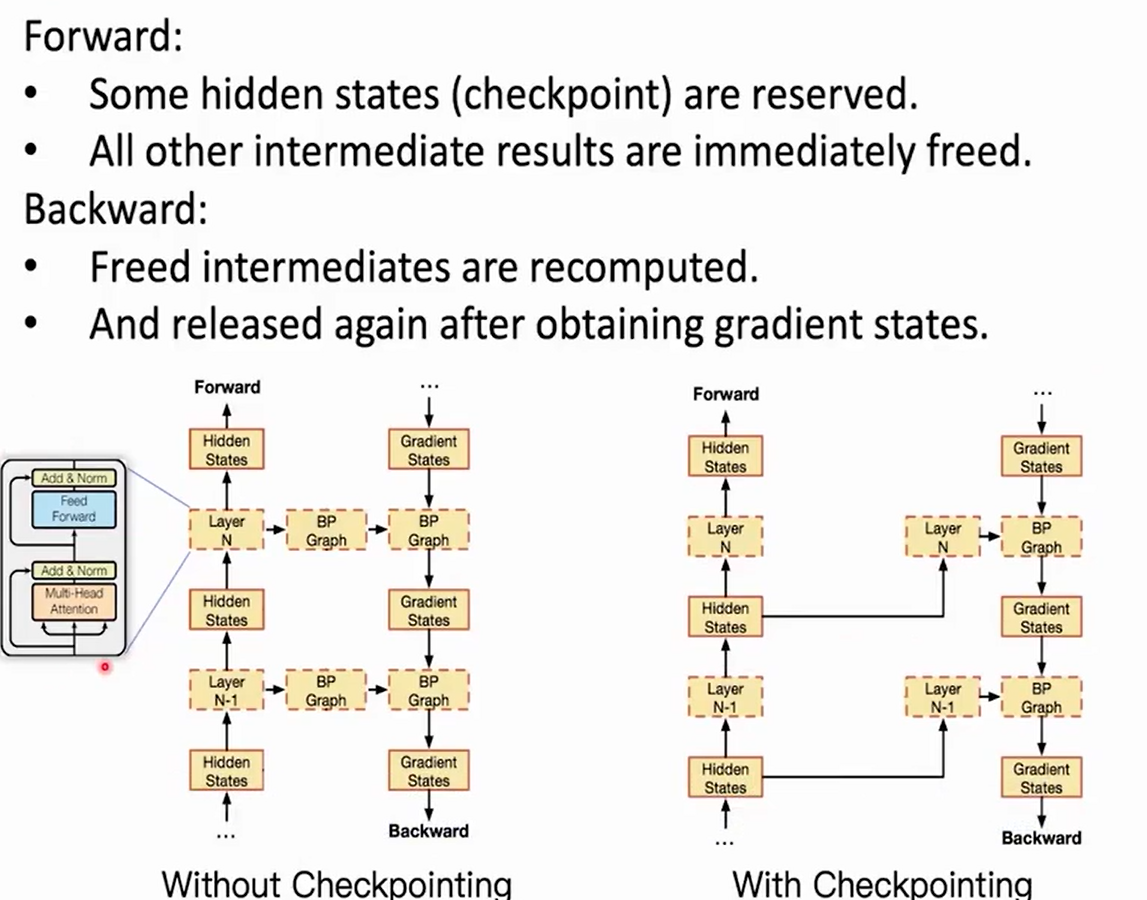
Checkpointing
BMCook
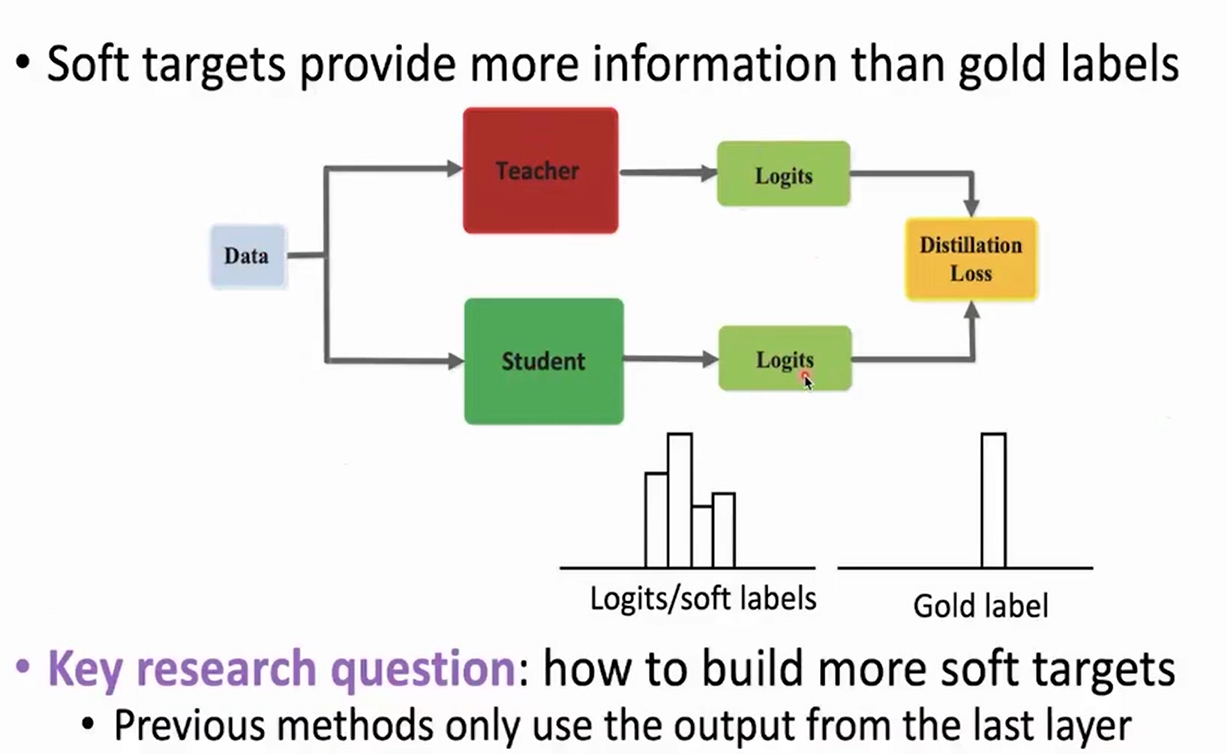
Knowledge Distillation
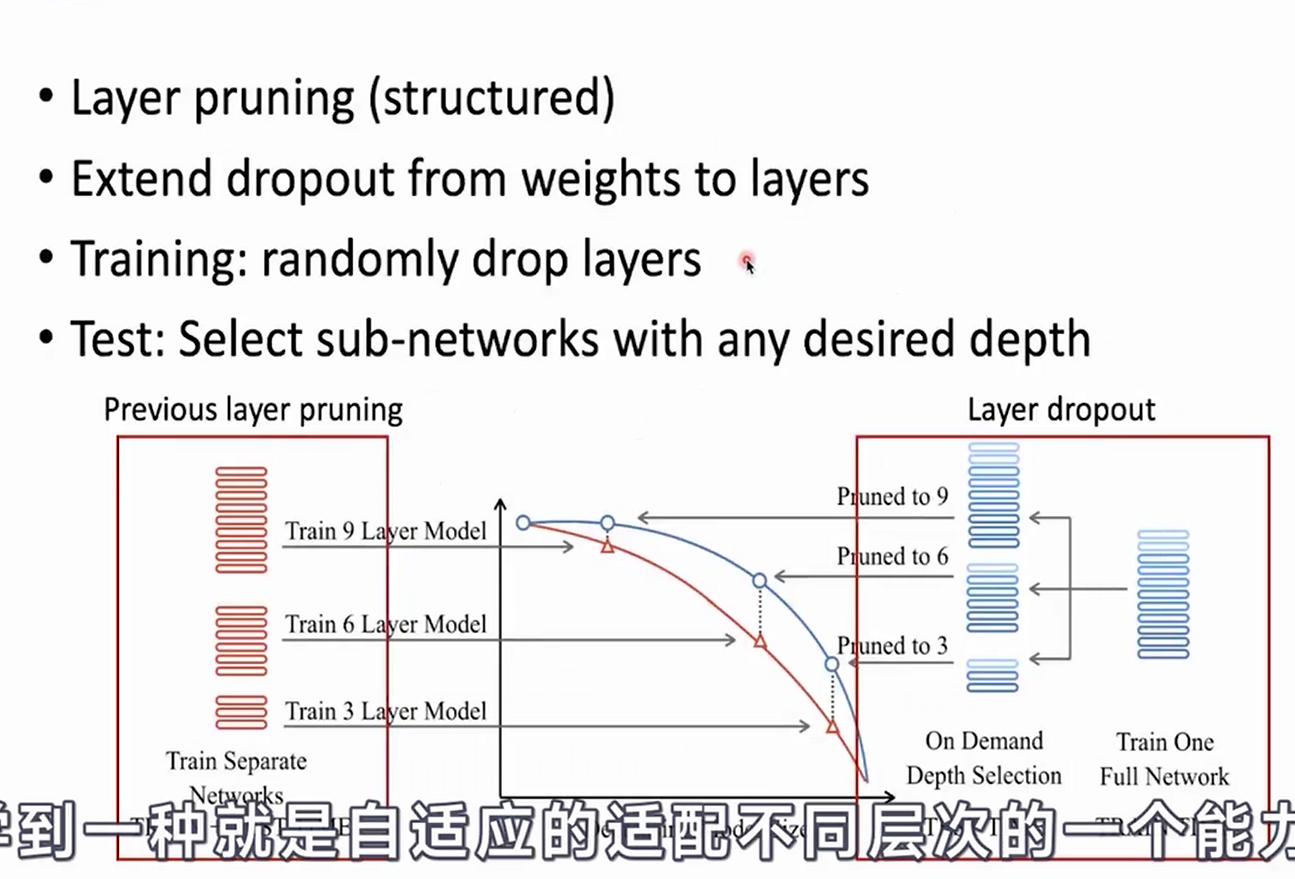
Model pruning
- Remove the redundant parts of the parameter matrix according to their important scores
- Unstructured pruning and structured pruning
Model Quantization
- Reduce the number of bits used to represent a value
- Floating point representations _> Fixed point representation
- Three steps
- Linear scaling
- Quantize
- Scaling back
Other Methods:
- Weight Sharing
- Low-rank Approximation
- Architecture Search
BMInf
IR
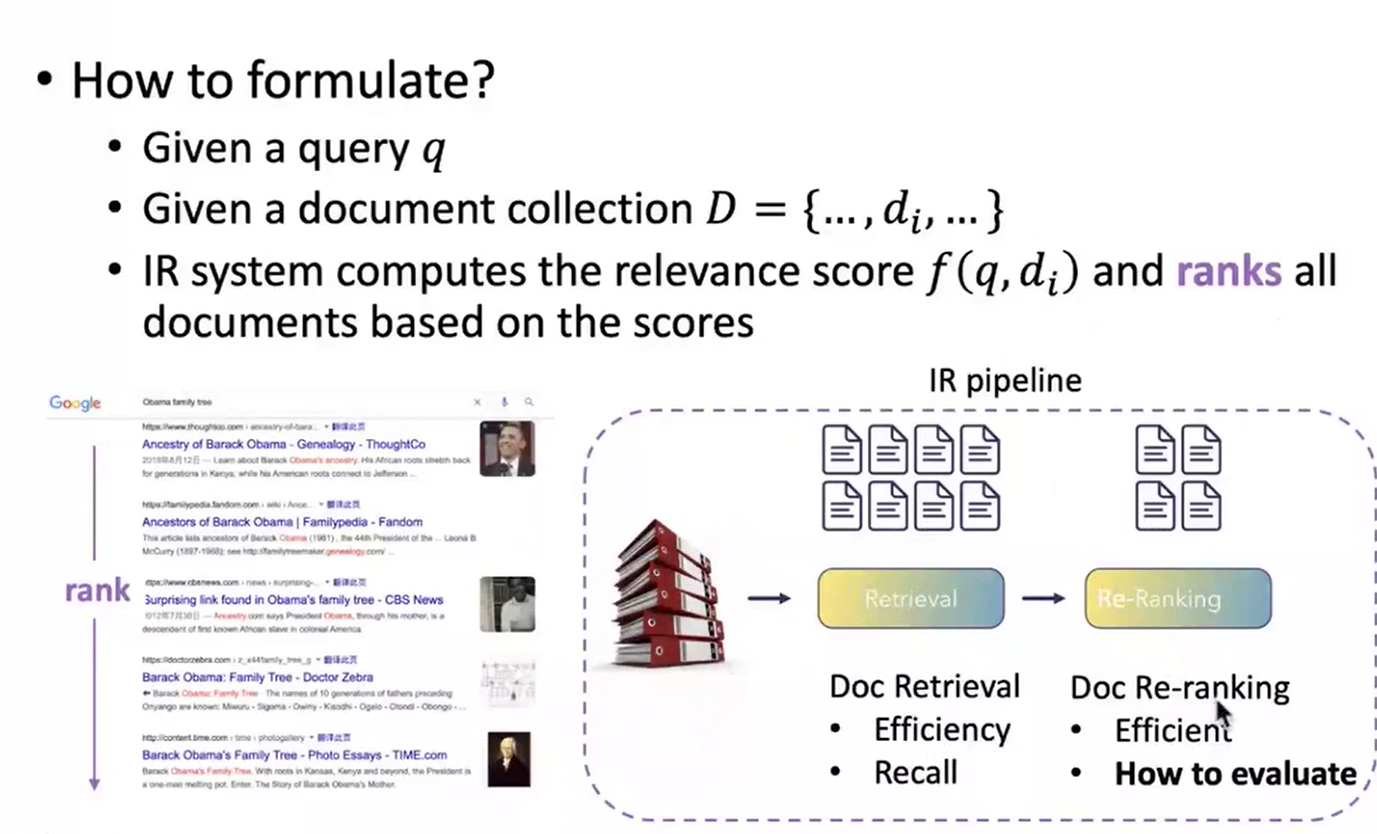
Evaluation Metrics
- Widely-used metrics
- MRR@k
- MAP@k
- NDCG@k
- Traditional IR
- BM25(Best Matching 25)
- TF(term frequency)
- IDF(Inverse Document Frequency)
- Neural IR
- Cross-Encoder
- Dual-Encoder
- Advanced research
- Negative-enhanced Fine-tuning
- IR-oriented Pretraining
QA
Machine Reading Comprehension
Open-domain QA
Text Generation
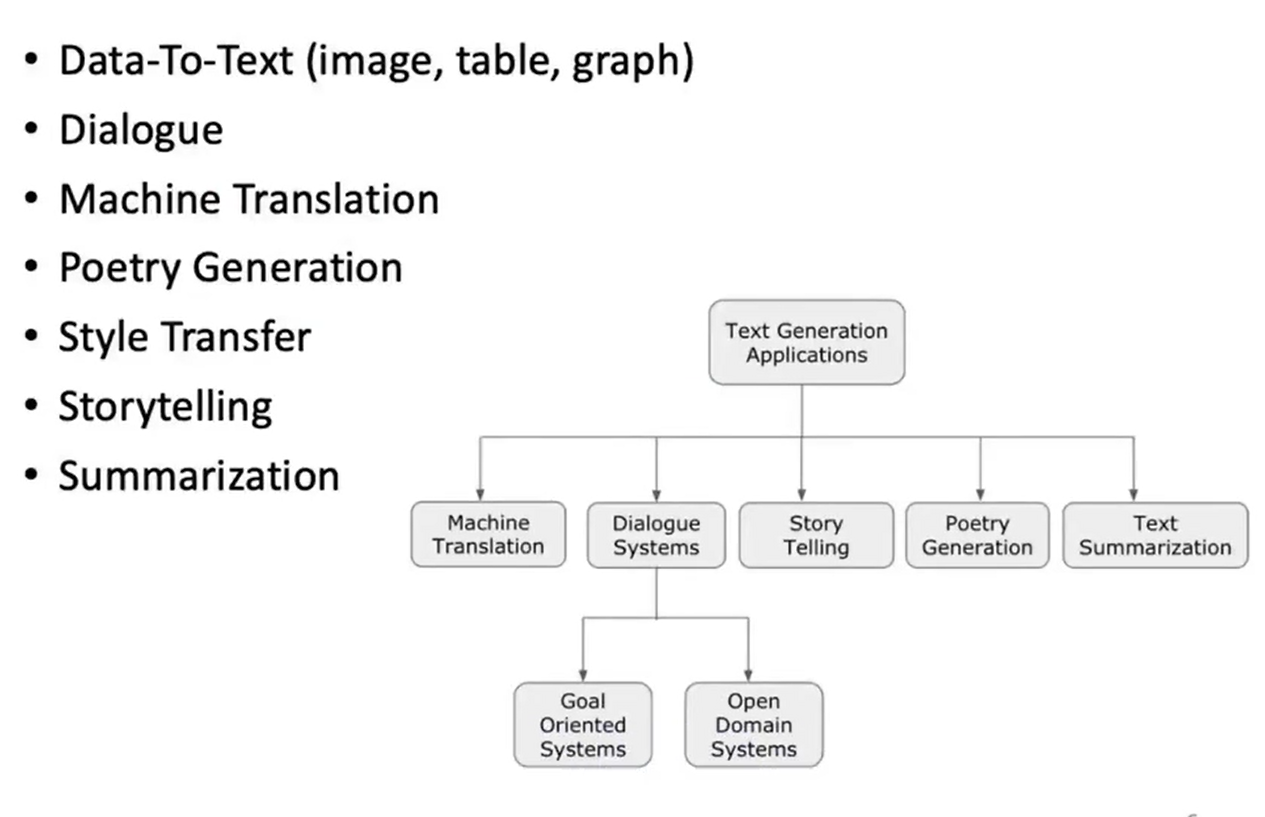
Portry Generation

Medicine
- Entities
- BioNER
- BioNEN
- Relations & Events
- BioRE/RD
- Event Extraction
- Pathways & Hypothesis
- pathway extraction
- literature-based discovery