
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
tags: 数据分析 —-
多分类小记
多元分布是一种离散概率分布,它包含的事件具有确定的分类结果,例如{1,2,3,…,K}中的K。对于这种分类任务,这意味着模型可以预测样本属于每个类别标签的概率。
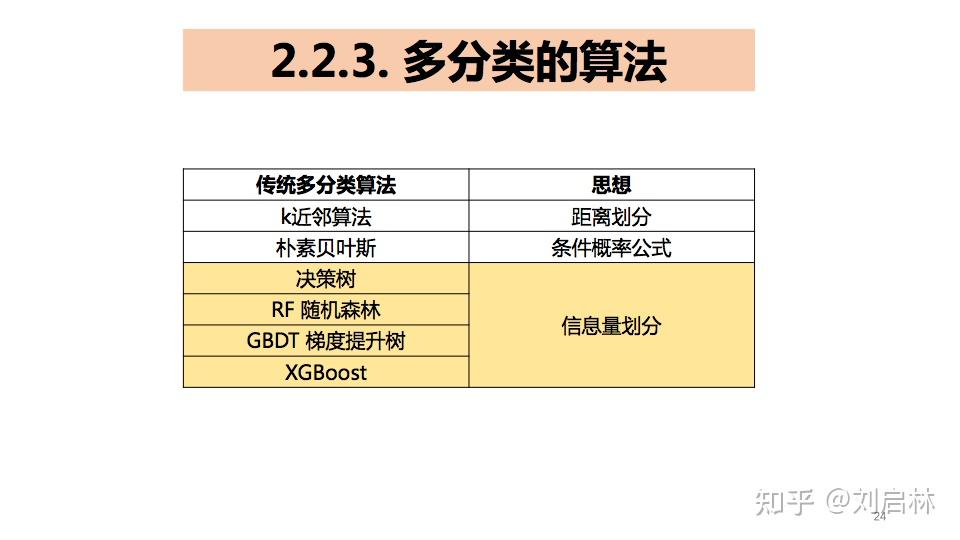
可用于多类分类的流行算法包括:
-
k最近邻算法。
-
决策树。
-
朴素贝叶斯。
-
随机森林。
-
梯度提升。
二分类策略
- OVA
- OVO
- LR
- SVM
用于二分类或多分类的分类算法不能直接用于多标签分类。可以使用标准分类算法的专用版本,即所谓的算法的多标签版本,包括:
-
多标签决策树
-
多标签随机森林
-
多标签梯度增强
Kappa一致性系数
交叉表(混淆矩阵)虽然比较粗糙,却是描述栅格数据随时间的变化以及变化方向的很好的方法。但是交叉表却不能从统计意义上描述变化的程度,需要一种能够测度名义变量变化的统计方法即KAPPA指数——KIA。 kappa系数是一种衡量分类精度的指标。KIA主要应用于比较分析两幅地图或图像的差异性是“偶然”因素还是“必然”因素所引起的,还经常用于检查卫星影像分类对于真实地物判断的正确性程度。KIA是能够计算整体一致性和分类一致性的指数。
以小麦为例
绍如何通过XGBoost解决多分类问题。已知小麦种子数据集包含7个特征,分别为面积、周长、紧凑度、籽粒长度、籽粒宽度、不对称系数、籽粒腹沟长度,且均为连续型特征,以及小麦类别字段,共有3个类别,分别用1、2、3表示。加载该数据并进行特征处理,代码如下:
import pandas as pd
import numpy as np
import xgboost as xgb
data = pd.read_csv("input/seeds_dataset.txt", header=None, sep='\s+', converters={7: lambda x:int(x)-1})
data.rename(columns={7:'label'}, inplace=True)
data.head()
为便于后续处理,将最后一个类别字段作为label字段,因为label的取值需在0到num_class-1范围内,因此需对类别字段进行处理(数据集中的3个类别取值分别为1~3),这里直接减1即可。
可以看到,数据集共包含8列,其中前7列为特征列,最后1列为label列,和数据集描述相符。除label列外,剩余特征没有指定列名,所以pandas自动以数字索引作为列名。下面对数据集进行划分(训练集和测试集的划分比例为4:1),并指定label字段生成XGBoost中的DMatrix数据结构,代码如下:
mask = np.random.rand(len(data)) < 0.8
train = data[mask]
test = data[~mask]
xgb_train = xgb.DMatrix(train.iloc[:,:6], label=train.label)
xgb_test = xgb.DMatrix(test.iloc[:,:6], label=test.label)
params = {
'objective':'multi:softmax',
'eta':0.1,
'max_depth':5,
'num_class':3
}
watchlist = [(xgb_train, "train"), (xgb_test, "test")]
num_round = 10
bst = xgb.train(params, xgb_train, num_round, watchlist)
pred = bst.predict(xgb_test)
error_rate = np.sum(pred != test.label) / test.shape[0]
print(error_rate)
params["objective"] = "multi:softprob"
bst = xgb.train(params, xgb_train, num_round, watchlist)
pred_prop = bst.predict(xgb_test)
pred_label = np.argmax(pred_prop, axis=1)
error_rate = np.sum(pred_label != test.label) / test.shape[0]
print('测试集错误率(softprob):{}'.format(error_rate))